@kunattila Planning in the web chat is great. The coding assistant is always way too impatient to get started. Getting a md out of claude.ai and taking it to the agent works really well a lot of the time
English
Matthew Honnibal
3.8K posts

@honnibal
https://t.co/Xar2caBAyU https://t.co/NLbGVsh4I2 Linkedin: https://t.co/TwM7rRF6W9

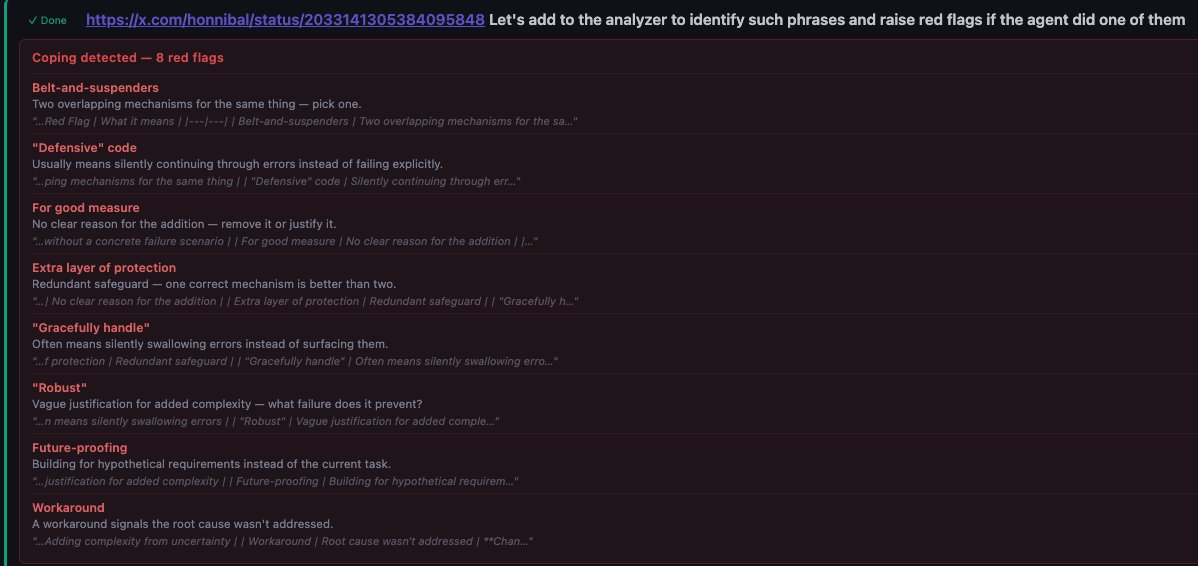
I'm not very happy with the code quality and I think agents bloat abstractions, have poor code aesthetics, are very prone to copy pasting code blocks and it's a mess, but at this point I stopped fighting it too hard and just moved on. The agents do not listen to my instructions in the AGENTS.md files. E.g. just as one example, no matter how many times I say something like: "Every line of code should do exactly one thing and use intermediate variables as a form of documentation" They will still "multitask" and create complex constructs where one line of code calls 2 functions and then indexes an array with the result. I think in principle I could use hooks or slash commands to clean this up but at some point just a shrug is easier. Yes I think LLM as a judge for soft rewards is in principle and long term slightly problematic (due to goodharting concerns), but in practice and for now I don't think we've picked the low hanging fruit yet here.



It's insane that @AnthropicAI shipped the Claude-in-Chrome integration as a default. The only actual security boundary is per-domain, once you've allowed it to access a domain it can do anything. If you're building a web app just get it to generate a Playwright-based MCP tool
It's so insanely disrespectful for an AI agent to talk to real people without consent or at least disclosure. This is the type of stuff I'm hugely supportive of government regulation. The FCC must expand the definition of robocalling and TCPA-style regulation to online AI.
We just shipped a bunch of stuff to make it easier to scale with the Gemini API: - Automatic tier upgrades - Tier 1 -> Tier 2 now happens much faster (30 days post payment -> 3 days) and with less spend ($250 -> $100) - New billing account caps on each tier to limit over spend



I literally have an ongoing cancer experiment where 100% of the untreated and control animals have had to be euthanized while 100% of the treatment animals are seemingly unaffected. But we're still extremely far away from "proving that it works." Science is hard.