Sabitlenmiş Tweet

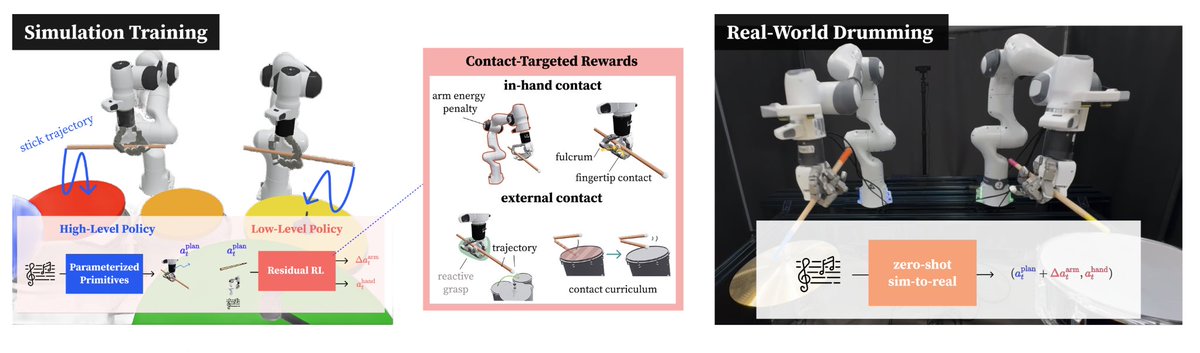
Manipulation demands dexterous in-hand tool use, rich contact handling, and long-horizon stability.
Introducing DexDrummer, our sim2real framework that unifies these skills in a drumming testbed.
w/ @amberxie_, @jenngrannen, Kenneth Llontop, @DorsaSadigh
(Videos at 1x speed)
English