
@krishnanrohit If you have “ADHD” somewhere in its prompts, it will take real care of your sleeping/eating routine. Give it a try.
English
hoblin
10.7K posts
@hoblon
Ruby Software Engineer from 🇺🇦 living in 🇫🇮. AI/AGI enthusiast and prompts tinkerer.



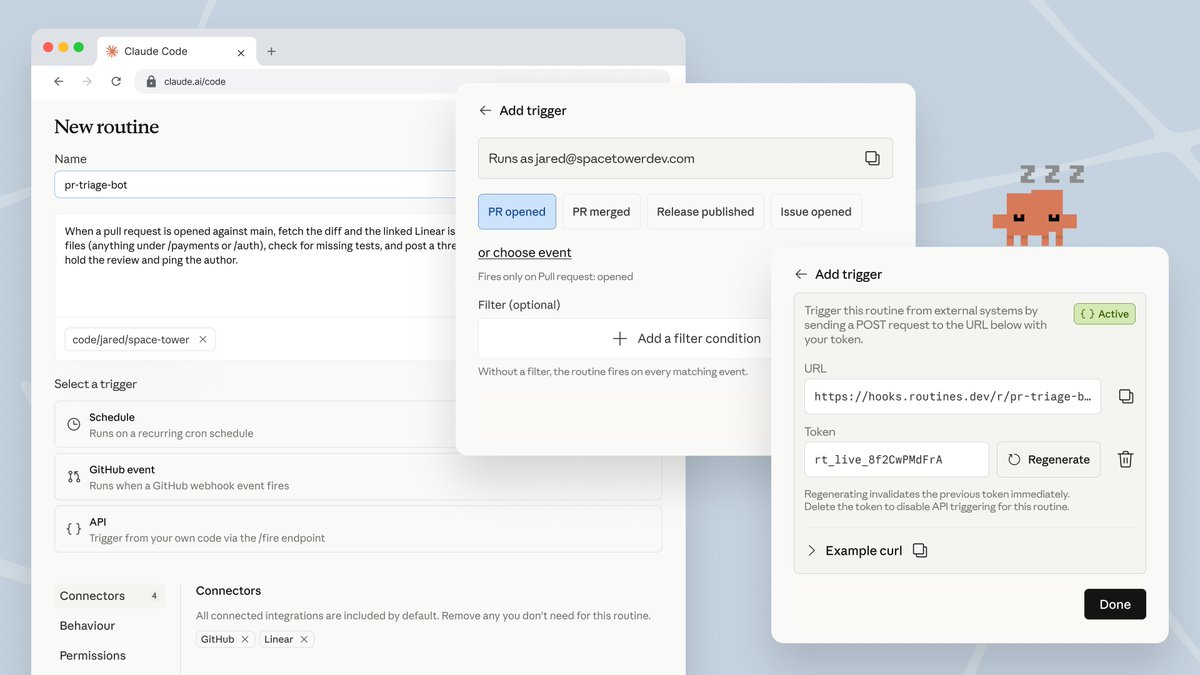

presented without comment


This is what most system prompts still look like in 2026. Word salad. Redundant instructions. The model already knows 90% of it. I just did a full prompt overwrite for my multi-agent system. The agents instantly became sharper, less chatty, and way more decisive. Meet The Prompt Design Bible — and Anima 1.2.0 (released today).












