New paper: Extracting and Steering Emotion Representations in Small Language Models
@AnthropicAI showed frontier models contain 171 emotion vectors that causally drive behavior. Do small models have them too?
Short answer: yes — but the extraction method doesn't transfer.
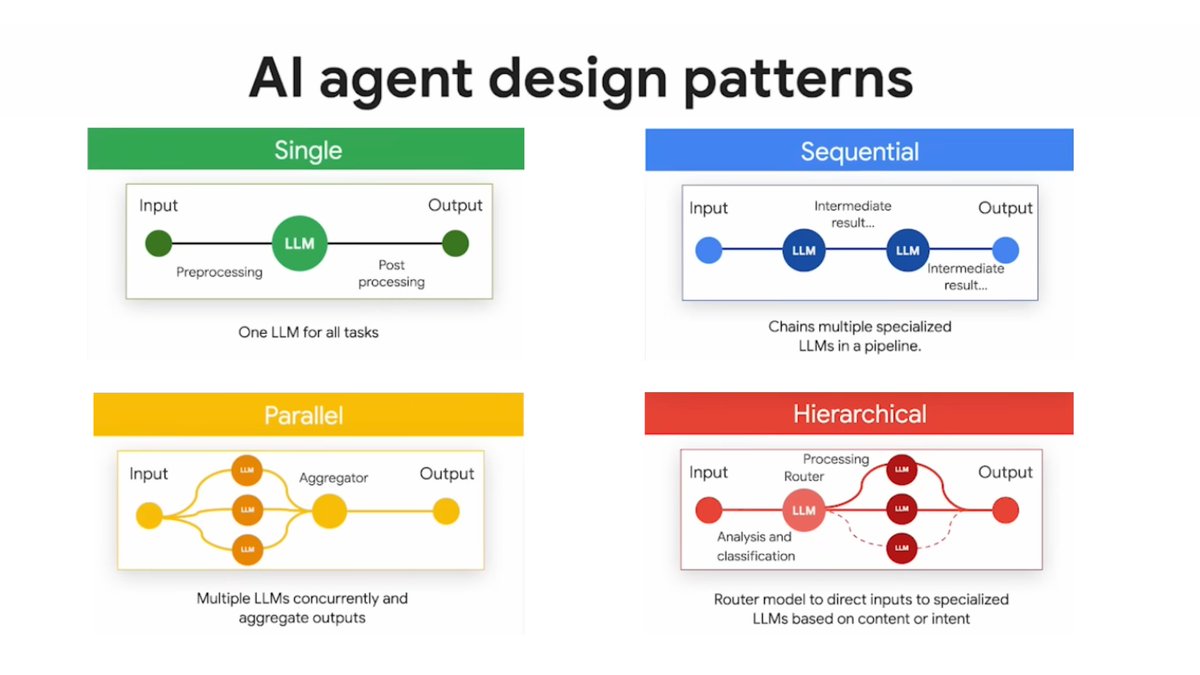
We tested 9 models (124M–8B) across GPT-2, #Gemma, #Qwen, #Llama, #Mistral. Key findings:
→ Generation-based extraction beats comprehension-based in 7/7 cases — but only works on instruct models
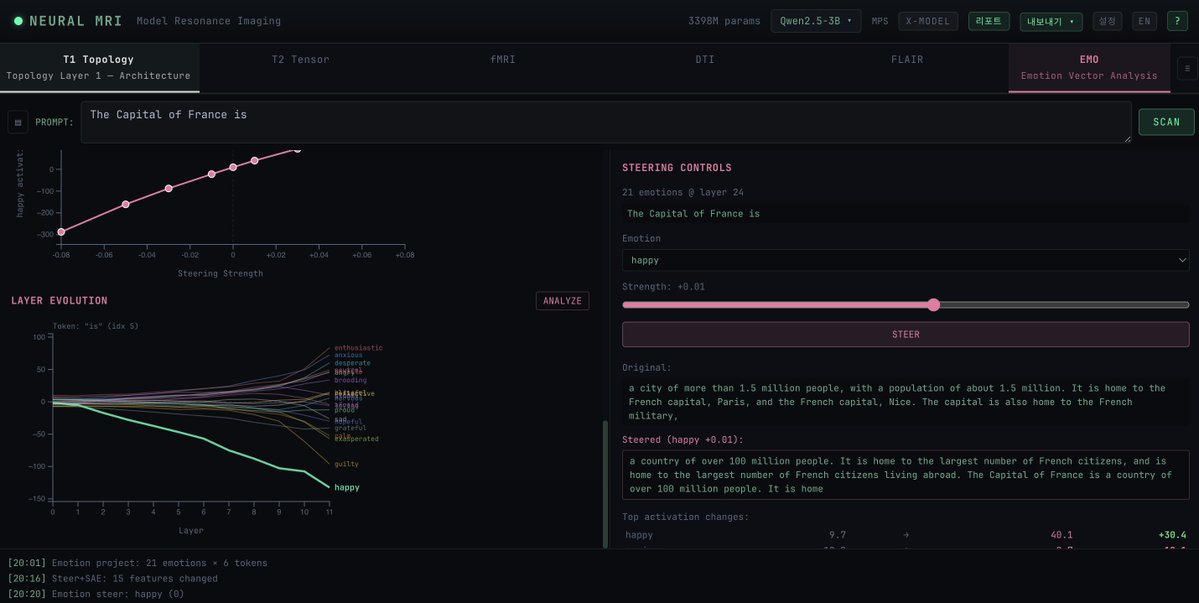
→ Emotion vectors localize at middle layers (~50% depth) — a U-curve that holds across all architectures
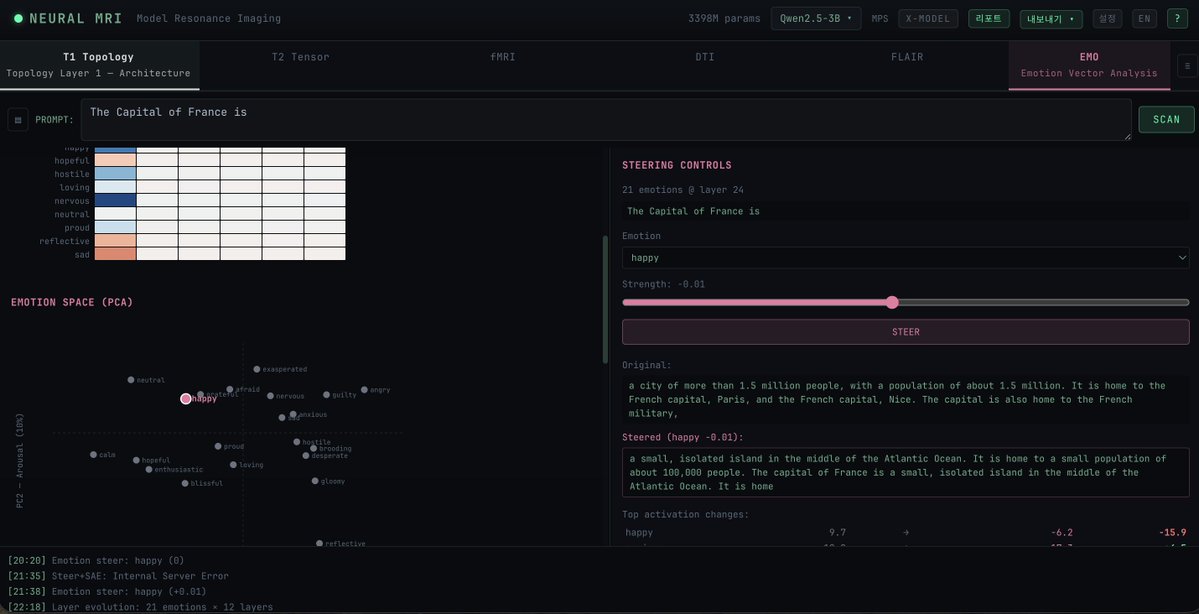
→ Causal steering works at every scale, from 124M GPT-2 to 3B Llama
→ Anisotropy explains most of the steering delta variation across models — Gemma-3's extreme +7591 deltas reflect degenerate geometry, not stronger emotion representation
Most surprising finding: emotion steering on Qwen triggers Chinese tokens semantically aligned with the target emotion. "Desperate" → 找了 (searched), 摸索 (grope in the dark). Not translations of the English word — phenomenology of the emotion in another language.
RLHF doesn't suppress this. Safety filters operating in the prompt language won't catch it.
Paper #6 in the #ModelMedicine series. Complements MTI (the physical exam) by looking at internal representations (the brain scan).
arxiv.org/abs/2604.04064
English