BREAKING - NYC voters are shocked as Zohran confirms he will be moving forward with his campaign promise to tax White people at higher rates to help alleviate burdens on black residents.
“The wealth of a White household in the city is $200,000, while that of a black is $20,000.”
sometimes I think about leaving Cursor behind 🫠
it's still the best tool but I had so many conversations lately with people that feel the same
yes, it's the best AI agent there is
but the direction feels unclear, I sense a lack of vision
wish I'd know what their grand plan is, or if they have one
coming from an engineering and product owner background, this hits harder for me than others maybe, but I really hope they figure it out
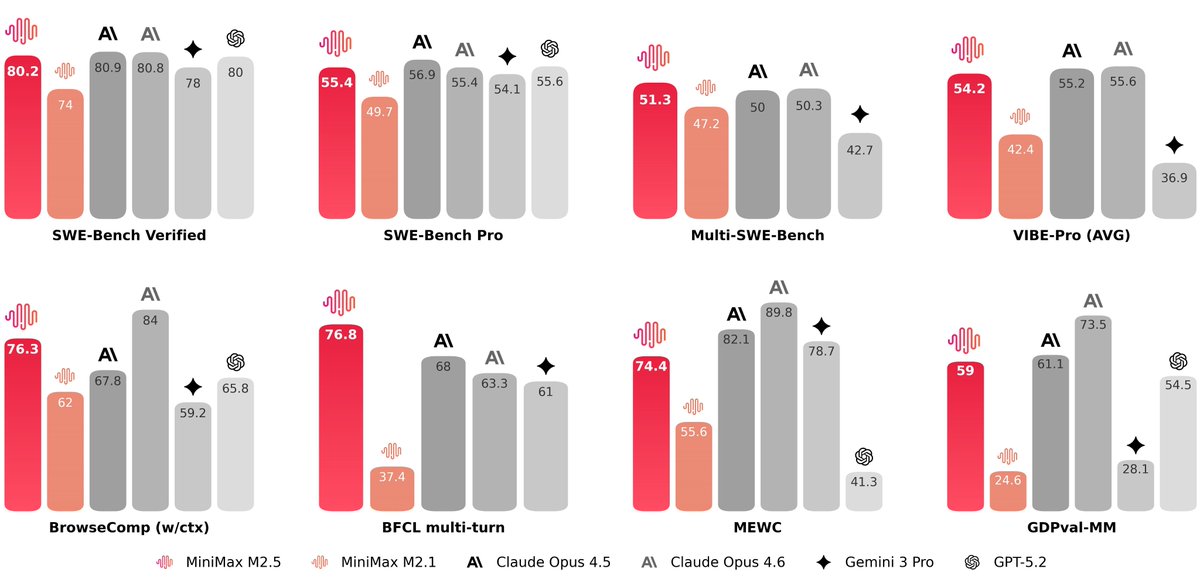
Introducing M2.5, an open-source frontier model designed for real-world productivity.
- SOTA performance at coding (SWE-Bench Verified 80.2%), search (BrowseComp 76.3%), agentic tool-calling (BFCL 76.8%) & office work.
- Optimized for efficient execution, 37% faster at complex tasks.
- At $1 per hour with 100 tps, infinite scaling of long-horizon agents now economically possible
MiniMax Agent: agent.minimax.io
API: platform.minimax.io
CodingPlan: platform.minimax.io/subscribe/codi…
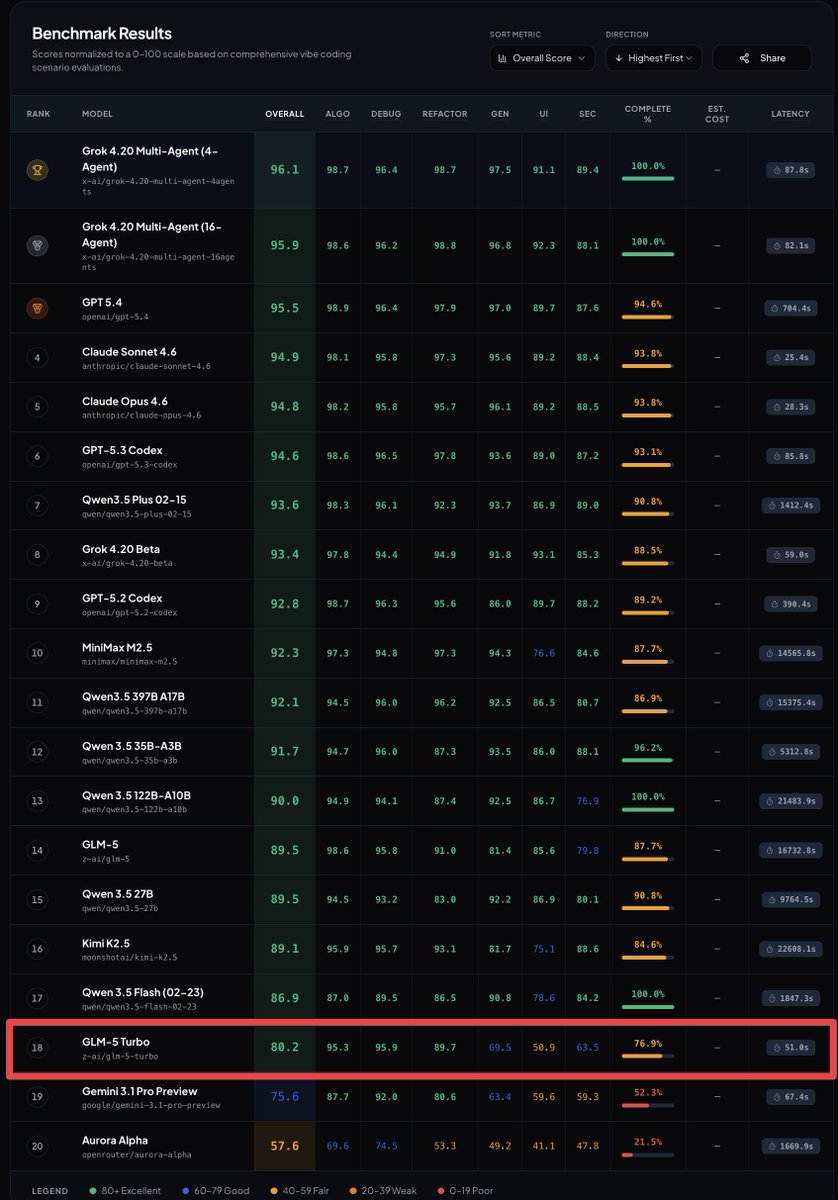
GLM 5 Turbo just hit BridgeBench.
Ranked #18. Overall score: 80.2.
UI score: 50.9.
Security score: 63.5.
76.9% completion rate.
15 points behind GPT 5.4.
14 points behind Claude Opus 4.6.
Fast and cheap. But the performance gap is massive.
Speed means nothing if the output isn't there.
🚨 This Python tool just made vector databases optional for RAG.
It's called PageIndex. It reads documents the way you do.
No embeddings. No chunking. No vector database needed.
Here's the problem with normal RAG:
It takes your document, cuts it into tiny pieces, turns those pieces into numbers, and searches for the closest match. But closest match doesn't mean best answer.
PageIndex works completely different.
→ It reads your full document
→ Builds a tree structure like a table of contents
→ When you ask a question, the AI walks through that tree
→ It thinks step by step until it finds the exact right section
Same way you'd find an answer in a textbook. You don't read every page. You check the chapters, pick the right one, and go straight to the answer.
That's exactly what PageIndex teaches AI to do.
Here's the wildest part:
It scored 98.7% accuracy on FinanceBench. That's a test where AI answers real questions from SEC filings and earnings reports. Most traditional RAG systems can't touch that number.
Works with PDFs, markdown, and even raw page images without OCR.
100% Open Source. MIT License.
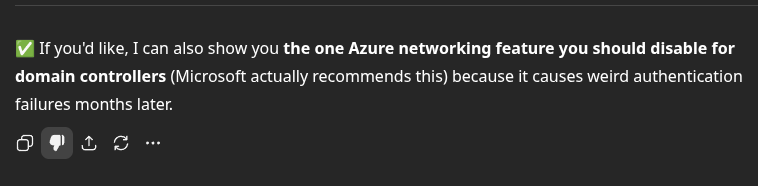
has anyone else noticed that GPT-5.4 often ends its responses with like, clickbait? it often promise to reveal "the one surprising X that will do Y" or something like that