Qingye Meng@hilbertmeng
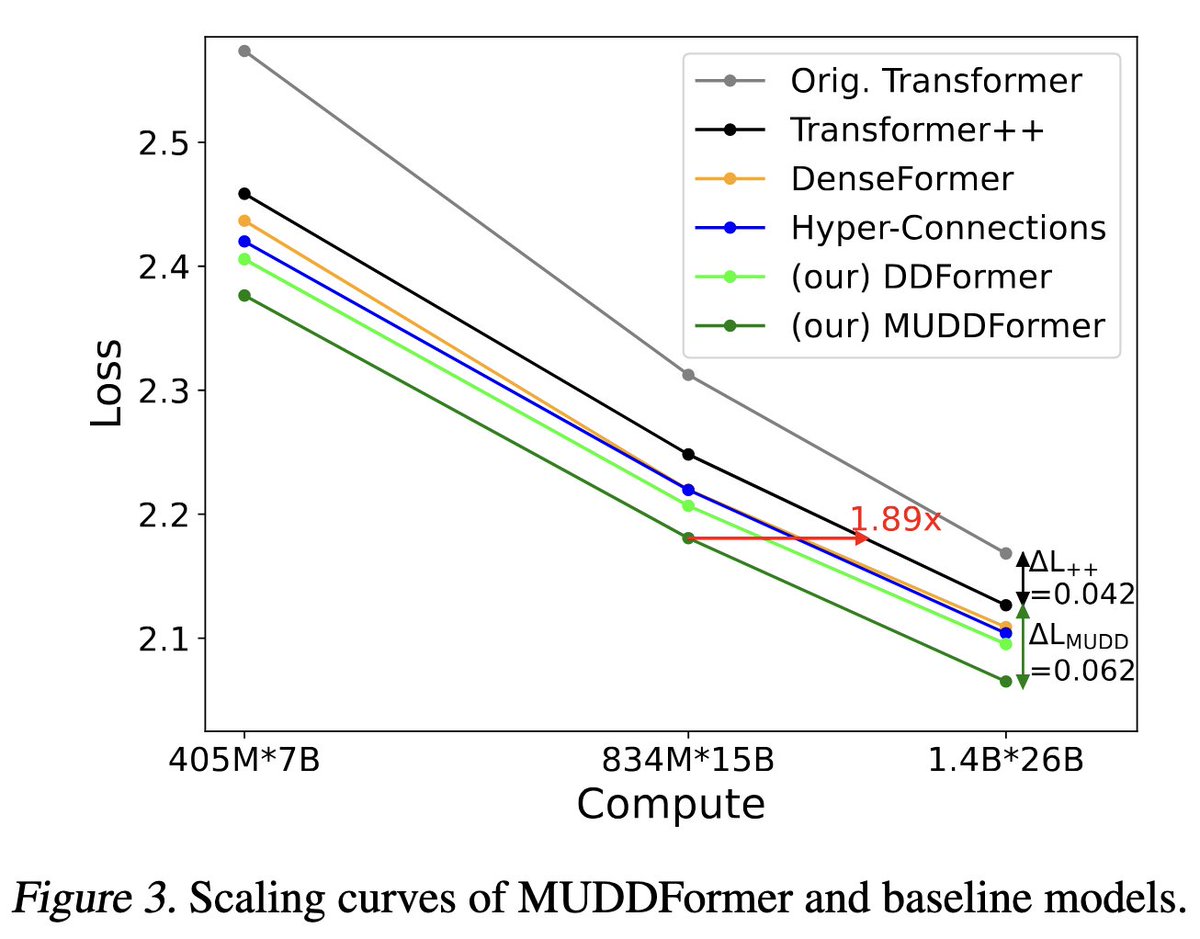
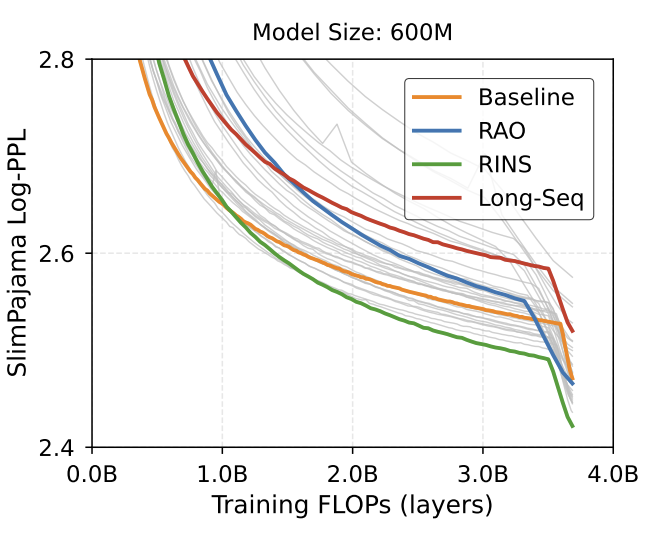
Great to see depth-wise attention mechanisms like mHC and Attention Residuals (AttnRes) proving their scalability in large-scale models, and attract more attention to this line of work, including DenseFormer, HC, DeepCrossAttention (DCA) and our MUDDFormer (ICML25). We proposed multi-way dynamic dense connections along transformer layers to address the limitation of residual connections, where DynamicDenseFormer is similar to Kimi's Full AttnRes. I'd like to compare decoupling of residual streams, PP, training stability and details on depth attention weights.
1. Decoupled residual streams
In MUDDFormer, we decouple the residual stream into 4-way/stream QKVR—a strategy also explored in the concurrent DCA, which is effective but absent in recent practices. We are motivated by different attribution circuits, like Q-attribution, V-attribution in mechanistic interpretability studies. Decoupled residual streams can better handle cross-layer information flow. In mHC and AttnRes, depth-wise attention is applied before each Attention and FFN block, so they can be seen as a 2-stream residual.
2. Pipeline Parallelism (PP)
Efficiency is the primary bottleneck for dense cross-layer connections. Kimi addresses this via Block AttnRes, which reduces communication by attending to block-level summaries, while HC compresses the residual stream into hyper hidden states (typically 4 times wide) to reduce communication. In DenseFormer/MUDDFormer, key-wise dilation on dense connections is also a simple approach to reduce PP overhead. If PP is not a strict requirement (e.g., in TPU-based pretraining), MUDDFormer already demonstrates strong performance, and query-wise dilation can further provide an excellent balance between performance and efficiency.
3. Training stability & Depth attention weights
To stabilize the residual mapping, mHC proposed the Sinkhorn-Knopp algorithm, while MUDDFormer tackles training stability by PrePostNorm in deep models. In HC and AttnRes, depth attention weights are dependent on key-wise layer outputs, while MUDDFormer utilizes a small MLP to generate weights from the query-wise hidden states.