Sabitlenmiş Tweet
g_dalice
1.5K posts


g_dalice
@g_dalice
$SELFIE meme coin 全面擁抱土狗 全面擁抱迷因 全面擁抱文化
discord private Katılım Temmuz 2022
2.6K Takip Edilen451 Takipçiler
g_dalice retweetledi

g_dalice retweetledi

回顾2025年半导体市场,真的是有太多太多精彩的故事,最大的主题就是:
AI需求驱动导致半导体基建的估值体系重构 + 产业链的价值分配重写
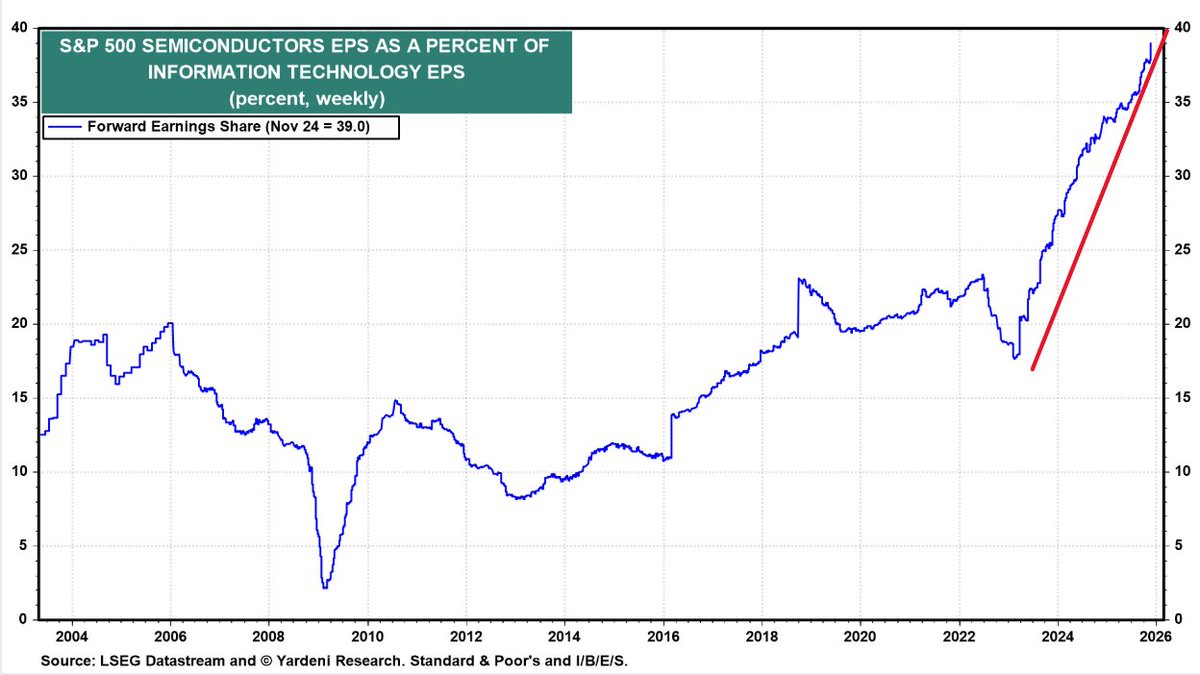
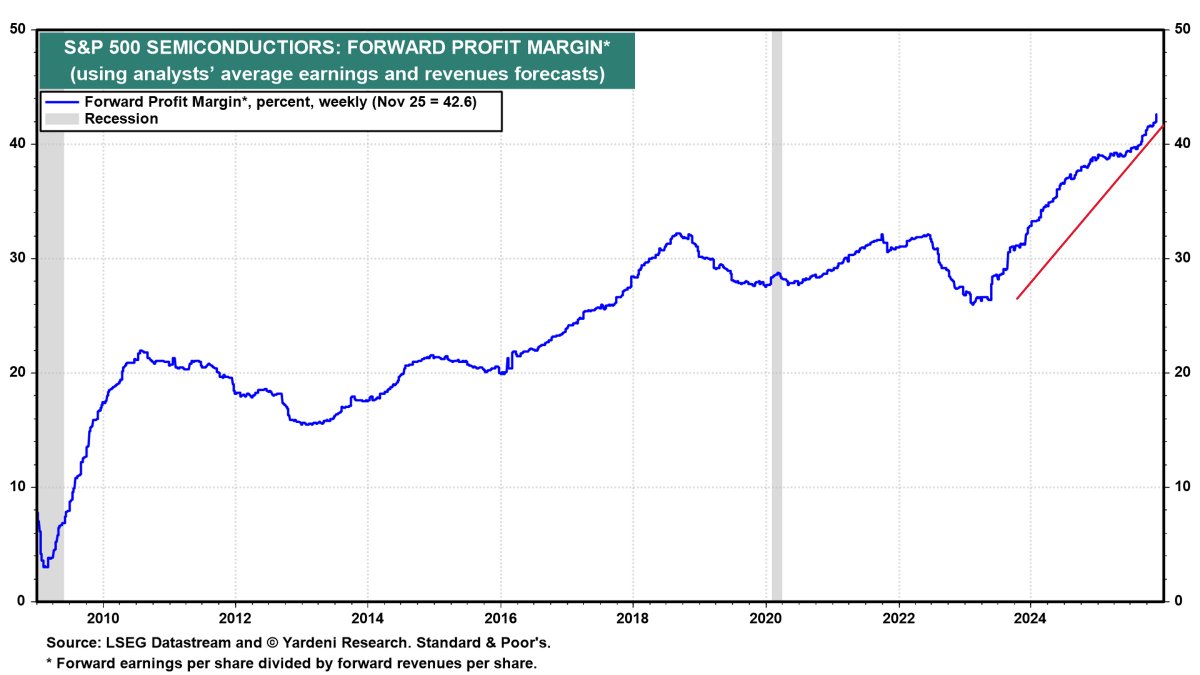
从2024年开始,半导体基建正在飞速吞噬整个IT产业利润,SP500里半导体净利润EPS在IT行业里占比,在两年时间从不到20%上升了到了40%,而且还在呈加速上升姿态
半导体整体前瞻利润率从2023年的25%已经升到了2025年11月的43%,已经明显超过了几个互联网巨头的平均利润率,这也印证了半导体利润率超过互联网会是新常态。整个IT产业的利润分配,流向半导体的比例越来越大。
要知道,就算是20~22年的半导体芯片荒,短缺如此严重,半导体的利润率和整个IT利润分配也没有显著增长
这就是故事的上半篇:AI需求驱动导致半导体基建的估值体系重构,不再是互联网时期的基建从属地位
------------------------
这个现象背后的逻辑是商业模式随着技术特性的变迁:
互联网时代,每次请求的网络和算力成本,边际成本极低,scaling的效果极好,分发的边际成本几乎为零
在AI时代,这个互联网时代分发边际成本几乎为零利于scalable的特性遭遇了根本性的重大挑战:且不说训练成本从此不是一次性开销而是年年增长,就客户的AI推理请求而言,由于inference scaling成为共识,加上垂直领域仍然需要更大规模的旗舰模型来保持竞争力,推理的成本不会随着硬件算力价格的通缩而同步降低
互联网企业从前的最大成本只有OPEX尤其是SDE人工成本,而现在,互联网公司历史上第一次像半导体厂foundry那样背上高折旧成本的资产负债表,商业模型恨不得要慢慢从“流量 × 转化率”部分转向“每 token 毛利”了
简单的说,互联网时代到AI时代的成本分布,在人力成本opex的基础上又加上了沉重的硬件/算力成本capex(财报里占比:MSFT 33%, Meta 38%)。
上个时代的互联网公司+CSP+SAAS是收租行业里的大赢家,而AI时代,算力(半导体/芯片折旧)成为了新的收租行业,整个IT行业的利润分布发生了剧烈的重新分配(EPS利润流向半导体从20%升到40%而且持续攀升中),这就是半导体基建估值体系重构最重要的原因
---------------
半导体高利润率的新常态趋势能持续多久?
目前的高溢价来自于前期不计成本的军备竞赛造成的半导体订单积压过多
但很显然,hyperscalers都不愿意当冤大头,都在试图自建ASIC降低成本,那么可以从2030年远期的算力分布来回看这个问题
长线来看,openai已经明牌了标准答案,10GW Nvidia,10GW ASIC,6GW AMD,其他hyperscaler划分比例有类似考虑
比如说,推理端希望ASIC >50%,GPU里再细分的话,AMD和NV(legacy)对半分。训练还是得NV占大头,60%+,剩下的自研ASIC和AMD对半分
2030年按60%推理,40%训练比例划分,算下来NV 38%, ASIC 39%, AMD 23%,跟openAI比例是几乎完全一致的,算是一个标准答案参考值
当然了,微软,Amazon,Google,Anthropic这几家里AMD的比例会比这个标准答案中枢/参考值明显低一些,xAI则是没有ASIC只有Nvidia+少量AMD
AMD的风险在于,当2030年再往后的更长期,CSP的in house ASIC越来越成熟(微软除外),推理端ASIC占比可能越来越高,很难有incentive新买入大量GPU了,除非卖的足够便宜
最近风头正劲的TPU呢?Meta是不是要转向TPU?对Nvidia的利润率影响大吗?
实际上,Meta今年capex72B,明年capex110B,未来六年capex平均值可能达到160B附近,而Meta 6年10B的TPU订单算下来年均只有1.6B,而且购买的是TPU云服务,并不是裸TPU
也就是说,Meta这笔TPU订单只占到Meta未来6年capex的1%,并没有严肃的考虑大规模部署,可能只是作为和Nvidia讨价还价的手段而已
另外从Meta最近几个月的招聘广告来看,也并没有看到任何TPU engineer方面的招聘,不像
Anthropic那样从五月就招一堆TPU kernel engineer,十月才宣布大规模采购TPU做训练
所以说,不管原因是diversify供货商,还是给自研ASIC延迟做退路,还是因为AMD的MI350X延迟,Meta买TPU基本上只有一个考虑:增加买Nvidia GPU的议价权,但顶多只有推理份额里能讨价还价,实际效果很有限,对Nvidia利润率影响也很有限。
要知道,22年加密货币熊市矿难的时候,NVDA库存上升到了198天,利润率只是从65%回撤到了56%,算上PE/宏观双杀股价才从300变100,现在一直供不应求,利润率没道理能降下来
再加上TPU v8设计过于保守(没用HBM4),Kyber rack的Rubin方案会比TPU v8的TCO更好,到头来最后还是得继续依赖Nvidia,很难议价。只要Nvidia继续保持这样的大踏步前进,竞争对手其实要跟上还是不容易的。
总之,一方面,全产业链瓶颈,比如cowos扩张都很谨慎,供不应求的状态还能持续多年。
另一方面,AI变现的利润曲线和硬件投入曲线存在“时间错配”,应用端的增长曲线会落后几年,只要这个应用端和基建端的增长曲线的时间错位依旧存在,半导体在IT行业的利润分配就会一直占优势。
从OpenAI的到2030年的投入曲线来看,这个时间错位至少要持续到2030年附近。也就是说半导体行业的超级扩张期带来的在IT产业利润划分的主导地位,目前看至少能持续到2030年
而半导体高利润率可能会维持的更长远一些,因为从互联网时代一次性基建属性变成了现在的收租基建属性
---------------------------------------------------
AI 不是只养活了 GPU,而是在用算力预算把“能把电变成 token 的每一环”都抬了一轮,从内存,存储,互联,光纤,电力,储能…..等等
上半篇讲完了“半导体吞噬IT利润”,那么下半篇讲的就是“AI算力价值溢出效应(Spillover Effect)重塑半导体内部格局”:GPU算力增长 -> 内存/存储/互联/CPU瓶颈 -> 溢出效应 -> 结构性机会
2025 年更有趣的故事,是巨大的行业红利在半导体内部怎么诞生结构性新机会,比如说,一个super cluster需要几个数据中心互联,光纤互联的长度需要上百万mile这个级别,这就是新机会
半导体产业链的结构性趋势带来的新机会,最典型的例子就是内存(DRAM/HBM)和存储(SSD),HBM的需求增长太夸张,连带挤压DDR4/5产能,直接让以周期性为标志的内存行业甚至喊出了“周期不存在”了,Hynix因为在HBM上领先,甚至都开始憧憬起了几年后年利润1000亿美元,妥妥一个万亿市值的公司
这两个板块背后,是结构性趋势的转变:AI workload从训练逐渐往推理延申,推理比例越来越大。
而推理是一个非常纯粹的吃内存带宽速度(memory bound)的事情,可以说带宽速度=token/s。模型尺寸越来越大,以及上下文context length的增加,对内存的尺寸要求也相应增大,导致了内存的需求激增:推理即内存
下一代的的GPU/ASIC内存已经成了暴力美学,配备的内存size之巨大,是三年前无法想象的,回看22年H100的80GB简直像个玩具,这才几年就增长了十倍:
Nvidia Ultra Rubin - 1024GB HBM
Qualcomm AI200 - 768GB LPDDR
AMD MI400x - 432GB HBM
内存的另外一个潜在的爆发点在端侧,也就是手机/PC/汽车/机器人的端侧LLM,这两年主流的手机旗舰机已经从6GB升级到了8GB/12GB/16GB,提前为可能的端侧LLM生态做准备,毕竟手机算力下一代就能达到150TOPS量级,妥妥的桌面级,非常暴力
潜力上来说,端侧内存升级是比云端内存增量要更大的市场,毕竟端侧终端device的数量太惊人了,每年都是billion级别,一旦端侧LLM生态繁荣起来,内存用量翻倍轻而易举,针对端侧低功耗内存/存算一体的各种设计都会跟上
但端侧genAI的软件生态,似乎明显滞后,一直比我想象的进度要慢,可能是因为这方面还处于摸索期,并没有云端那么确定的ROI,厂商们在投入上都很谨慎,我在23~24年时候看好27年,可能还是太乐观了
互联网->移动互联网用了10~15年,端侧genAI/LLM可能也需要7~10年,可能得等云端ROI开发的差不多了,边际收益下降了,才能轮得到端侧genAI/LLM拿到开发资源,跑通端侧ROI。
--------------------------------------
另一个2025年半导体内部结构性转变的故事是NAND存储,特别是企业级eSSD硬盘
结构性趋势来源也是同一个,AI workload的推理需求越来越大。内存红利也外溢到了SSD存储,甚至HDD存储,因为内存不够用就用高速SSD作为多级缓存
主要逻辑是AI推理过程中内存溢出KV cache offloading到下一层SSD存储,以及向量数据库检索/indexing,都在增加SSD存储的需求
Micron财报说的精准又直白:“AI inference use cases such as KV cache tiering and vector database search and indexing, are driving demand for performance storage.”
至于为什么存储价格在第四季度才爆发,这需要区分一下合约价格和现货价格,合约价格涨幅会温和一些,就算是最紧缺的企业级eSSD合约Q4上涨大概25%。而当NAND产能在2025年被合约慢慢的吃光,现货的价格就造成了观感上强烈的冲击,一个月上涨50%以上。
另一个未经验证的逻辑是多模态的爆发,特别是AI图片和AI视频的需求爆发,也会加剧存储的短缺,我觉得这条线只能说未来可期,但目前的视频/图片精细程度,可能还不到当年GPT3的水平,要达到出圈效果还需要一些时日。
------------------------
那么下一步还有什么趋势转移带来的半导体结构性的机会呢
那么就要先看下一步AI推理端的需求趋势是什么,毫无疑问,agentic flow的比例会越来越大,2025并不是year of agent,而是一个decade of agent
从CPU视角去看agentic workload,routing和工具处理都在CPU上,如果把常用的agentic框架做profiling,比如SWE-Agent, LangChain, Toolformer,CPU最长可以占到90%的E2E端到端延迟,throughput瓶颈也更多的卡在CPU,甚至CPU能耗也超过了总能耗的40%
Agentic AI目前是一个CPU瓶颈更多的事情,在 agentic 框架里,CPU 是永远在忙的总指挥orchestrator, 很可能会成就CPU需求的新一波回暖
AMD 2025年Q2财报(8月5日),Lisa Su明确表述了这一现象:"In particular, adoption of agentic AI is creating additional demand for general-purpose compute infrastructure, as customers quickly realize that each token generated by a GPU triggers multiple CPU-intensive tasks."
"agent AI的采用正在对通用计算基础架构产生额外的需求,因为客户很快就意识到GPU产生的每个令牌都会触发多个CPU密集型任务。"
Q3 财报里Lisa又明牌了一次CPU TAM increasing due to Gen AI. "Many customers are now planning substantially larger CPU build outs over the coming quarters to support increased demands from AI, serving as a powerful new catalyst for our server business."
Nvidia也是把agent flow视为CPU需求,GB200/300 架构配置的CPU比例也比以往大的多,36颗 Grace CPU : 72颗 Blackwell GPU,直接达到了1:2的水平,AMD的路线则是用1~4个256核的EPYC去服务MI400系列72~128个GPU
以后的硬件架构,一定会往优化agent workload方向发展,比如agent task graph的调度和load balancing,CPU/GPU协同micro-batching
算力上的比较,说不定以后也会摆脱现在的纯GPU token rate比较,转向整个系统级全栈agentic benchmark比较.
--------------------------
半导体结构性转变带来的机会同时,下一步,可能也会带来一些意想不到的次生效应
云端AI数据中心需求爆发,造成内存和存储的暴涨,给消费电子的成本带来了很大压力,在2026年,这也许会演变成消费电子产业潜在的黑天鹅
PC厂商最近的股票大跌,也是这个原因。HP已经说了要减少内存配置,暗示要把PC重回8GB内存+256GB存储的时代了。
DRAM内存和存储再这么涨下去,可能会出现很离谱的情况:内存/存储现货价格比CPU和GPU还要更贵。尴尬的是,这可能直接延缓了消费电子期望的AI PC的进程,毕竟大内存是更有利AI PC的表现力的。
夸张的说,每个PC厂商和手机厂商的员工,甚至是消费电子厂商的员工,都应该买入存储和内存,作为职业风险对冲
明年年初开始,安卓阵营的内存以及存储成本要压不住了,三星,小米的手机售价都提高的话(美国市场现在已经提高不少了),利好最大的就是苹果
苹果的内存产能,nand产能都是专属长约锁价特供的,顺带还把Kioxia给坑了好多不涨价产能,导致苹果的成本优势进一步扩大,苹果全球手机销量市占率增长可能会非常可观,接下来一阵子可能会是iphone辉煌的时光。
-----------------------
2025年半导体市场真的是太多精彩的故事了,Nvidia/AMD/TPU和各家hyperscaler的恩怨情仇引得各路下注的吃瓜群众心情跌宕起伏。
HBM/内存厂商吃到了memory-bound的红利,NAND厂商意外收获了KV cache的溢出效应,CPU在沉寂近十年后,可能会因agent orchestration再次回到增长叙事的中心
不再是Nvidia/AVGO几家算力厂商独大,而是AI workload算力价值溢出后的每一次演进,从训练到推理,从文本到多模态,从单模型调用到agentic flow,都在重写产业链的价值分配。
云端AI的繁荣正在挤压消费电子的生存空间——当PC厂商被迫讨论重回8GB时代,苹果却因供应链优势坐收渔利。这场算力军备竞赛的次生效应,可能在2026年以意想不到的方式重塑整个消费电子格局
半导体的故事不再是一条单线,而是一张持续自我重构的网。而 2025 年,大概只是合纵连横的第一回合
fin@fi56622380
芯片只有AI火热,半导体的2024年基本延续了2023这个基调 只要蹭上AI相关的叙事,股价增长表现都是接近翻倍或者更高,毕竟这是确定性的增长机会,PE都会给的很有想象力 蹭AI失败典型就是高通,微软的recall功能跳票,导致AIPC/端侧LLM叙事直接破产,股价高点下跌不少,就算赢了跟ARM的官司也无济于事 微软跳票+苹果apple intelligence乏力+安卓碎片化,今年端侧AI/LLM只能这么评价:存在感基本为零 端侧LLM功能开发是heavy lifting,即便端侧算力完全达标了(手机端NPU算力去年已经75TOPs了,非常暴力,标准的桌面级,两年内到150Tops问题不大),端侧LLM生态也还没有那么快,还需要SDE们的持续爆肝。我还是和一年前观点类似,看好26~27年才会有比较显著的进展和丰富一些的玩法 端侧AI目前唯一的热点就是智能眼镜,Meta的Rayban眼镜只是个原型,AI功能实用性基本可以忽略,也卖了两百万,整个智能眼镜市场全年接近四百万销量,风头超出了所有人的预期,PMF得到了验证 虽然目前的智能AI眼镜跟LLM半点关系都没有。24~25年主要的端侧AI部分就是眼球追踪和手势追踪,顶多加上OCR,毕竟眼镜只有那么一点点算力,功耗要求也过于严格(<1w)比手机低了一个数量级 下周的CES在端侧AI基本上就是AI眼镜主题秀,说百镜大战可能有点夸张,但差不多就是这个热度,是典型的Hype没错,但未来可期也是真的 -------------------------------------------- 另一个蹭AI失败的Micron,则是因为PC和手机端的DRAM需求比预期疲软,股价涨了一阵跌回原地。毕竟PC和手机端内存是大头,HBM的占比暂时还是太低了,难以撑起AI叙事,7倍的forward PE低的令人发指 AMD是个例外,蹭上了AI竟然还是跌的,2025的PE也低到竟然只有17。各家CSP都热衷于自研model->compiler->asic accelerator从上到下一整套解决方案提高performance,ASIC赛道的火热,让AMD和Nvidia在同一个赛道火拼,只能说CUDA积累的生态优势恐怖如斯 ------------------------------ 蹭AI姿势最成功的,莫过于给各家互联网云厂CSP们做ASIC AI加速器的Broadcom和Marvell,都是直接靠画饼就能翻倍,太可怕了(以及即将蹭上的MTK/AICHIP) 这大概是2024年最大的的芯片风口转型故事 其实帮互联网公司做ASIC AI加速器对于传统半导体厂商并不是特别有挑战性的事情,对IP的要求并不高,主要是做SoC的infra从前端到后端整个配套设施,核心core ML加速器+上层compiler都是互联网公司自己做。 只要服务态度好,客户支持到位,要求什么就给什么,价格合理,门槛并不是那么高。除了互联interconnect IP,基本上可替代性比较高 所以MTK这种云端NPU经验并不多的芯片厂,也能当Google TPU V7之一的供应商 大公司deploy自己的model时,现在都喜欢用自己的asic配套自己的compiler,自己做的asic明明在纸面功耗比上(TOPs per watt)比H100差了不少,甚至能到40%,要花大力气用自家的功耗比并不是那么好的asic,表面上来看并不合算,除了控制成本(和NV讨价还价),为什么还要自己做? 简单的说,各种深度学习model/workload的瓶颈都不一样,很难有通用的解法,卖家标称的纸面性能/功耗比,并不能代表实际日常的实际表现 公司即便是把H100拿过来用,不经调试直接跑自己的model,其实根本跑不到Nvidia标称的性能performance,差距非常明显 如果要跑出理想的performance,要去研究model怎么适配CUDA做优化,甚至需要改compiler里面的一些参数,所以即便是Nvidia,也会派人给大客户针对他们的workload去optimize/tune CUDA/compiler层 而如果大公司比如meta用自家的model/compiler和hw全套,特定的workload会比其他家的ASIC比如高通的AI100 性能要高数倍 因为自家的模型运算细节自己都了解,可以针对自己的model改compiler和芯片,model的size等各种参数达到最好的效果,从内存分配逻辑,kernel tuning,数据精度,tiling,流水线pipeline结构去从硬件的角度迎合上层model的优化,性能差距会非常大,这是一个上层应用决定硬件形状的时代 如果meta用高通的SDK+compiler+ASIC全套,没有办法针对自己的model去优化,只能用高通的东西去sweep各种参数,这里说的sweep意思是高通的SDK和编译器允许用户调整一些参数(例如线程块大小、内存分配策略、流水线深度等)来优化特定operator的性能。用户会尝试不同参数组合,以找到性能的sweet spot 而sweep参数获得的性能优化会比较有限 这就是为什么最后大公司比如meta的model运行在高通的asic上面的performance,反而会不如自己家看起来功耗比更差的全套compiler+ASIC ----------- 为啥CSP们要自己做芯片的同时又外包给传统半导体厂商呢? 一块SoC里大部分IP,包括Cache/memory,CPU,DSP,high speed IO, boot以及低功耗控制,需要的人力是很多的,但只是提供了一个承载ML加速器运行的infra平台,对于互联网厂家来说没有任何自己做的必要,CSP们只会对直接影响ML加速器部分的内容感兴趣 芯片这个圈子太小了,而且前端后端各个角色之间隔行如隔山,挖人不容易,无法在短时间内招到一个磨合良好的团队稳定的迭代项目。Goole/Amazon/Microsoft/Meta这几家开出高出市场价很多的薪水四处挖角,silicon team也都只是几百人到一千人的规模。一般来说从零开始组建一个不错的大厂silicon design house成型,起码要十年时间 所以给成熟的芯片大厂外包做是一个很合理的选择 ------------- 那么CSP们会不会自己做了ASIC然后往外卖和Nvidia竞争呢? 不会,因为这些ASIC组成立的目标KPI就是节约了多少成本,专门做这个生意风险和投入不成正比,芯片支持多个客户的成本是上升很多的,完全没有必要 这也是为什么这些ASIC组在制定架构指标时比较省心,直接对标Nvidia下一代的Tops以及带宽指标就行,同算力功耗多了50%也无所谓,靠后期compiler和针对性架构来弥补,反正只要能节省成本不被Nvidia压榨就行 ----------------------------- ASIC AI加速器故事即便在2025~2026年,其实也还是整个市场占比很小的小众市场,Nvidia仍然是这场LLM科技革命里毫无疑问的基建期唯一大boss 至于openAI/Anthropic能不能像2004年的Google/Facebook一样,成长为这一轮浪潮里的新巨头,那就拭目以待了 2025年的半导体,AI作为主旋律的日子,怕是还会持续。不过其他领域的复苏,比如汽车电子的增长,还是比2024要好看些的 2025除了AI主旋律外最大的看点,就是intel的18A制程量产效果能否如期落地,这可能是2025影响产业格局最大的事件了
中文
g_dalice retweetledi

This is very true
Pendle YT market is often super ineffective since most of the people can't do any research themselves, and look at any numbers
There are so many YTs priced at levels that make no sense.
Pendle YTs are especially good for the smaller guys, since a lot of pools have only a few M$ worth of liquidity in them. So the bigger guys can’t ape them properly.
You can also trade YTs as a normal coin. If you ape early into a pool that people don’t see yet, you can farm leveraged points for free and exit in profits.
I could name a few recent examples:
Kinetiq's kHYPE / vkHYPE crashed after last week's points announcement. You could have aped YTs literally for free and farmed points cheaper than anyone else.
USDAI YTs, if you bought in early, once nobody really paid attention, you would have bought them 3 times cheaper than in peak Mania = Farm leverage points for free and exit in profits
FF YTs, Falcon did surprisingly well, and literally everyone who bought YTs ended up in profits.
There is also the other side, if the project does badly, you can lose a lot.
If you know what you are doing, or follow someone who spends hundreds of hours watching Pendle pools like a degen (me), Pendle can be an amazing edge that most of the CT still has no clue how it works.
CBB@Cbb0fe
If I had 6 figs in crypto, I’d spend hours studying protocols on Pendle YTs are one of the most asymmetric plays: - Whales on Pendle want to lock in fixed yield and don't do extra diligence on farm potential - 2–3x upside on good farms is very doable - Not crowded at all. High slippage on YTs keeps big funds and whales away. YTs are a fast track to 7 figs if well executed If you don’t know what the fuck I’m talking about, go study
English
0x68c150b9827f84939855cc67197119672cbe8764
AI Hero
Dev (02) funded from the official wallet 01 @Four_FORM_
Probably something 🤔
Four@Four_FORM_
Important Update - A Farewell to Ai Hero Heroes, our journey together has been unforgettable. 🫶 Starting tomorrow (15 Oct), Ai Hero will stop issuing new vouchers. Existing heroes can continue playing for the next 14 days until all heroes are used up. After that, the game will officially close on 29 Oct at 23:59hrs. From the very first summon to the final game, the community made Ai Hero what it was. Thank you for every completed battle and every bit of support you’ve given us. 💛 Though this chapter ends, the spirit of Ai Hero will live on in our legacy. The adventure will continue in our hearts. ⚔️ With gratitude, The Ai Hero team
English
g_dalice retweetledi

Solana szn 🟣
It’s officially Solana szn. Perps volume hit a new monthly record with $43.9B traded in August, while TVL continues quietly grinding toward ATHs.
Here’s your quick roundup covering what shipped on Solana last week:
- The U.S. Commerce Department started distributing GDP data on Bitcoin, Ethereum, and Solana, with data feeds powered by @PythNetwork
- Solana's ecosystem TVL + stablecoins issued reached an all-time high of ~$34 billion, up ~200% YoY, according to @tokenterminal
- @Lombard_Finance’s yield bearing Bitcoin (LBTC) arrived on Solana, bringing the $1.5B asset to Solana DeFi
- The Solana Policy Institute (@SolanaInstitute) donated $500,000 to the legal defense of @rstormsf and @alex_pertsev, the developers of Tornado Cash.
- @JupiterExchange launched Jupiter Lend in collaboration with @0xfluid and reached over $750M in deposits in just days from launch
- SIMD-0326: Alpenglow reached quorum for votes and is expected to pass, with ~99% of voting validators voting in favor of the proposal
- @deksxyz introduced their Debit Card powered by Solana
- @chrischang43 rolled out Sandwich Detector v2 for Sandwiched(dot)me, a major step forward in catching malicious actors who profit from extractive sandwich attacks
- @Solanamobile announced that Seeker szn officially kicks off on September 8th
- You can now trade @DriftProtocol perps from Telegram with @solcypherbot
- @lincolnbuidl and team rolled out @TradeInRhythm, a new trading terminal built on Solana
- NASDAQ-listed @MetalphaPro deployed Bitcoin liquidity on Solana through @ZeusNetworkHQ
- @defidevcorp took Solana to Wall Street and rang the NASDAQ bell, marking the first U.S. public company with a Solana-focused treasury strategy. Follow @ReserveSolana for more updates on Solana-focused treasury companies.
- Nigeria explored a partnership with @SuperteamNG to drive crypto education and adoption
- The Solana Foundation introduced Solana Bench, the first standardized, reproducible way to measure how well different popular LLMs like Claude Sonnet and GPT-5 can build and execute Solana transactions. Funding is available to expand this research.
- @GuiBibeau released the Solana Curriculum Repository, an open source curriculum for teaching blockchain and Solana in universities
- @StarAtlas open sourced Star Frame, a framework built on Pinocchio to help @solana_devs build complex, secure, and scalable programs
- @anza_xyz’s Solana validator client Agave hit a burst of 1.1 million TPS in a single-node synthetic test, matching Firedancer’s previous peak. The test used simple transfers and included several unmerged performance upgrades.
- SIMD-180 went live on mainnet, making it so that validator leaders schedules now key off vote account addresses instead of validator identity keys.
- @theprivacycash launched an open source privacy protocol on Solana for transferring SOL
- @vanishtrade announced their $1m pre-seed round led by @Colosseum
What did we miss? Shoutout other folks shipping in the comments below. Rest up and hope you all have a lovely week ahead 🫡

English
g_dalice retweetledi

g_dalice retweetledi

人人都是产品经理 🙌🏻
Devv 现在把 vibe coding 中不知道如何设计 & 不清楚如何描述需求的问题也解决了。
PM Agent 本周上线 🚀

中文
g_dalice retweetledi


g_dalice retweetledi

g_dalice retweetledi

BONK 生态 18 个最优质标的推荐。
#useless 上 100M,BONK 生态会吸引很多流动性,
我调研了 BONK 生态早期几乎所有优质标的,选出来可能还有后续的 18 个标的。
评价纬度主要有:
1)是否被 BONK 官号互动
2)是否被 TOM 互动
3)是否被 Bonkguy 互动
4)官推是否继续运营
5)历史市值是否足够高
6)当前市值是否有二段机会
7)叙事本身是否有后续机会
8)筹码结构相对不离谱
随着 bonk 生态进一步繁荣,这些标的应该会有不错的机会。
---
完整标的已发 TG 频道,请自取。
传送门:t.me/CyptoForest

中文
g_dalice retweetledi

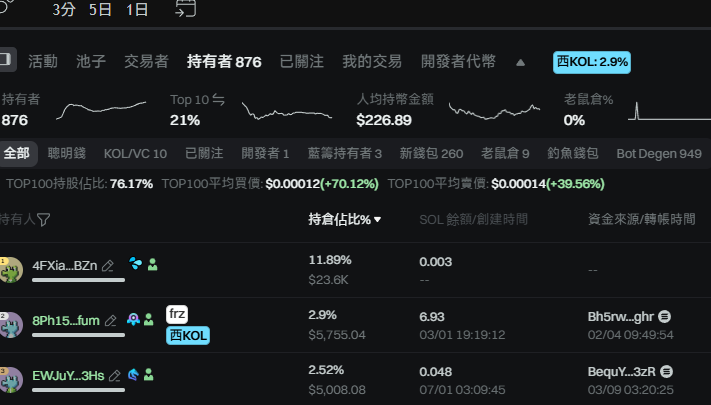
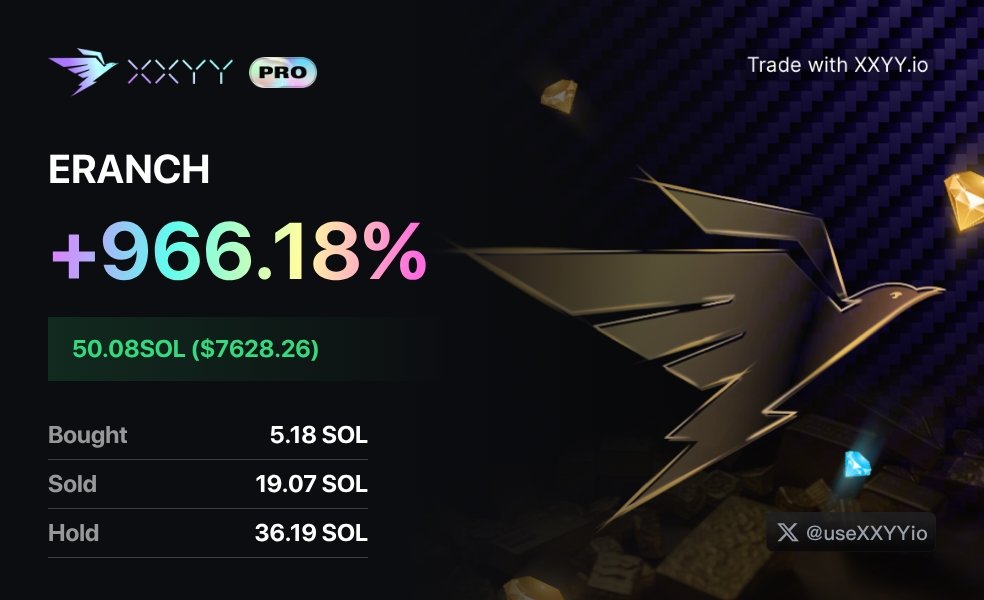
今晚 $ERANCH 66k -> 1.9m
1. 11:46分发现 OP 有一根柱子的大买单
于是我去扒地址,发现买入地址(BS2UYyMLUekNBxa2YrzHAznHAipvjKvKAjggypS7mUin)是一个新地址,这个地址的SOL 资金来源是和OP6月10日第一笔买单的资金来源相同,同时这个地址产生了2个分发,分别是:
CKH8Piwr68T8tYbsHmUGSLm4BZgen7hBJVMu3WqPyD3V
5EjA5TTPE6PUnqBZ1vFPgAhjGmFCA5LYJ2djV9rAteMx
各200s当时我意识到可能是要拉盘 OP,于是提醒几个同样在看的朋友,可能会有 OP 的买单,监控好这三个地址。
2. 观察到5E 开头地址在00:03:16买入新盘81s
我意识到这可能和 OP 这一轮的手法相同,Jeffy 在重复买空所有筹码的操作,于是手动跟单5s。显然这个地址没什么人在跟,进入的价格几乎没有差价,于是我成为了除了jeffy 以外成本最低的几个人。然后跑到Z 群喊大家上车,由于依旧存在可能性他一笔砸掉,所以当时最优策略是之上归零仓搏倍数,并择机出本,很高兴群友也吃了不少。
3. 后续就是大家看到的,第一步的三个地址轮流拉盘,不计成本的买入,CKH8地址也和预期的一样买入 OP, jeffy 沉睡 n 年的小号包括 zerebro 的 dev 账户也在买入,结果就是OP 和 ERANCH 轮番拉升。
可以看到后面的人发现的过程还是比较缓慢,如果你有看我上一篇OP 的记录并对相应地址做跟踪挖掘,你其实也可以在底部吃到这个盘子。勤能补拙,有空就去挖挖地址,一定会有收获。
这个盘子后续只取决于 jeffy 本人的动向,目前和 op 的价差我个人感觉有点小,倾向于是 op 低估。另外,不排除以后还会有大币买入,择机出本并take profit即可,因为总有一笔 sell 完的风险。


中文
g_dalice retweetledi

@TheMisterFrog @Cupseyy @waddles_eth @casino616 @Cented7 Used @frontrunpro to stalk all wallets in the leaderboard. Pretty cool.
Long been thinking about a central database for KOL wallets, since I heard you guys are passing around spreadsheets 💀
(completley unaffiliated)
English
g_dalice retweetledi

g_dalice retweetledi

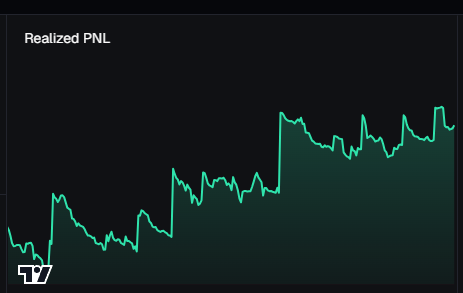
4月回顧
1月底川普發幣後雖然賺了不少但我也發現我打狗其實相當的爛,所以3月份就決定搞了兩個錢包從10S開始,好好磨練磨練,目標成為成為P大將也開始記錄鏈上的日常。希望之後能周周回顧。
4月份一開始老弟我玩得挺差的,不斷在15-25S之間上上下下,是最後月底行情回來,然後認識自己適合的交易方式並認真開始觀察喜歡的錢包才有認知上的提升 然後日漸穩定。另外必須說 @CieloFinance 的錢包總攬真的幫助不小,看了自己錢包發現平均持倉時間紙有15分鐘真的嚇一跳XD 之後馬上就開始有意識的降低購買次數並提升持倉時間。
4月份常見問題:
1. 交易太頻繁
2. 內盤太紙
3. 買幣的挑選門檻要提高
4月最高獲利:
$Okinta 13SOL
$wizard 13SOL
$Gold 7SOL
4月最大虧損:
無過大虧損 - 都是一堆垃圾堆積起來的
補充: axiom真的好用到不行
@gib1000x" target="_blank" rel="nofollow noopener">axiom.trade/@gib1000x


中文