crypto大声密谋 retweetledi

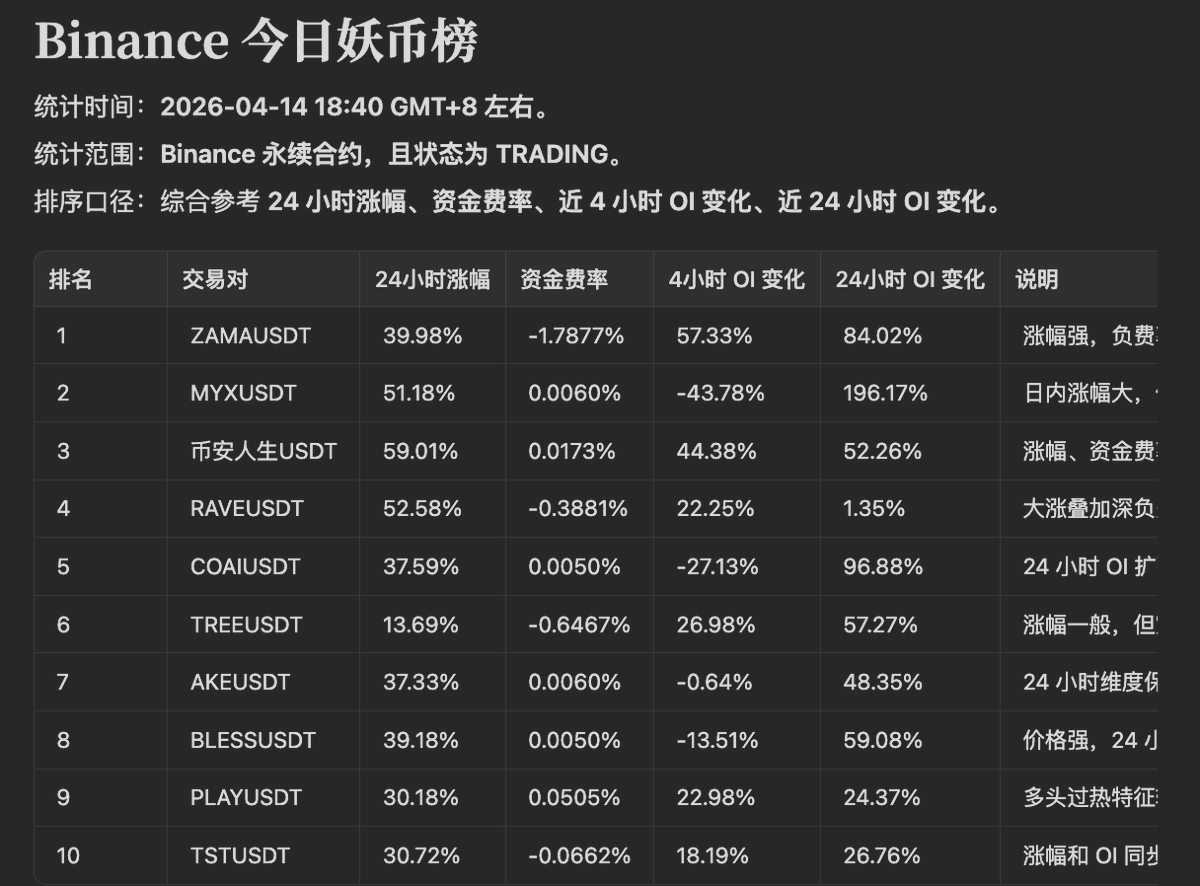
妖币纵横 你需要一个实时信息流提醒 Agent
only opennews can do
Cryptoxiao@cryptoxiao
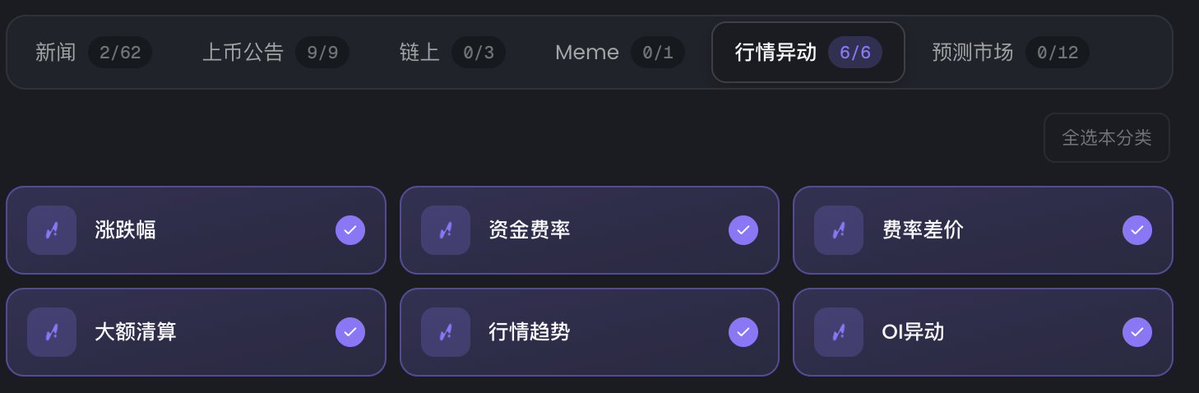
忘了说了,opennews其实还可以查询和监听实时OI变化 包括各类市场实时告警信号 (:
中文
crypto大声密谋
535 posts


忘了说了,opennews其实还可以查询和监听实时OI变化 包括各类市场实时告警信号 (:






连着跑了四天的广场测试盘亏麻了 胜率跌到可怜的 19.2% 看了下开的仓,昨天火热的 $SPK 这程序在 0.313 就入手了,但在 0.337 就止盈了 反正程序的止盈和止损都有很大的问题 但是抓热门代币的这块做的还不错啦 打算这两天试试能不能把程序传到 Github 靠着他交易是难了,但兄弟们可以用来当参考工具用用


这个太牛逼了!Github 81万收藏!!! 一个能把全世界的岗位变成AI员工的存储库,它包含了20+职能分类、140+岗位,而且每一个都是专家级别 只需要把想要的身份喂给Agent就可以拥有一个专属的专家级AI助手,还可以多个Agents分头工作、各自执行 github.com/msitarzewski/a…

LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.


免费用Claude Opus 4.6?阿里海外版企业Agent「Accio Work」悄悄上线了 阿里国际(Alibaba International)3月23日发布的企业级AI Agent平台,定位是给中小企业提供即插即用的AI团队,零代码、零配置,直接部署专业Agent处理复杂业务流程 几个值得关注的点: → 不是聊天机器人,是自主执行的Agent团队。给一个目标,系统自动组装"分析师+设计师+物流专家"的跨职能小队并行工作 → 覆盖SME全链路:市场调研、产品设计、供应商询价多轮谈判、VAT申报(覆盖100+市场)、营销自动化、库存监控,还能对接Telegram和WhatsApp → 数据底座是阿里电商生态的实时消费趋势和真实交易记录,不是靠通用模型瞎猜,理论上能降低幻觉率 → 安全层面做了沙箱隔离和权限分级,涉及资金和文件操作需要用户显式授权 → 用户可以把自己的业务流程封装成可复用的"skill",甚至可以分享或变现 不过有几个问号:原推说底层是Claude Opus 4.6,但阿里官方新闻稿里并没有提到具体用了什么模型。月活已经超过1000万,但这个数据是从之前B2B采购引擎Accio延续过来的,Work版本刚上线,实际企业场景的效果还需要观察 🔗 work.accio.com




和推友聊天讲到了关于这里面的提示词模板是怎么做的,其实是有一套Skill在帮我一起完成的。 基础流程就是找到一个不错的提示词无论中文英文。进行简单的过滤后扔给我的提示词填空器模板创建skill,会完成大部分工作。 我的主要工作是检查分词质量,控制变量数量,测试不同变量组合的效果。 然后最后配一张合适的图,再部署上线。 我最近看看怎么把这套skill泛化一下做个开源处理吧,应该还是有人会用到的吧