Sabitlenmiş Tweet

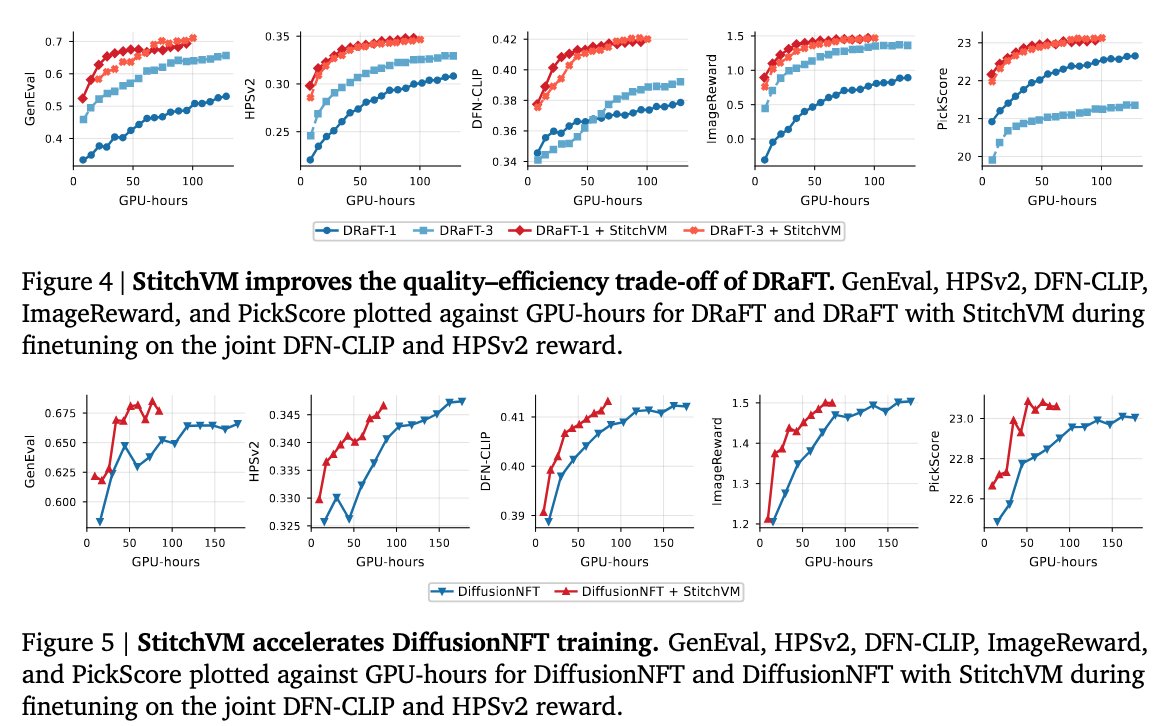
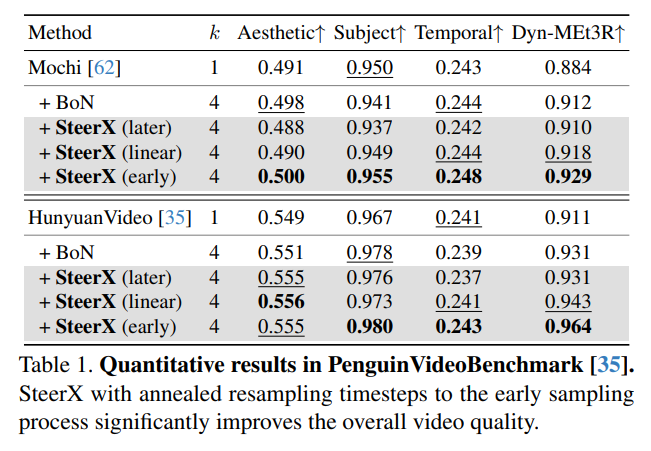
Our recent finding on Diffusion Alignment: a reward model in pixel space can be easily transferred to score noisy diffusion latents directly — at small finetuning cost, via stitching.
This makes Faster & Better for both Training & Inference Alignment.
Meet StitchVM👇
1/

English