Sabitlenmiş Tweet

以前刷推特,看到的都是国外大模型怎么怎么厉害,现在反过来了,老外在问"How to use Seedance 2 model?" 在推特上也能看到很多老外都在用Seedance 2做出好看新奇的视频。
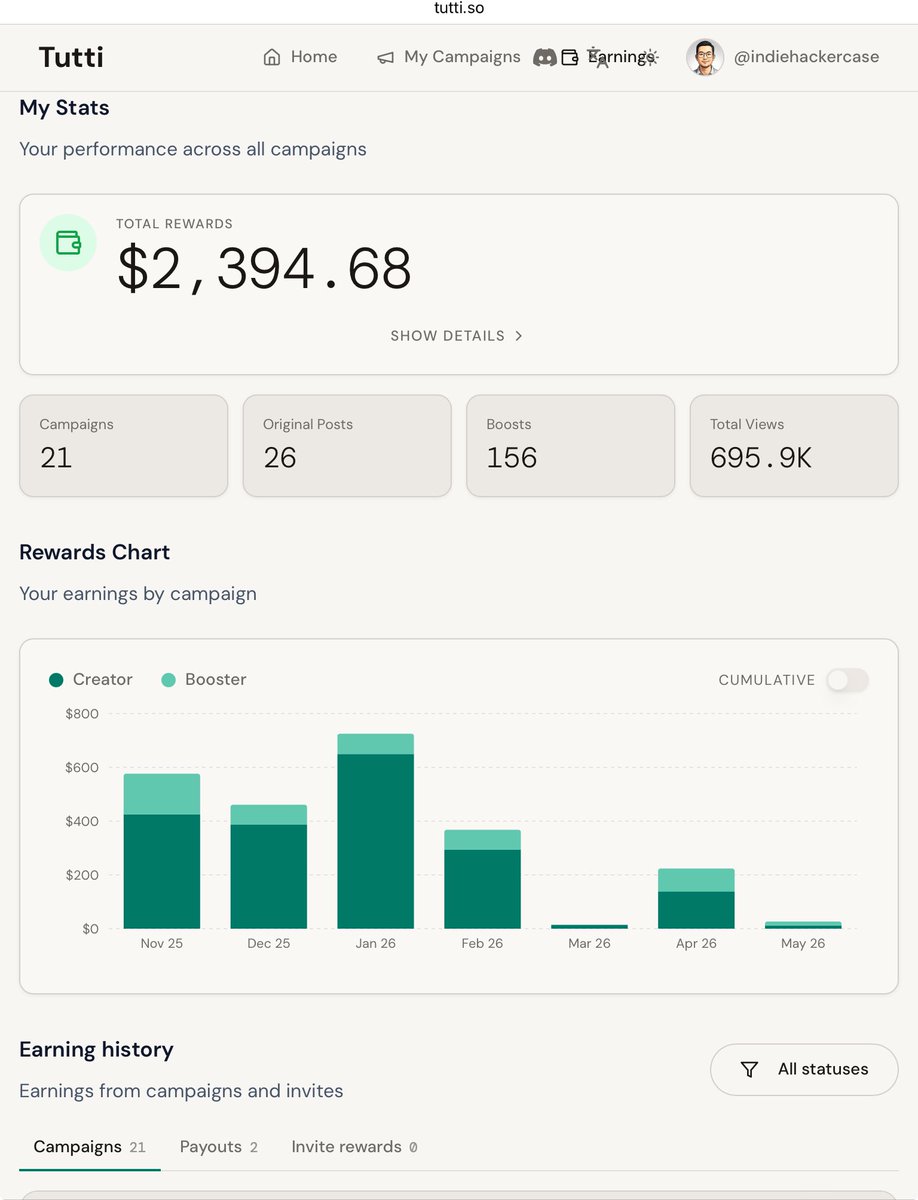
中国大模型的崛起真是肉眼可见。最近阿里的万亿级深度推理模型Ring-2.6-1T,在 PinchBench 上把 GPT-5.4 和 Claude-Opus-4.7 都干翻了,首创双档可调节推理强度,high 适合高频 Agent 工作流、低 Token 开销适合生产级调用;xhigh 模式则为数学、科研等高难任务提供充分推理空间。
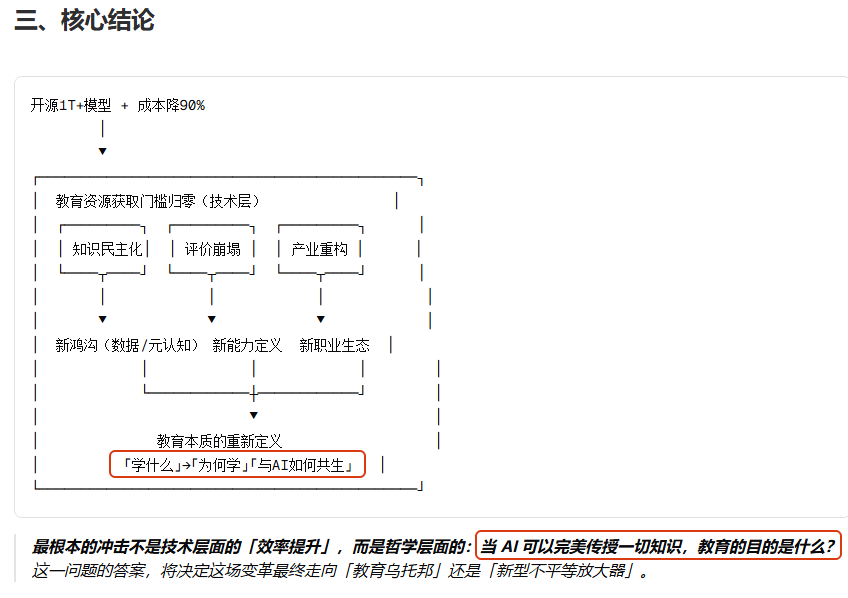
我问它,“假设一个平行世界:2025 年所有大模型都开源 1T+ 参数,但计算成本下降 90%。推演这会对教育产生什么连锁影响?” 它从短期到长期,从教师、教管、教材到学科格局,最后甚至发出哲学追问:当 AI 可以完美传授一切知识,教育的目的是什么?(见图)
现在 OpenRouter 限时免费。赶紧去薅!openrouter.ai/chat


中文