
Gladys Assistant
5.5K posts
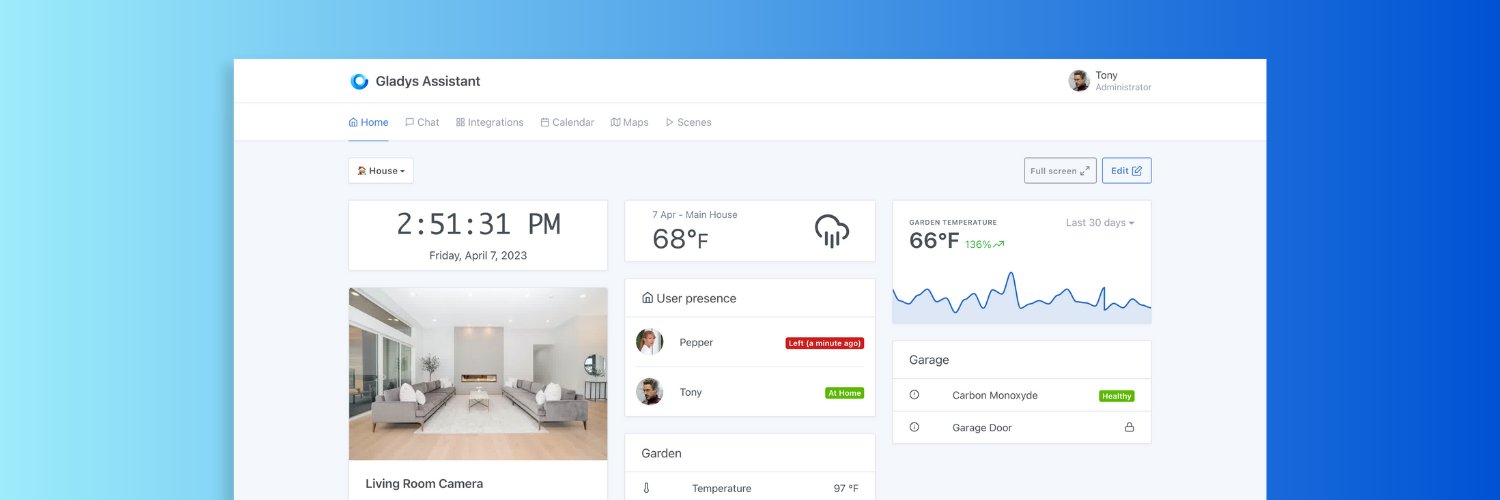
Gladys Assistant
@gladysassistant
A privacy-first, open-source home assistant 🏠
Katılım Şubat 2014
35 Takip Edilen2.6K Takipçiler
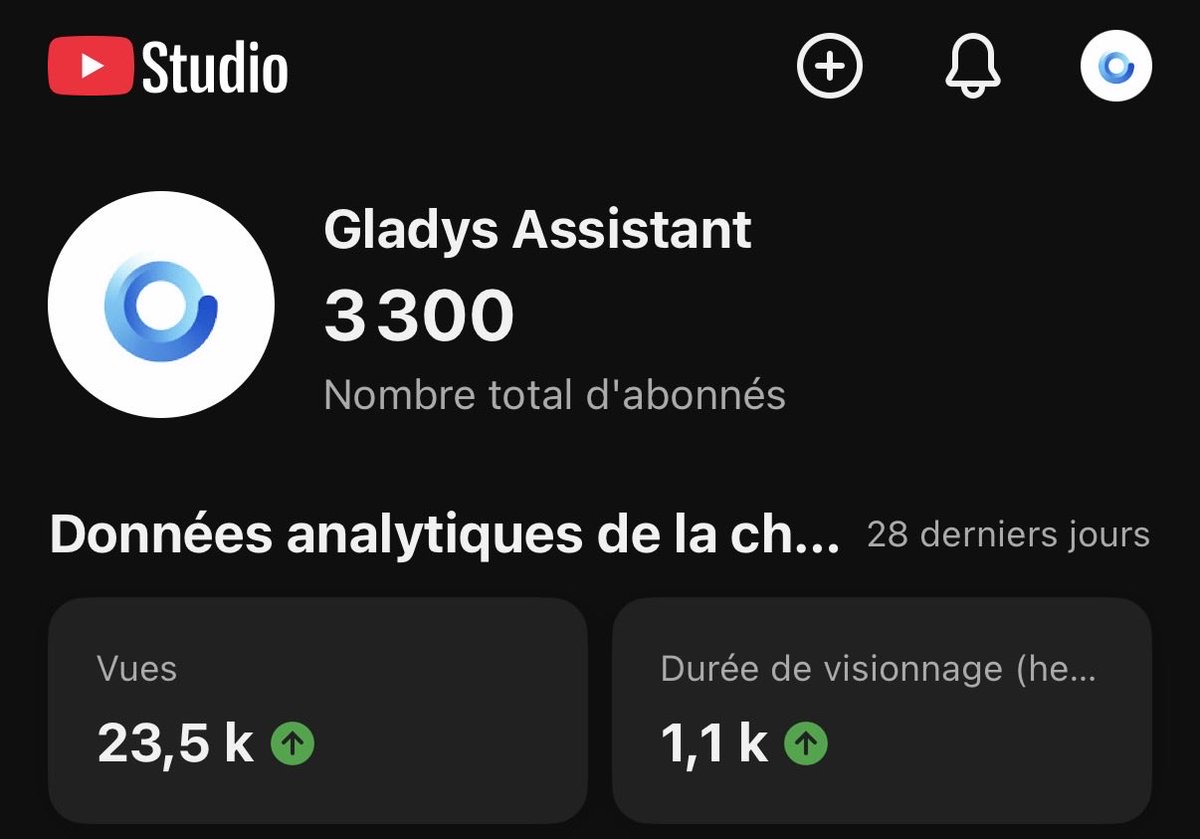
Un des meilleurs démarrage de la chaîne !
Le taux de clic est vraiment super bon 😳
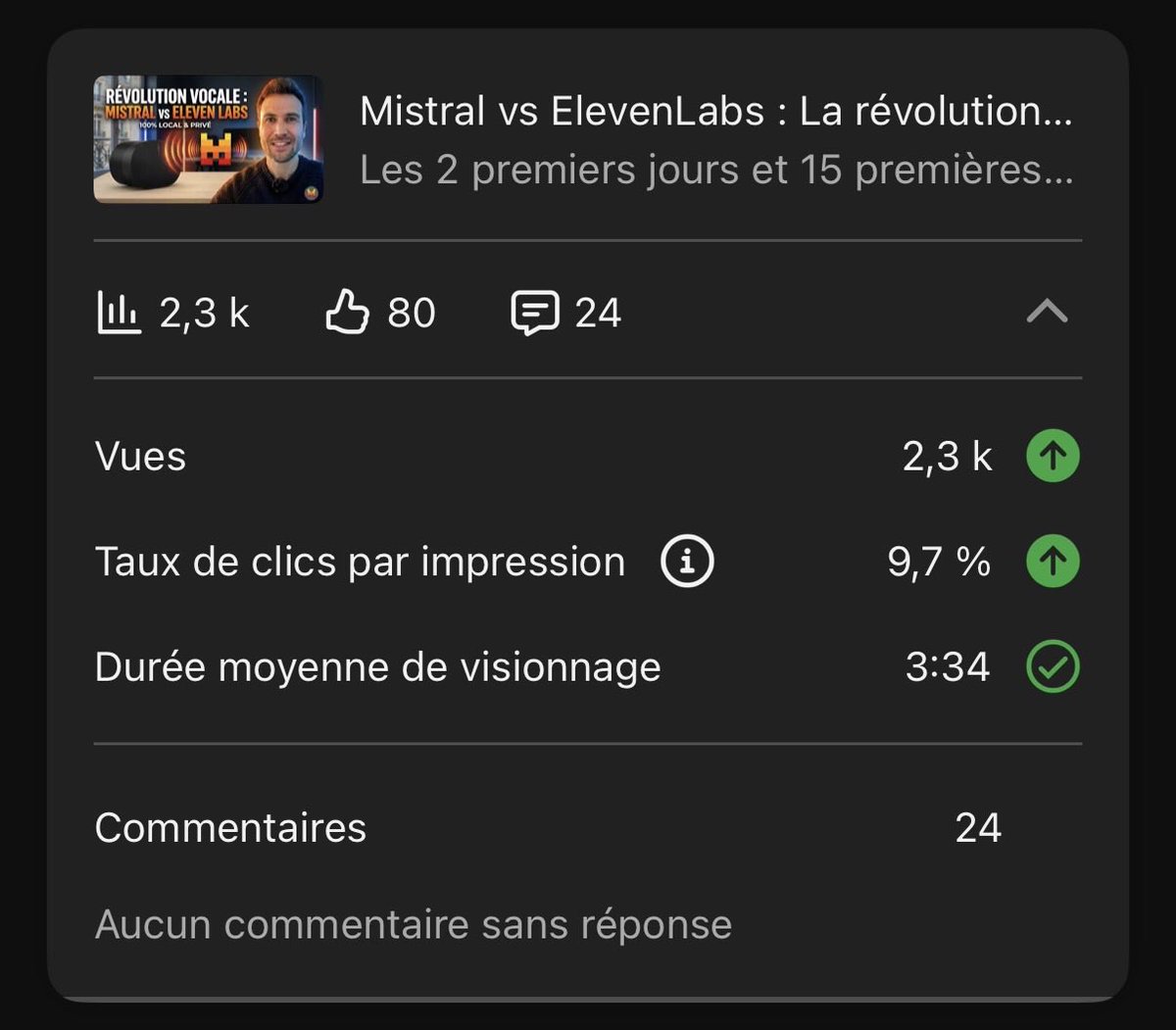
Français

Je ne m'attendais pas à une telle claque en testant Voxtral TTS de @MistralAI 🇫🇷
TTS open-weights, 100% local, et la qualité rivalise avec ElevenLabs.
Démo 👇

Français
Je vous montre toute la config (seuil de puissance, scénario, matériel) dans ma nouvelle vidéo YouTube.
Le tuto complet est ici :
youtu.be/gn-bBBs39G0
YouTube
Français
Résultat ?
📱 Une notification sur mon téléphone.
🗣️ Une annonce vocale dans le salon via Gladys.
Plus besoin de descendre à la buanderie pour rien.
Français
Fini le linge qui stagne 3h dans la machine parce qu'on a oublié de l'étendre. 🧺❌
J'ai automatisé la détection de fin de cycle de mon lave-linge avec @GladysAssistant.
Voici comment j'ai fait (pour moins de 15€) : 👇 🧵

Français
Gladys Assistant 4.71 : Nuki & Matter
community.gladysassistant.com/t/gladys-assis…
English

J’utilise un @elgato Stream Deck depuis des années pour mes lives YouTube.
Et puis je me suis dit : et s’il gérait aussi ma maison ?
Maintenant, quand le soleil se couche, j’allume tout d'un clic sans bouger.
À découvrir ici 👇

Français

@gladysassistant Solid choice for a dev setup! One small tool I'd add: MacQuit — menu bar utility to quit all running apps at once. When you're deep in a dev session with 20 tabs and 10 apps, one click cleans everything up
awesomemacapp.com/app/macquit
English
MacBook Air M5 : Pourquoi je l’ai choisi pour mon Setup Dev 2026 !
youtu.be/lUPBLwvHYO8

YouTube
Français

@Topaz750 Ah mince, même avec les bons volumes Docker ?
Français

@gladysassistant Bon compliqué une image Docker, le benh à besoin de la config hardware, compliqué à rerouter. Tout est opens source avec Skill, MCP et CLI si le coeur t'en dit toujours
Français
L'IA locale progresse vite ! 🧠💻
J'ai installé Ollama sur un Mini-PC pour faire tourner des LLM (Llama 3, Mistral) 100% hors-ligne.
youtu.be/ZhqBSgQCO4o

YouTube
Français

Mieux que ChatGPT ? Avec l'essor des IA locales comme Qwen 3.5, j'ai tenté de lancer un LLM en local sur un Beelink S13 ⬇️
youtube.com/watch?v=ZhqBSg…
YouTube
Français
Gladys Assistant retweetledi
6 months ago, I bought a maxed-out Mac Mini M4 Pro with 64 GB RAM specifically to run local LLMs.
I spent weeks trying models that were too big for my machine.
“This 70B should fit in 64 GB” — technically yes. In practice? 8 tok/s and 45 seconds before the first word appears. Unusable.
I kept downloading, testing, getting disappointed, and moving to the next one. Every time the same question: is this model actually a good fit for MY hardware?
I’m not the only one. Every week on r/LocalLLaMA, someone asks the same thing. The answer is always “it depends.”
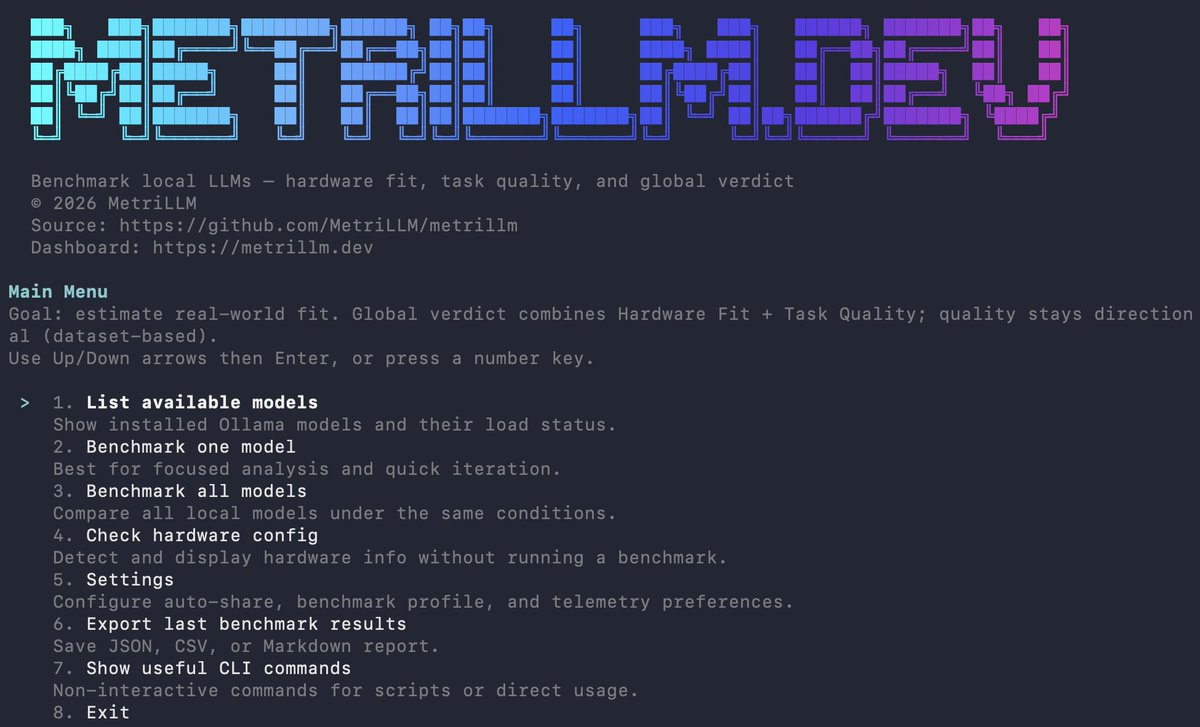
So I built @MetriLLM.
One command. 10 minutes. A clear verdict:
EXCELLENT / GOOD / MARGINAL / NOT RECOMMENDED.
What I learned building it:
→ Most people run models too big for their hardware
→ A 14B that takes 30 s to respond isn’t “good” — even if the answers are great
→ A 4B that scores EXCELLENT beats a 14B that scores MARGINAL. Every time.
→ Time to first token matters far more than people think
The best part: every time someone runs a benchmark and shares it, it helps everyone with similar hardware find the right model. The leaderboard isn’t a ranking — it’s a community-built compatibility database.
Open source. No account. No data sent unless you choose to share.
npx metrillm@latest
metrillm.dev
English
@Topaz750 Excellent ! Il y une image Docker pour lancer ça ?
J'utilise Ollama via Docker :)
Français
@gladysassistant Si tu pouvais partager tes benchmarks sur metrillm.dev avec la communauté, ce serait top !
Français