Imane Momayiz retweetledi

Imane Momayiz
22 posts







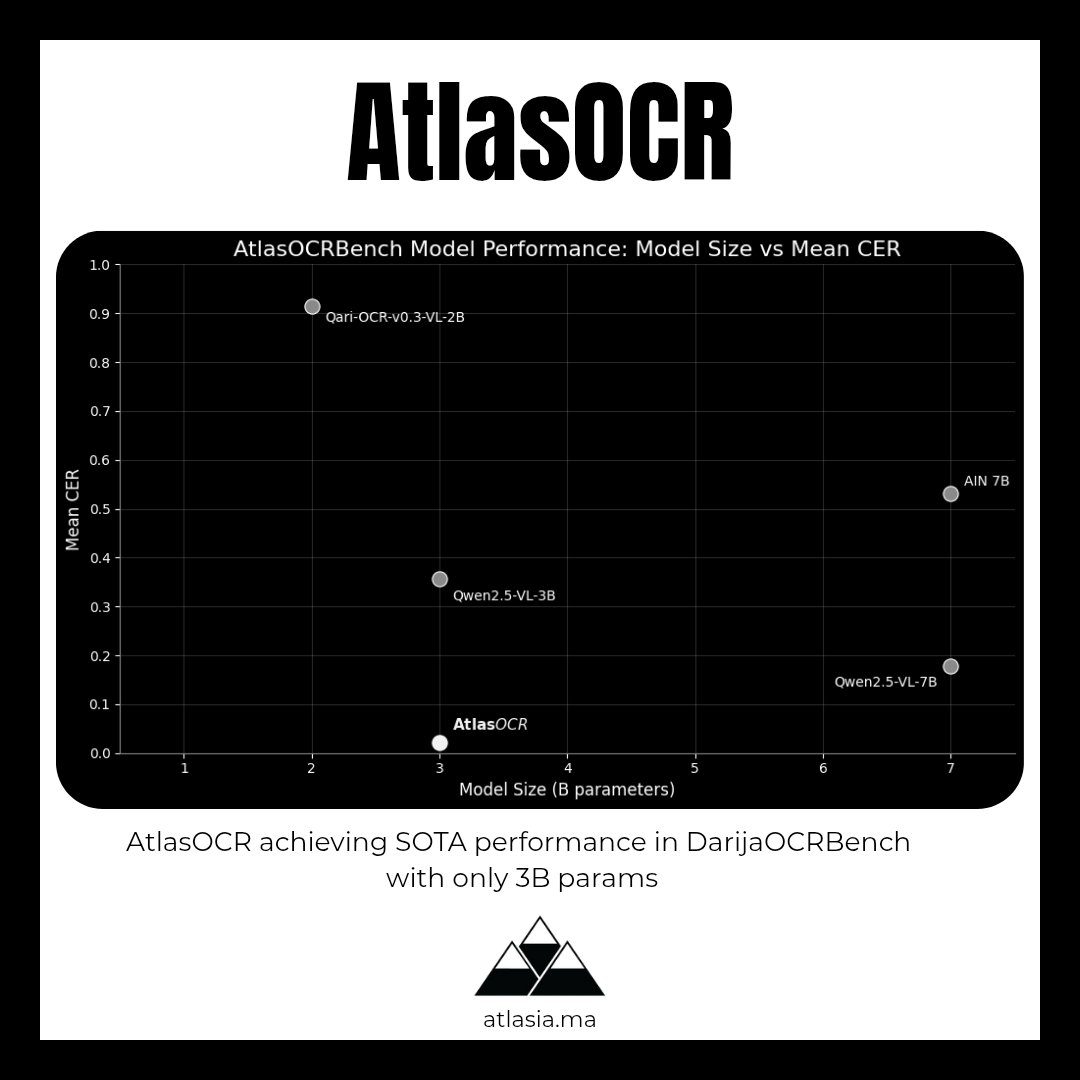
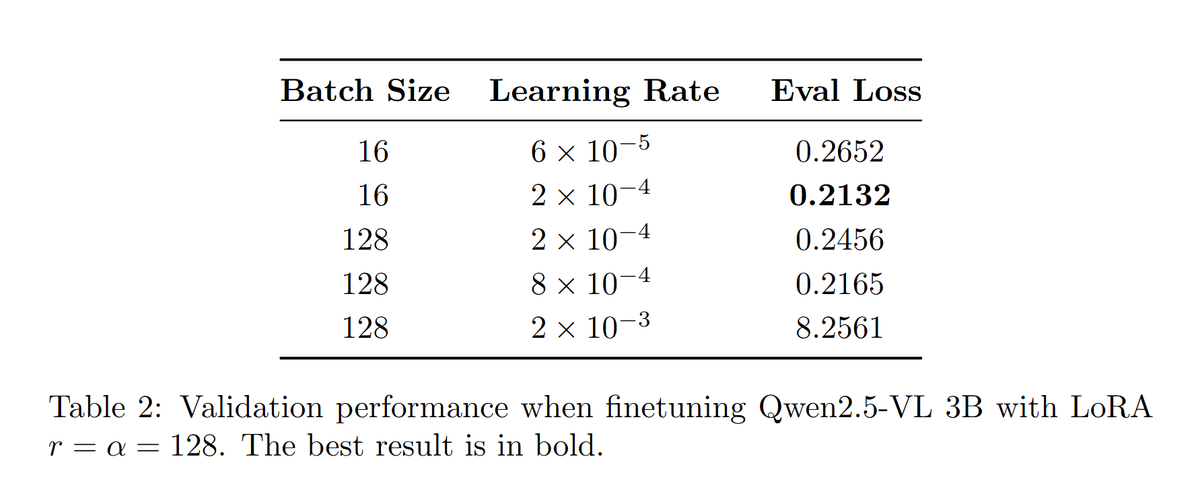
We just shipped #AtlasOCR - the first open-source #OCR model for #Darija (Moroccan Arabic) 🇲🇦 Here's what we built: → Fine-tuned Qwen2.5-VL 3B on 30K Darija samples → Trained on 10M+ words of real Moroccan text → Used QLoRA + @unslothai for crazy efficient training