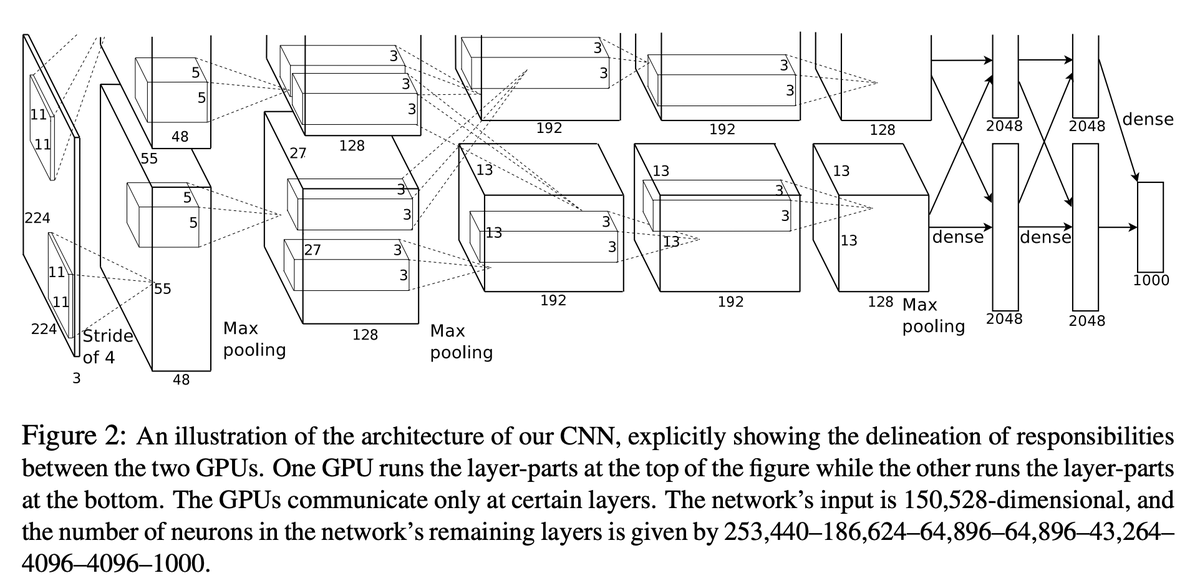
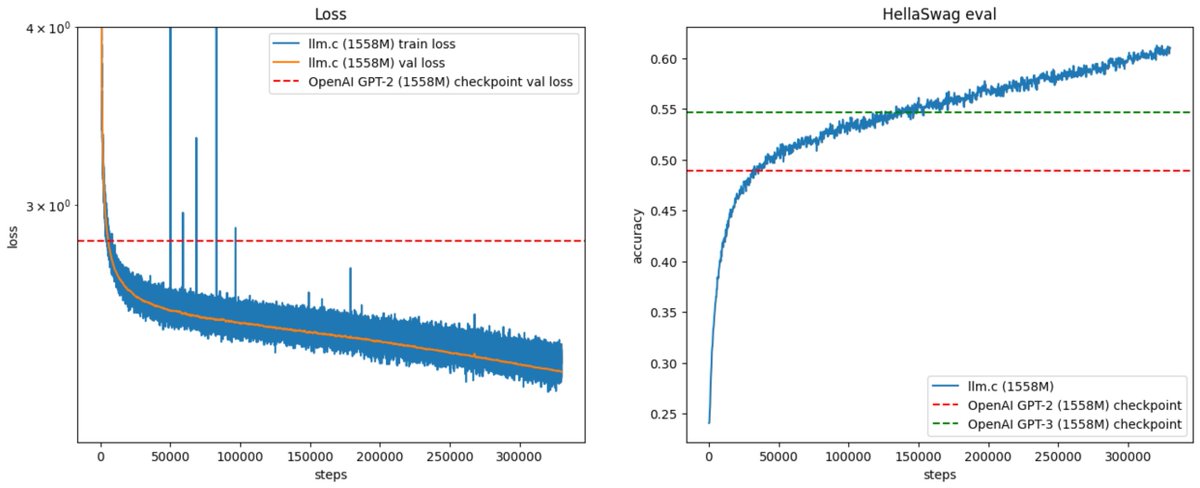
@cmarschner @karpathy Patrice is great. Worked with him back at MSR back in the day. Published a neural network implementation on a GPU which is afaik the first published work ever of a GPU running a neural network and, yup, it was faster than CPUs even back in 2025.
ieeexplore.ieee.org/abstract/docum…
English