
Ismael Juma
12K posts
Ismael Juma
@ijuma
Kafka, Scala, JVM, distributed systems, performance, machine learning, Haskell, @ConfluentInc.
San Francisco Bay Area, CA Katılım Aralık 2008
513 Takip Edilen4.6K Takipçiler
Nice wins from Shenandoah late barrier expansion "Our expectation was that LBE would be most impactful on C2 compilation times. We are indeed seeing up to 30% faster compilations. However, LBE also dramatically improves application performance directly."
English
Nearly 12 years after Valhalla was initially announced, a pull request that implements the first preview of JEP 401: Value Classes and Objects has been submitted to the main OpenJDK repo.
English
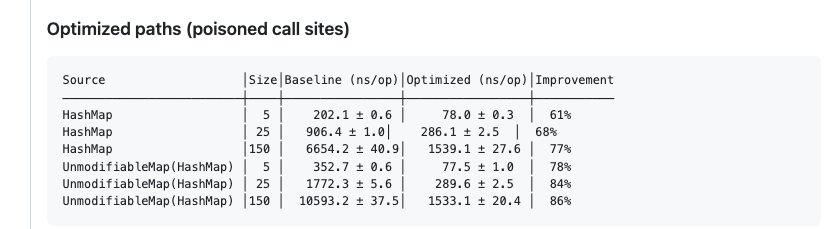
Significant `HashMap.putAll` improvement by adding a fast path for a couple of common cases.
English
Indonesia
I think many are surprised that multi-array allocations are very slow in OpenJDK, the following PR fixes part of it: github.com/openjdk/jdk/pu…
English
Ismael Juma retweetledi

QuestDB has a custom JIT: Java serialized SQL filters into Intermediate Representation and the IR is picked up by C++ backend, which generates native code: Scalar or AVX-2.
I prototyped a pure Java backend: It consumes the same IR, but generates Java classes with Vector API 🧵

English
@lemire @mrlesk @Love2Code Yeah, there are HotSpot specific gaps and general JIT constraints (limited budget).
That said, do you have examples of the target specific optimizations you have in mind?
Regarding the incubating Vector API, prod use cases are starting to show up netflixtechblog.com/optimizing-rec…
English

In my experience with .NET and Java, it will take the easy wins (like popcnt through an intrinsic). But it will not do target-specific optimizations like C++ compiler might.
It definitively detects at runtime the features of the CPU (so will a C++ compiled program through the system library).
The Oracle team has been working for a decade or some on Java Vector and though it got better (and is now quite usable), there are still large holes in it.
A lot of work goes into it. I am not (in the least) diminishing the accomplishments of the people writing JIT compilers. But they have various constraints.
English
When Apple moved from Intel processors to its own ARM processors, we did not know how they would handle all the existing Intel software. Then Apple shocked me with its software solution (Rosetta) that could transparently translate x64 binaries to ARM binaries. You just picked your old program, compiled years ago for an old CPU, and it just ran at high speed on a totally different CPU.
It seemed to have inspired Intel.
One problem when deploying software binaries is that you do not know anything about the processors your clients are using. They could be old CPUs taken from a trash can or the very latest Intel CPU.
Thus, when you compile your code, you often target a generic CPU. The net result is that you are not using the fancy features of the newest CPUs. This is especially true under Windows where people have a wide range of systems.
That’s frustrating if you are Intel or AMD: you have these new CPUs with features that most software will not use.
This is an advantage for systems like game consoles: if you know from the get-go which processor to target, you can optimize better.
There are ways around this issue for developers: you can check at runtime for the processor type and then select optimal code. Compilers provide some of this functionality by default. For example, they may have different memory copy functions and switch at runtime depending on the detected system. But compilers can only do so much, and developers do not have a strong incentive to optimize their software for specific CPUs. Doing such runtime dispatching is a lot of work and it complicates testing, thus increasing costs.
To make matters worse, nobody will tune their software for processors that are not yet available. Thus, old software may not benefit from more advanced features on newer CPUs. Sure, the developer could recompile the code, but it takes time and money.
A secondary but important issue is that compilers are often not great at optimizing even when you tell them which processor to target specifically. It is a matter of incentives: why should Microsoft put a lot of effort into making a family of Intel processors shine?
So Intel created something called iBOT (Intel Binary Optimization Tool). It optimizes x64 binaries on the fly. For now, it only works on a few popular games and only for some specific processors.
@tomshardware has a great article on the topic where they report an 8% performance boost on average, which is quite impressive given that it comes for free if you are the user.
Of course, Intel picked the few games where their techniques worked. How this scales is unclear. Intel keeps making new processors and there is a lot of software around. It would have been more impressive had Intel boosted the performance of software generally. Still: the idea is intriguing.



English
@lemire @mrlesk @Love2Code I was simply replying to the following part of your message "I don’t think JIT typically optimize for specific processor families. I could be wrong though".
I didn't compare it to C++ and certainly didn't intend to imply that it would produce faster code than C++ for games.
English
Java is fantastic and I teach Java for a living, as well as maintaining popular libraries...
This being said, the OpenJDK JIT compilers are NOT equivalent to a C++ compiler targeting a specific CPU family...
If you write your video game in Java, you are not going to get anything like the speed of a C++ program compiled for your specific hardware.
It would be fantastic if it were so.
English
@lemire @mrlesk @Love2Code OpenJDK has many PRs that reference specific families and enables/disables optimizations depending on the family. A very simple recent one is the following targeting Nova Lake: github.com/openjdk/jdk/pu…
Intel/AMD/ARM contribute directly in many cases.
English
See below for the processors Intel applied these optimizations to. Do you have evidence that the OpenJDK targets such specific CPU families?
OpenJDK, just like .NET, is poor at autovectorization compared to standard C compilers. So it does not do SIMD very well (if you compare with a C compiler).
There are constraints when build a JIT compiler compared to a static compiler.

English
@lemire @mrlesk @Love2Code Hmm, OpenJDK has a great deal of optimizations for specific processor families and instruction sets. Not sure if I am missing what you mean here though.
English
@mrlesk In theory, JIT solves all this but I suspect that it is more complicated in practice. I don’t think JIT typically optimize for specific processor families. I could be wrong though.
@Love2Code would know more about this?
English
Ismael Juma retweetledi


Ismael Juma retweetledi

io_uring easily beats AIO and gets faster with every kernel — until both suddenly get 30% slower.
Join a database developer’s unexpected journey into the Linux kernel and IOMMU.
medium.com/ydbtech/how-io…
English
"Make UseCompactObjectHeaders the default" github.com/openjdk/jdk/pu…
English
Ismael Juma retweetledi

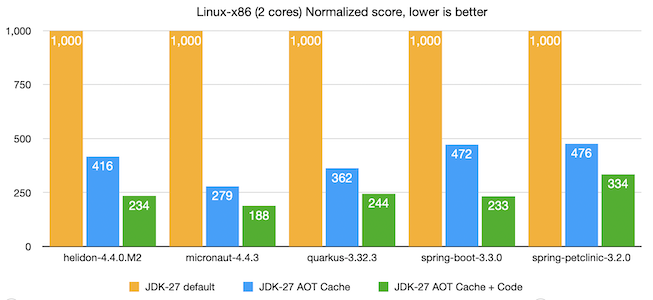
If you want to learn more about how we got a Quarkus REST app to start in 80ms on the JVM, have a look at the very detailed blog post we wrote with @geoand86 about Quarkus + Project Leyden. quarkus.io/blog/leyden-2/
English
Ismael Juma retweetledi

With the recent #ApacheKafka 4.2 release, the new "streams" rebalance protocol is production ready. It's exciting that it's also GA on Confluent Cloud now.
The cherry-on-top is, that our #KafkaStreams Cloud UI now also shows task assignment information for "streams" groups. \1
English