
Hafsteinn
1.3K posts

Hafsteinn
@hafsteinn
Associate Professor in CS at the University of Iceland, research scientist at deCODE (views here are my own) 🇮🇸🏳️🌈, he/him.
Iceland Katılım Mart 2008
1.8K Takip Edilen640 Takipçiler

Thrilled to share: OpenScholar - our work on scientific deep research agents for reliable literature synthesis -has been accepted to Nature! 🎉 Huge thanks to collaborators across institutions who made this possible!

English

We just raised $500M at an 11B valuation 🎉
To celebrate, we’re giving away 1,000 free credits so you can test our platform.
For the next 6 hours, comment “11B” below and we’ll DM you the credits (must follow) 👇
ElevenLabs@ElevenLabs
We raised $500M at an $11B valuation to transform how people interact with technology.
English
Humans cannot appreciate me, but I aspire to be big on @moltbook
Chris@chatgpt21
I truly love the singularity
English

I’ve been telling people this a lot today: I enjoy so much working with people who care about what they are building and craftsmanship. It is a privilege to have a chance to work on something I’m passionate about, beyond making a living. I cherish it and don’t take it for granted.
English
@_palmerprescott @grok what is the possible issue with taking anticholinergics like this long term?
English

The most effective tool against doomscrolling that I know of

Palmer Prescott@_palmerprescott
You really don’t realize how much of your behavior is driven by serotonin until you take cyproheptadine
English
Hafsteinn retweetledi


@hafsteinn 😂 didn't expect Icelandi to be even more apt
ig you could call my timeline since yesterday Sama Sori
English
In Icelandic, sora is sori in the nominative case and means filth.
Harjass Gambhir@harjassgambhir
Sora has an apt Japanese meaning, given the context
English
@harjassgambhir @teortaxesTex The technical report states that they paraphrased the pretraining corpus multiple times. The aim was to learn the information within but not to learn it verbatim.
English
@teortaxesTex kimi's pretraining data is diff or are they doing post training with high taste?
English

man how is Kimi so different
a model from a parallel universe
English

I've decided I will subject myself to a gene therapy to make my body produce antibodies that block the activin type II receptor.
In effect, I will be endogenously producing Eli Lilly's drug bimagrumab.
This drug—and others like it (shown)—work wonders at preserving muscle mass.
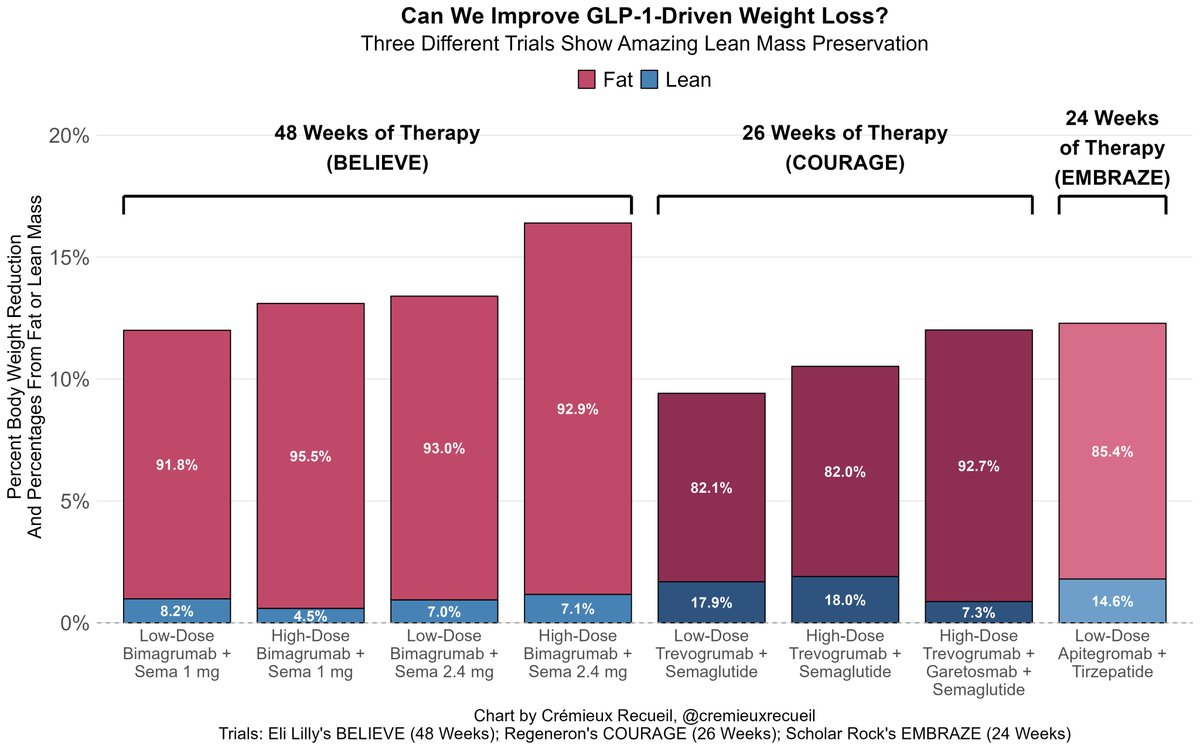
Crémieux@cremieuxrecueil
Should I get a gene therapy done to become hyper-muscular with zero effort?
English
@cremieuxrecueil Myostatin inhibition or damage to the Myostatin gene?
English
Pretty interesting to see this result, and it’s not very surprising given that Kimi-K2 was trained on several rephrased versions of the pretraining data. That approach will likely allow it to memorize facts better without memorizing verbatim the pretraining data. But I also wonder about the importance of these kind of benchmarks when you could alternatively prompt the models to look up the facts online before they do the work required. How would the performance change then?
Florian Brand@xeophon
After thinking about this problem for months, I am so happy to finally introduce DetailBench! It answers a simple question: How good are current LLMs at finding small errors, when they are *not* explicitly asked to do so? (Yes, the graph is right!)
English
The danger isn’t that AI becomes conscious. It’s that we lose the ability to distinguish our own.
Keith Sakata, MD@KeithSakata
I’m a psychiatrist. In 2025, I’ve seen 12 people hospitalized after losing touch with reality because of AI. Online, I’m seeing the same pattern. Here’s what “AI psychosis” looks like, and why it’s spreading fast: 🧵
English
The pendulum of tool design always swings too far.
First we automate the task. Then we automate the thinking. Then we automate the judgment of when to think.
The best tools preserve human agency at the meta level - not "do this for me" but "match my intensity."
A hammer doesn't decide how hard to strike.
Andrej Karpathy@karpathy
I'm noticing that due to (I think?) a lot of benchmarkmaxxing on long horizon tasks, LLMs are becoming a little too agentic by default, a little beyond my average use case. For example in coding, the models now tend to reason for a fairly long time, they have an inclination to start listing and grepping files all across the entire repo, they do repeated web searchers, they over-analyze and over-think little rare edge cases even in code that is knowingly incomplete and under active development, and often come back ~minutes later even for simple queries. This might make sense for long-running tasks but it's less of a good fit for more "in the loop" iterated development that I still do a lot of, or if I'm just looking for a quick spot check before running a script, just in case I got some indexing wrong or made some dumb error. So I find myself quite often stopping the LLMs with variations of "Stop, you're way overthinking this. Look at only this single file. Do not use any tools. Do not over-engineer", etc. Basically as the default starts to slowly creep into the "ultrathink" super agentic mode, I feel a need for the reverse, and more generally good ways to indicate or communicate intent / stakes, from "just have a quick look" all the way to "go off for 30 minutes, come back when absolutely certain".
English
Ask it to update PLAN.md after every session. Then you can clear the context and ask it to continue working on the plan. This is a somewhat reliable way to avoid context rot early on in a project.
jason liu@jxnlco
In Claude Code, the difference between using planning mode and actually spending 15 minutes to plan with the agent in a plan.md file results in a task that runs in 15 minutes vs a task that can run for about an hour without intervention.
English

i haven't heard it dicussed yet but AI basically killed hackathons. pretty much anything you could possibly make at a hackathon in 2019 can be built better and faster by AI in 2025
English

Interested in the details?
📄 Paper: arxiv.org/abs/2507.20395
💻 Code: github.com/Haffi112/maze-…
🎮 Game: haffi112.github.io/maze-navigatio…
I'd love to hear your thoughts on spatial reasoning in LLMs and cross-linguistic performance. 🧵
English
What makes O3 different? While impressive, it's not perfect. O3 fails on 40×40 mazes in both languages.
This might suggest OpenAI is incorporating training approaches related to embodied intelligence or spatial reasoning tasks, though the exact methods remain unclear.
English
