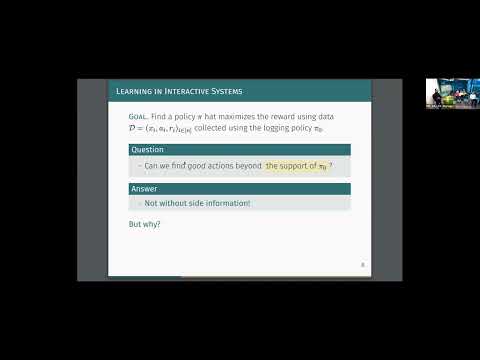
In summary: in large-action offline RL, trainability > perfect value estimation.
Check out the full paper for our theoretical proofs, deep dives into the optimization landscapes, and extensive ablations.
See you at #ICML2026! 🚀
English
Imad Aouali
52 posts

@imad_aouali
3rd-year Ph.D. Student @Criteo and @Ensaeparis/@CrestUmr. Previously MSc. @ENS_ParisSaclay, Applied Scientist @Amazon, Scholar @GoogleDeepMind.



@imad_aouali @OtmaneSakhi @VianneyPerchet @hr1ch3rd @CCalauzenes @NeurIPSConf 📍West Ballroom A-D #6206 ⏰11AM PST 🌟Spotlight Poster (top 2% of the submissions) 🗣️@imad_aouali @OtmaneSakhi 📝Logarithmic Smoothing for Pessimistic Off-Policy Evaluation, Selection, and Learning 🔗techblog.criteo.com/research-card-… youtu.be/8Od8i_HQel0?si…