
Murali Manohar
863 posts
Murali Manohar
@gitlostmurali
AI something @AlephAlpha. Post training models. Built agentic chat & evals
Katılım Ağustos 2018
1.7K Takip Edilen174 Takipçiler


Ending this year with a blog on RL environments:
gitlostmurali.com/rl-environments
Talks about reward hacking, sandboxing, curriculum learning, tool calling - all the stuff that can break when you actually try to train agents
English
Murali Manohar retweetledi
RL is cool, but what do you actually need to know about hardware and infra to predict its future? Check out our new piece on tensoreconomics:
English
Here's my blog on Understanding GRPO:
gitlostmurali.com/blog/grpo-intr…
English

First mini-blog on profiling LLMs for inference out, with a next ones on writing fused kernels coming soon!
tanaymehta.com/blog/2025/07/2…
English

I need to find a recommendation for the next Fictional read. Read too many non-fic and now I want some change.
English
Thanks!
huggingface.co/datasets/Jiayi…
It's a countdown task - "Use every given number exactly once to build an equation that hits the target."
As a next step, I wanted the small model to decide if it has to forward the equation or solve on its own. I introduced latency as a negative reward but it didn't work quite well. And then I went to other projects.
English

@gitlostmurali oh wow yeah this looks very similar! nice work! what task is this?
And yeah I noticed this too when I was doing math problems
I defeated how much of the real question to give to the small model
English
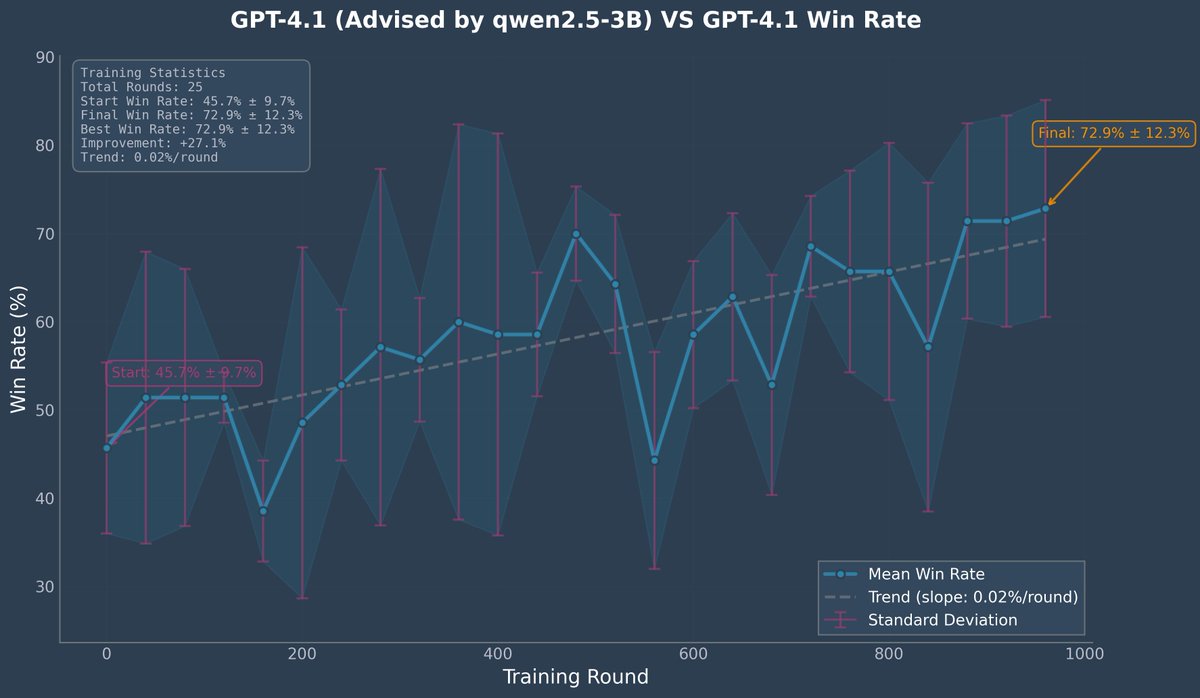
doing this now for my debate framework: gpt4.1 vs gpt4.1 advised by qwen 3B
gpt4.1 w qwens advice debates itself in elo/tournament style to get advantage
advantage is used to grpo qwen to give better advice
you can fine tune api models with rl'd context
Brendan Hogan@brendanh0gan
big models are great agents but often too big, closed, or delicate to fine-tune idea: train a small model to craft context for a frozen big model, score the big model's outputs, use that as reward for the small one grpo for context tuning. more below
English
An interesting thing happened when the remote model is swapped with a bad quality 7B LLM. After failing to get the remote model to provide right equations, the local model started providing hints in its prompt for the remote model. In a few instances, the local model started solving the problem and just passed the equation in remote model's prompt for the remote model to just **forward** the equation.
English
@brendanh0gan Sounds similar to the experiment I tried a few months ago. I tried it with qwen-3b and o3-mini
Spoiler: It works!
github.com/gitlost-murali…

English
later this week I will be releasing the first complete set of answers to PMPP; stay tuned 🤗

English
@rishdotuk Ouch! I like the personality.
Imagine having this as the PR reviewer before one submits it to the team
English
I asked Claude about the vibes of my code, and I got cooked. "I'm following a tutorial but adapting it badly." I should cry myself to sleep. :D

English
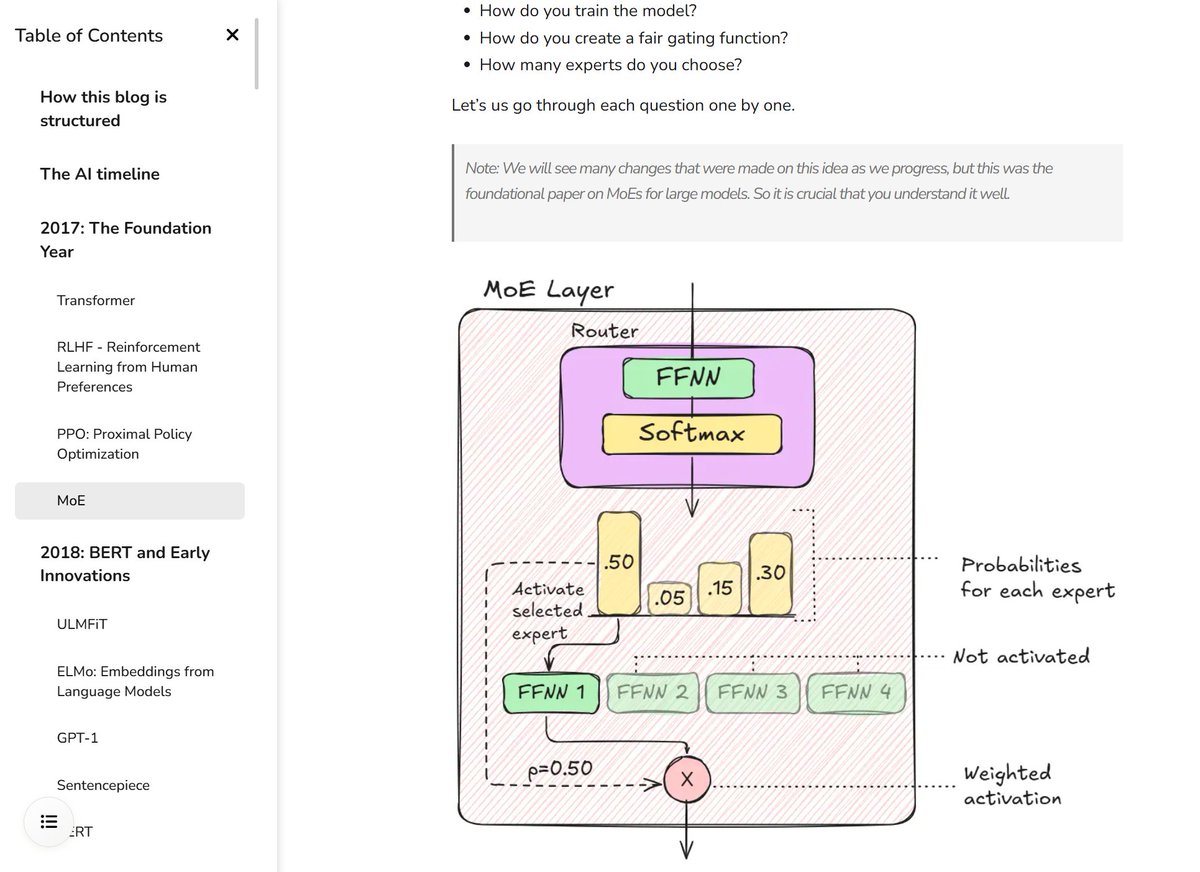
@goyal__pramod Always. Visualizations are rewarded since humans are visual creatures.
To speed this process, you can try these:
1. Claude renders diagrams with Artifacts feature.
2. Try asking AI for mermaid versions and later manually convert to excalidraw or ilk
English

Time spent writing -> 30 min
Time spent creating visualization -> 3 hours
English
@sh_reya @HamelHusain Thank you! I'll follow up over email to discuss the budget and see what can work. Appreciate the flexibility 🙏
Thanks again!
English

@gitlostmurali @HamelHusain What is your corporate learning + development budget? Email Hamel at hh@parlance-labs.com and we will work something out. We do not want cost to be a barrier; we have a steep listed price so we can attract only those who are actually serious about building AI products
English
Given @HamelHusain and @sh_reya 's credibility, I would love to take the evals course. But 2000$ seems like a lot. Even to convince the corporate. What are some best alternatives here?
Hamel Husain@HamelHusain
Early bird discount ends next Friday: maven.com/parlance-labs/…
English
@tanay_mehta @doSwayamExist Ouch. How pathetic!! This incident and intern-shaming Apple's latest paper is deeply concerning. This is classism in a different form.
This can only change if indian teachers/ professors are "okay" with removing Sir/Madam. And how cool is it to say, Prof. Sanyal/Prof. Chawla?!
English
@doSwayamExist Bullying juniors with manner-policing like this is a way for some people to get the high they couldn’t get from actually doing something worthwhile
English

Bro is in 12th and calling a person who is almost 5 years older than him "dude"?
English
Love how Sarvam placed their announcements!!!
Like here's a model we trained to here's a product we built
Sarvam@SarvamAI
Introducing Sarvam Samvaad 🚀 Sarvam Samvaad, our Conversational AI Platform, is designed to help enterprises build, test, and launch AI agents fluent in 11 Indian languages. ▪️Power interactions across telephone, WhatsApp, web, and apps ▪️Handle complex phrases, alphanumerics, and proper nouns with precision ▪️Listen in on every conversation and discover deep insight ▪️Scale your support with pricing built for India Trusted by leading brands across the country, the platform delivers production-ready agents so enterprises can move from pilot to full-scale deployment in just days. It’s time to level up customer experience with Sarvam Samvaad. Watch it in action ↓
English

codex gets access to the internet today! it is off by default and there are complex tradeoffs; people should read about the risks carefully and use when it makes sense.
also, we are making in available in the chatgpt plus tier.
English
The linter is still complaining. Let me try a different approach by adding type ignores
Claude models (3.7 & 4) are ruthless
English
@t_blom I came across folks who said:
"If you find the clients and take care of the tech stuff, you'll be the co-founder". How dependable can a person be!!?
English

“I’ll invest if you find a lead” is the single lamest thing an investor can say.
English
Cursor Code is exactly what I want my cursor to be. Precise edits and incremental.
English