Sabitlenmiş Tweet
Zhiran
179 posts


Zhiran
@imbue_byte
🧡🤍🩷💜 15岁 | Co-Founder @ Chunjiang Intelligence | AI/ML | DevOps | Quant | https://t.co/GSRfj5l7pR | 论文宣传与工作请看高亮
China Katılım Ağustos 2025
46 Takip Edilen93 Takipçiler
Zhiran retweetledi

这是我最重要的信息转发之一。
这篇论文的第一作者是我极为钦佩的人,也是我的好朋友,来自@Tsinghua_Uni 姚班顶尖选手Guowei Xu,现在他在@Harvard 进行人工智能大模型的科研工作。
Guowei这篇论文精准击中了目前LLM搜索的两个致命瓶颈:
① 只有最后一步对错的sparse verification
② 所有候选答案都靠自回归生成,永远困在模型自己概率分布的entropy shell里
由此,Guowei和他的团队提出BES这个全新的搜索框架,引入Forward Evolution,让大模型像生物演化一样思考,打破大模型原有的概率限制,逼它组合出平时根本写不出来的神仙脑洞。同时进行Backward Decomposition,把大任务拆成一堆一眼就能看出对错的子目标。这样大模型在往前走的时候,每走一步都有及时的Dense Feedback,走偏了立刻能纠正。
BES 在理论上成功证明了演化算子能帮大模型跳出思维定势,而倒推法可以指数级减少模型试错所需的样本量。
当目前主流的Post-training提升算法都失效时,BES 依然能带得动并且让模型能力持续输出稳定提升,这无疑是打破了主流算法的天花板,值得许多人关注学习。
我认为,Guowei这篇论文给Agent指明了新路。
对于现在大火的 AI Agent 任务流、多智能体协同来说,这种一边基因重组思路,一边倒推拆解目标的方式,提供了一套更高效、更不容易跑偏的底层搜索算法。
值得一提的是,@Kevin_GuoweiXu 同学不仅在清华姚班极其优秀,他曾经也是2022 年第 52 届国际物理奥林匹克竞赛(IPhO)的世界第一,金牌。他未来会在美国直博,大家可以多多关注follow!

Guowei Xu@Kevin_GuoweiXu
🚀 How should LLMs sample on hard reasoning problems during post-training and inference where direct rollouts rarely produce a correct answer? Best-of-N (e.g., GRPO) and tree search share two limitations: 🔻 Verification signals are sparse 🔻 Candidates stay within the model's own distribution We introduce BES: Bidirectional Evolutionary Search — a search framework that couples forward candidate evolution with backward goal decomposition. ✅ Works for both post-training and inference.
中文
Zhiran retweetledi











Zhiran retweetledi

A new way to pre-train language models that gives quite faster training.
Normal causal LLMs predict the next token t+1 But this method predicts a bag of future tokens: (t+1, t+2, t+3, …)
in a single step using token superposition.
Instead of learning exact next-token prediction early on, the model first learns broad exposure to future tokens and data distribution by averaging token probabilities through approximation.
The intuition is that early pretraining may not need exact token prediction, the model mainly needs exposure to language structure and data.
Since this is only a weak approximation, it doesn’t work for the entire training process.
So later, training switches back to standard one-token prediction.
This two-phase training surprisingly converges to similar loss with much fewer GPU hours.

English
Zhiran retweetledi

The Hessian matrix H(f) of a function f: Rⁿ → R is the n×n matrix of all second partial derivatives.
For f(x,y):
[ fxx fxy ]
[ fyx fyy ]
Definition:
[ ∂²f/∂x₁² ∂²f/∂x₁∂x₂ ... ∂²f/∂x₁∂xₙ ]
[ ∂²f/∂x₂∂x₁ ∂²f/∂x₂² ... ∂²f/∂x₂∂xₙ ]
H(f) = [ : : : ]
[ ∂²f/∂xₙ∂x₁ ∂²f/∂xₙ∂x₂ ... ∂²f/∂xₙ² ]
In compact form:
[H(f)]ᵢⱼ = ∂²f / ∂xᵢ∂xⱼ
Named after German mathematician Otto Hesse (1811–1874). Used to study curvature, convexity, and classify critical points in multivariable calculus & optimization.

English
Zhiran retweetledi


Zhiran retweetledi

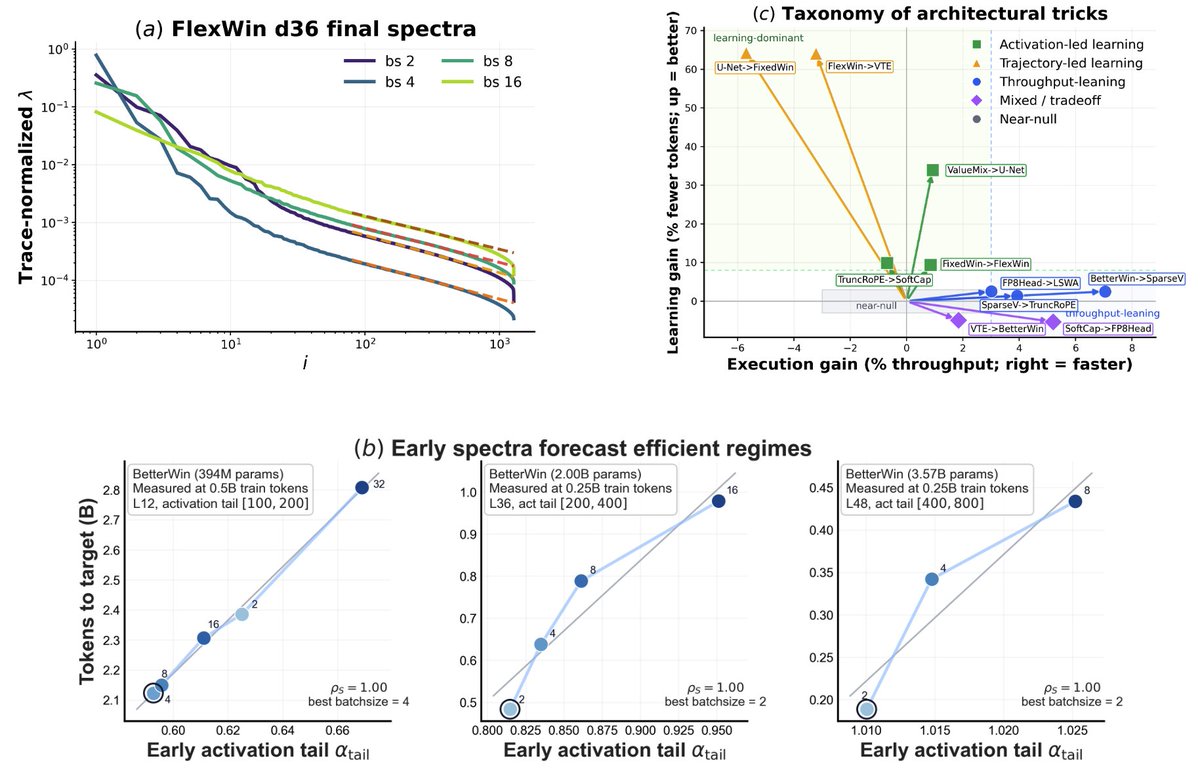
New paper: Spectral Lens
Loss curves can hide how LLMs actually learn. We show that activation and gradient spectra reveal hidden representation geometry, predict token efficiency early, and distinguish learning gains from throughput gains.
arxiv.org/abs/2605.05683
English
🌟 Open Source & Ready for the Edge. TidyLangChain is distributed under the Apache 2.0 license. If you are building the next generation of Edge AI, hardware agents, or smart IoT devices, check it out!
Drop a ⭐ on GitHub and let us know what you build! ⚛️ 👇
github.com/imbue-bit/Tidy…
#EdgeAI #IoT #EmbeddedSystems #CProgramming #LLM #LangChain #Microcontrollers
English
