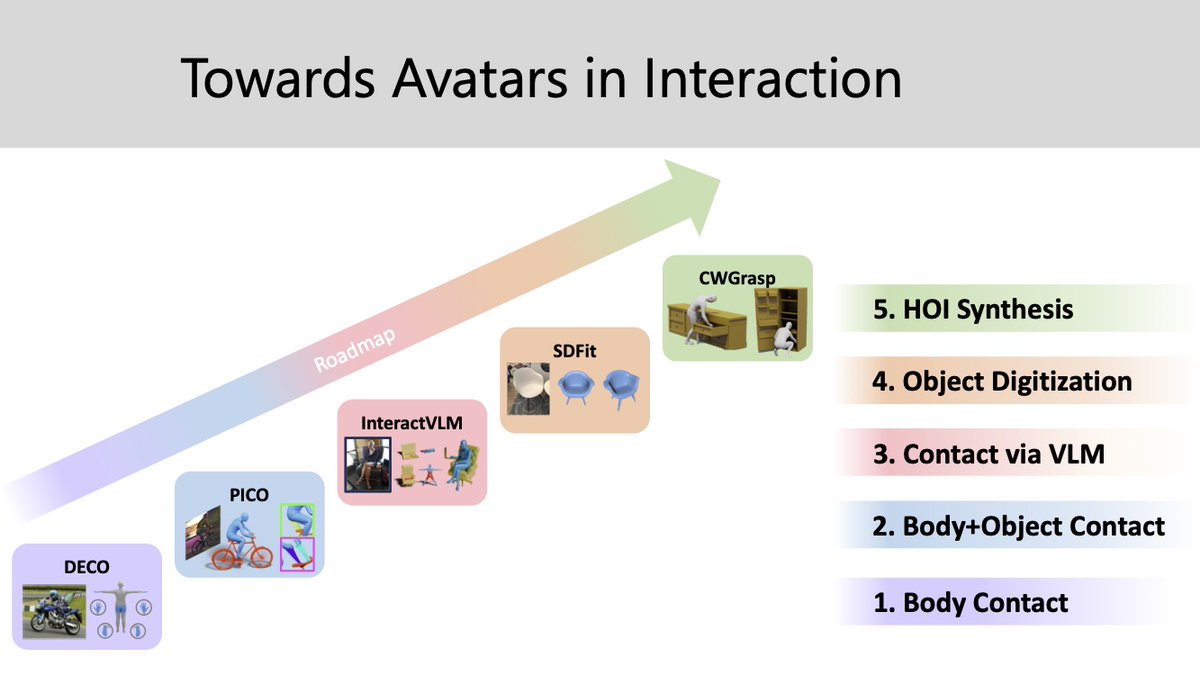
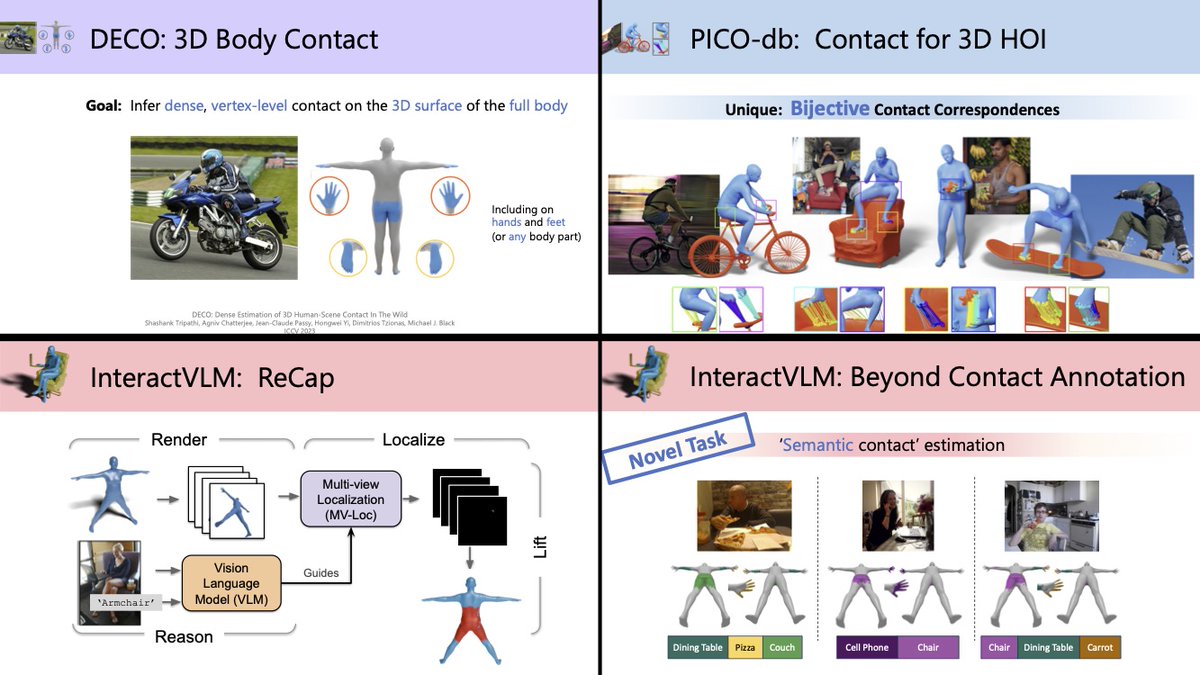
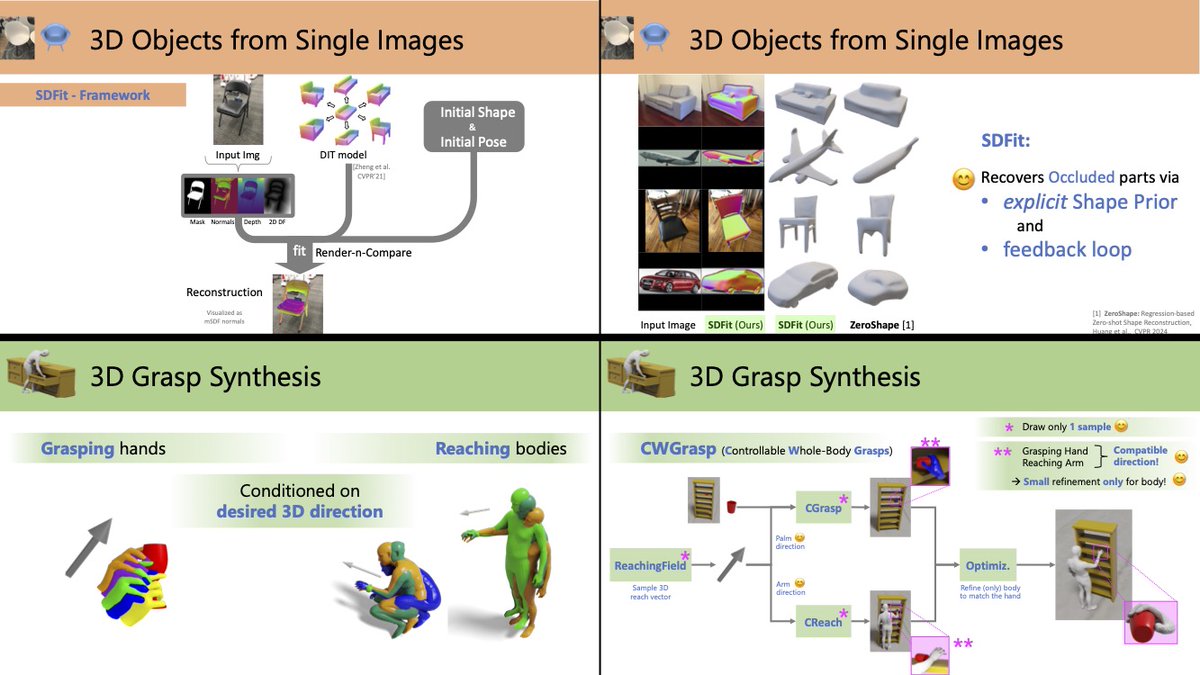
Recovering 3D object pose and shape from a single image is really challenging. SDFit introduces a novel framework that deals successfully with this problem. Congrats to @anticdimi for the amazing work!!!
Dimitrije Antić@anticdimi
Intelligent systems need to understand #3D Objects from single images. However, recent SotA methods work well for unoccluded views & common poses, and prioritize shape over pose. We tackle this by developing #SDFit #ICCV2025 a novel Render-n-Compare framework for 3D objects that: 👉 Is robust to occlusion & uncommon poses 👉 Treats both Shape & Pose as 1st class citizens (1/6🧵)
English