Duyihao duyihao.com
34 posts

Duyihao duyihao.com
@iduyihao
To be a better man. github: https://t.co/ppPNBR0swh
日本 東京 Katılım Aralık 2015
11 Takip Edilen1 Takipçiler



如果你经常在浏览器里看长文、教程、文档,
可以试试我做的这个浏览器插件:一览。
打开网页后按一下 `Alt + S`,
它会先把正文提出来,再给你一个结构化总结。
如果还不够,还能继续整理成行动项、术语表、问答卡。
我自己开发时候就很满意的一点设计是,
结果不是看完就没了。
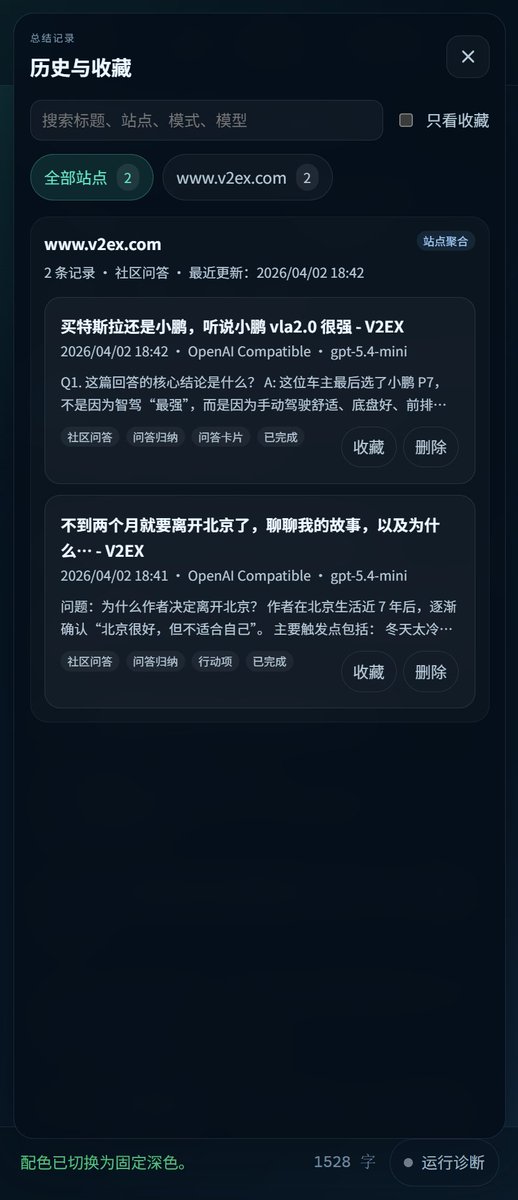
它可以留在本地历史里,后面搜索、收藏、回看都方便;
想认真读的时候,也能直接切到独立阅读页。
它更像一个网页阅读工作台,
不只是一个“一键总结”插件。
(BYOK)模式。
官网: yilan.app
GitHub: github.com/mutuyihao/yilan



中文


@turingou wow, awesome. 似乎还有很多 agent 不方便,需要借助人力的地方,都可以慢慢提供类似的服务。
中文

BTC严格遵守四年减半牛市规律,牛市顶点后基本1年半左右见底,这轮熊市估计在明年3月到达38000左右开始底部震荡。(中间至少有两次大机构暴雷)
在2027一整年完成35000~47000约34.29%震荡区间,开始回升,到28年4月20日附近完成第五次BTC减半后还有1年半的牛市。好好活到明年3月(见底后一级开始回暖)

magnolia@0xmagnolia
上轮牛市积累经验 本轮熊市积累本金 下轮牛市积累财富 一定要好好活下去
中文
Duyihao duyihao.com retweetledi

最近,Kimi 团队公布了新的kimi k1.5模型,这也与前段时间 OpenAI 推出的重要研究息息相关:即通过强化学习(RL)方法,在大语言模型(LLM)的训练和推理中,发现了一种新的 Scaling Law。相比于 ChatGPT 横空出世时依赖堆叠算力和海量数据提升智能性的方式,这种新的 Scaling Law 显然更具潜力。毕竟,如今可用的人类语言数据几乎已经被充分挖掘,而构建更大规模的 GPU 集群不仅成本高昂、能源消耗巨大,且只有极少数组织能够负担。
GPT o1: 模型准确率随训练和测试时间的Scaling Law
新 Scaling Law 的意义
GPT o1 体现出的训练和测试时间的 Scaling Law 令人印象深刻,我个人也对这种新方法抱有很大期待。判断 AI 是否真正具备智能,关键在于它能否学习并超越人类的思维模式。而显然,人类的学习并不完全依赖传统 Scaling Law 中堆叠数据和算力的方式。聪明人往往无需反复被灌输大量知识,就能掌握抽象概念和复杂理论。而当前主流 LLM 的短板正是这一点:尽管在信息归纳、标准化代码生成、创作等简单任务上表现优异,但在理解高度抽象知识和复杂推理能力上仍显不足。
Kimi 团队的创新方法
Kimi 团队的一大亮点在于摒弃了传统训练中常用的价值网络(value network)。在复杂推理中,找到正确答案的过程往往比答案本身更为重要。即使得到了正确答案,但如果只是“蒙对”,其价值远不及深入思考的过程——哪怕最终推导出的答案是错误的。因此,团队人为增加了策略优化(policy optimization)中对答案多样性的采样权重,让模型能够探索更多样化的思维路径,而不是局限于单一的正确答案。
此外,为了减少模型通过“过度思考”(overthinking)来刷准确率的倾向,Kimi 团队在奖励函数设计中加入了长度惩罚(Length Penalty)机制。简单来说,这种机制鼓励模型提升思考质量,而非通过堆砌回答长度来获得奖励。这一操作看似简单,却展现了显著的效果——深度学习领域中许多突破正是依赖类似的小技巧实现了性能飞跃。
Kimi 团队设计的Length Penalty。注意y_i代表 采样得到的多次回答;通过简单设计这里惩罚了正确的短答案,并且给与了错误的长答案一定奖励
Length Penalty 的具体设计
在 Length Penalty 的实现中,团队对采样得到的多次回答(yiy_iyi)进行了惩罚:短且正确的答案被略微削弱,而长且错误的答案则获得了一定奖励。这种设计有效避免了传统方法中依赖答案长度来提升评分的弊端。
Partial Rollout 策略与计算优化
Kimi 团队的另一大创新在于 RL 训练中引入了新型的 Partial Rollout 策略。众所周知,大规模 RL 算法以及商业级 LLM 的训练需要庞大的算力,而 Rollout 是一种从 AlphaGo 和 AlphaStar 时代就被广泛应用的近似动态规划策略。在 RL 训练中,Agent 需要不断通过与环境交互获取奖励(reward),从而优化其行为。然而,当环境和任务复杂度提升时,穷尽所有可能动作显然不现实,因此需要更高效的采样策略。
Kimi 团队的 Partial Rollout 策略通过为轨迹(trajectory)设置 token 上限,当一条轨迹达到上限后,其未完成部分被置入 Replay Buffer,等待下一个迭代使用。这种设计避免了少数长轨迹占用大部分计算资源。同时,异步化的 Rollout Workers 允许长短轨迹同时作用于训练过程,进一步提升了 Long CoT 模式下的思考深度。
令人期待的未来
Kimi k1.5 的数学、代码以及多模态推理能力在 long-CoT 模式下,与 OpenAI o1 正式版的水平已经非常接近,展现了惊人的潜力。我尤其对报告中展示的 k1.5 模型在多模态(图片 + 文本)领域的表现印象深刻。
可以看到,在 long-CoT 模式下,Kimi k1.5 的数学、代码、多模态推理能力三项上,和长思考 SOTA 模型 OpenAI o1 正式版的水平差别不大
Kimi k1.5 的推出,或许标志着人类在探索 LLM 新 Scaling Law 的道路上迈出了重要一步。或许未来,有朝一日,LLM 不仅能像人类一样思考,甚至可能真正超越人类。



中文