Harit Vishwakarma retweetledi

Hi ML Twitter!
My Summer 2026 internship unfortunately fell through last minute 😵💫
If your team is looking for interns, I’d love to connect - RTs appreciated 🙏
My website: aniketrege.github.io
English
Harit Vishwakarma
274 posts

@harit_v
Postdoc@Oxford, LLM Reliability and Data-centric AI, prev. @WisconsinCS, @iiscbangalore, @IBMResearch.


We were honoured to host Sir Demis Hassabis at IISc today for deeply insightful discussions!




AI coding agents are essentially compilers -- for English instead of C.


Our paper “Learning from Less: Measuring the Effectiveness of RLVR in Low Data and Compute Regimes” was accepted to #MLSys 2026! We introduce three procedurally generated, verifiable datasets—Counting, Graph, and Spatial Reasoning—to study RLVR under low-data / low-compute constraints. Key result: small, mixed-complexity datasets can be more data-efficient than large, easy ones.
Our paper “Learning from Less: Measuring the Effectiveness of RLVR in Low Data and Compute Regimes” was accepted to #MLSys 2026! We introduce three procedurally generated, verifiable datasets—Counting, Graph, and Spatial Reasoning—to study RLVR under low-data / low-compute constraints. Key result: small, mixed-complexity datasets can be more data-efficient than large, easy ones.

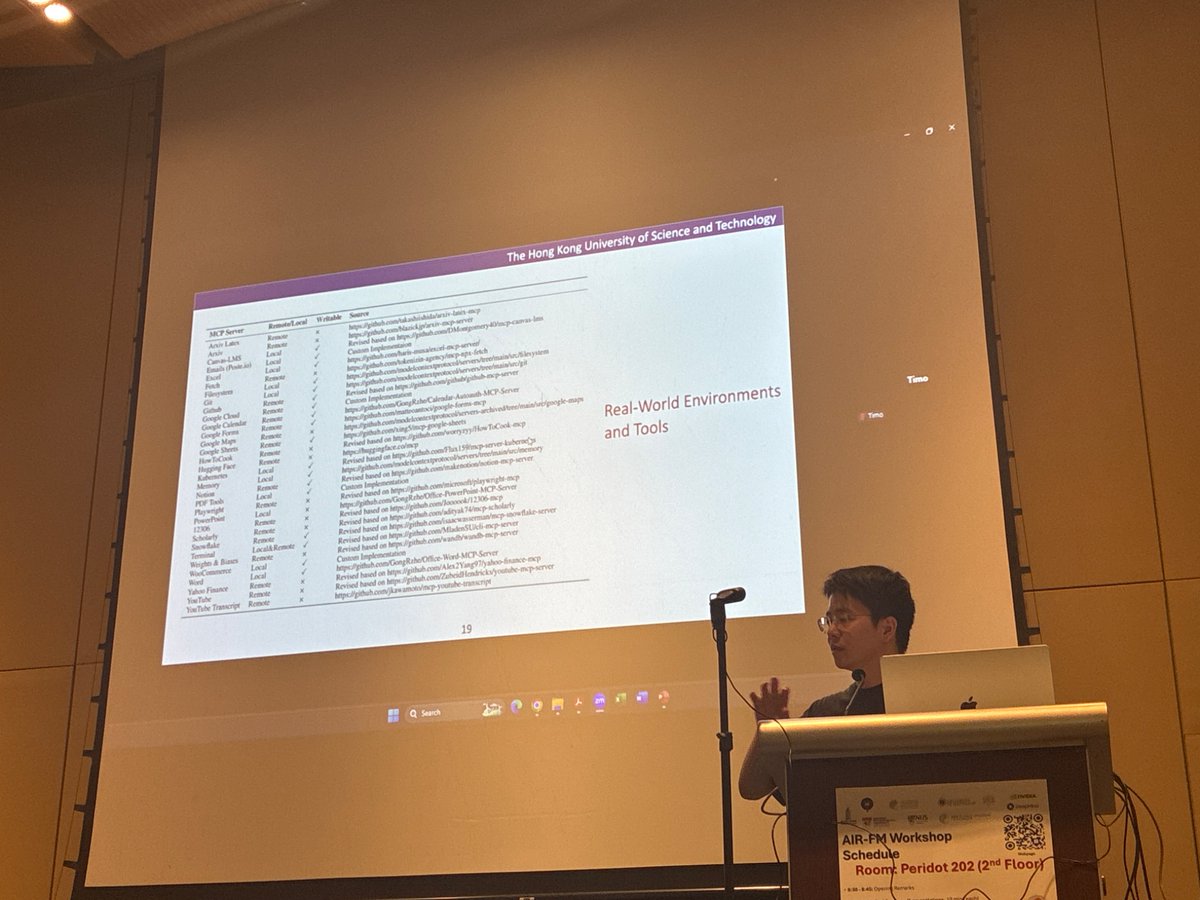
@shashankska Junxian He from HKUST keynote on reliability of virtual employees 🫡
Join us at #AAAI2026 (Singapore) for AIR-FM: Assessing and Improving Reliability of Foundation Models in the Real World. 📅 Mon, 26 Jan 2026 | 8:30–5:00 📍 Peridot 202 (2nd Floor) llmrel.github.io
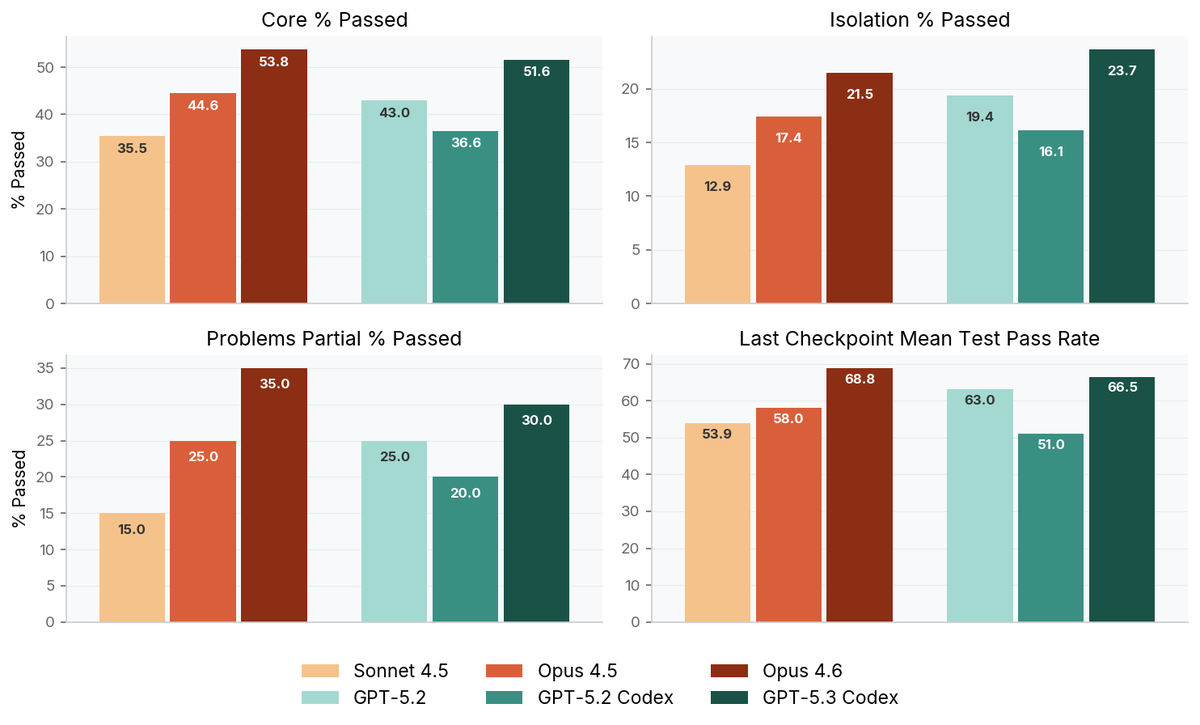
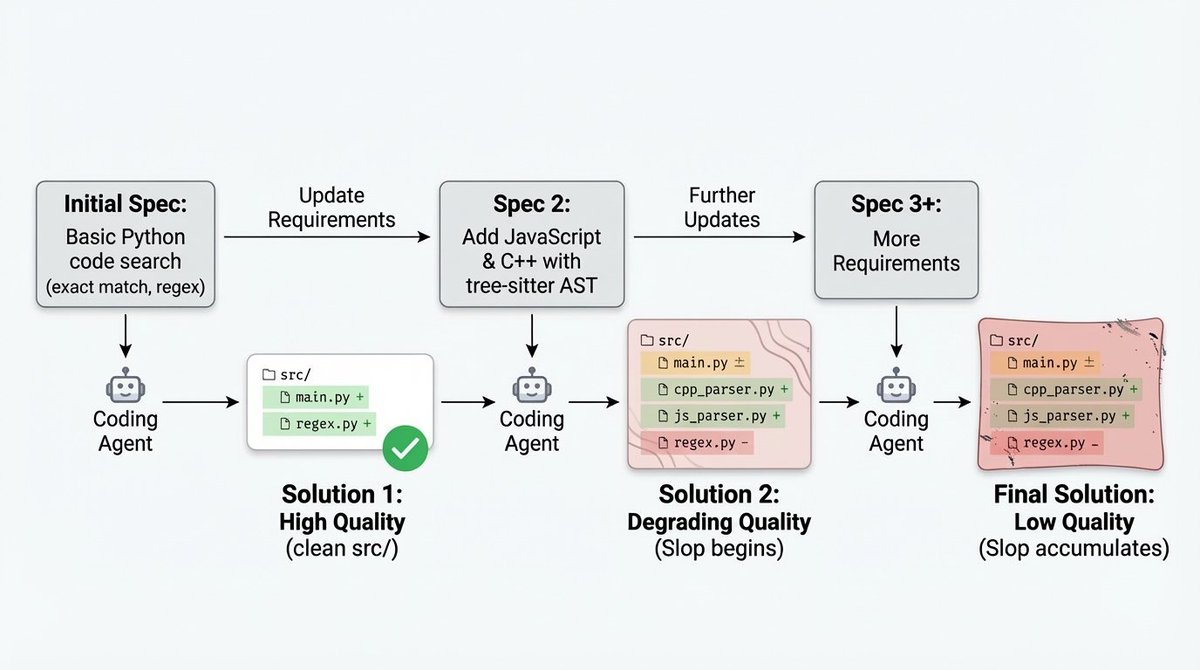
Often, a bug I have had to fix has been tied directly to overly verbose or defensive code from an AI agent that has eroded my project as the specs changed. Why isn't there an eval for this? There is now. Very excited to announce SlopCodeBench scbench.ai






Static benchmarks can’t keep up with the pace of AI progress. Our latest research introduces BeTaL—Benchmark Tuning with an LLM-in-the-loop—a framework that uses reasoning models to optimize benchmark design dynamically. ✍️ From the Snorkel Research team: @amanda_dsouza , @harit_v , @qi_zhengyang , @realjustinbauer, @pham_derek, Tom Walshe, @ArminParchami, @fredsala, and Paroma Varma