Sabitlenmiş Tweet

Catalyst is live
built for teams shipping agents in production
train & deploy frontier LLMs in minutes, using the data your application is already generating
Get Started: docs.inference.net/introduction
Sam Hogan 🇺🇸@samhogan
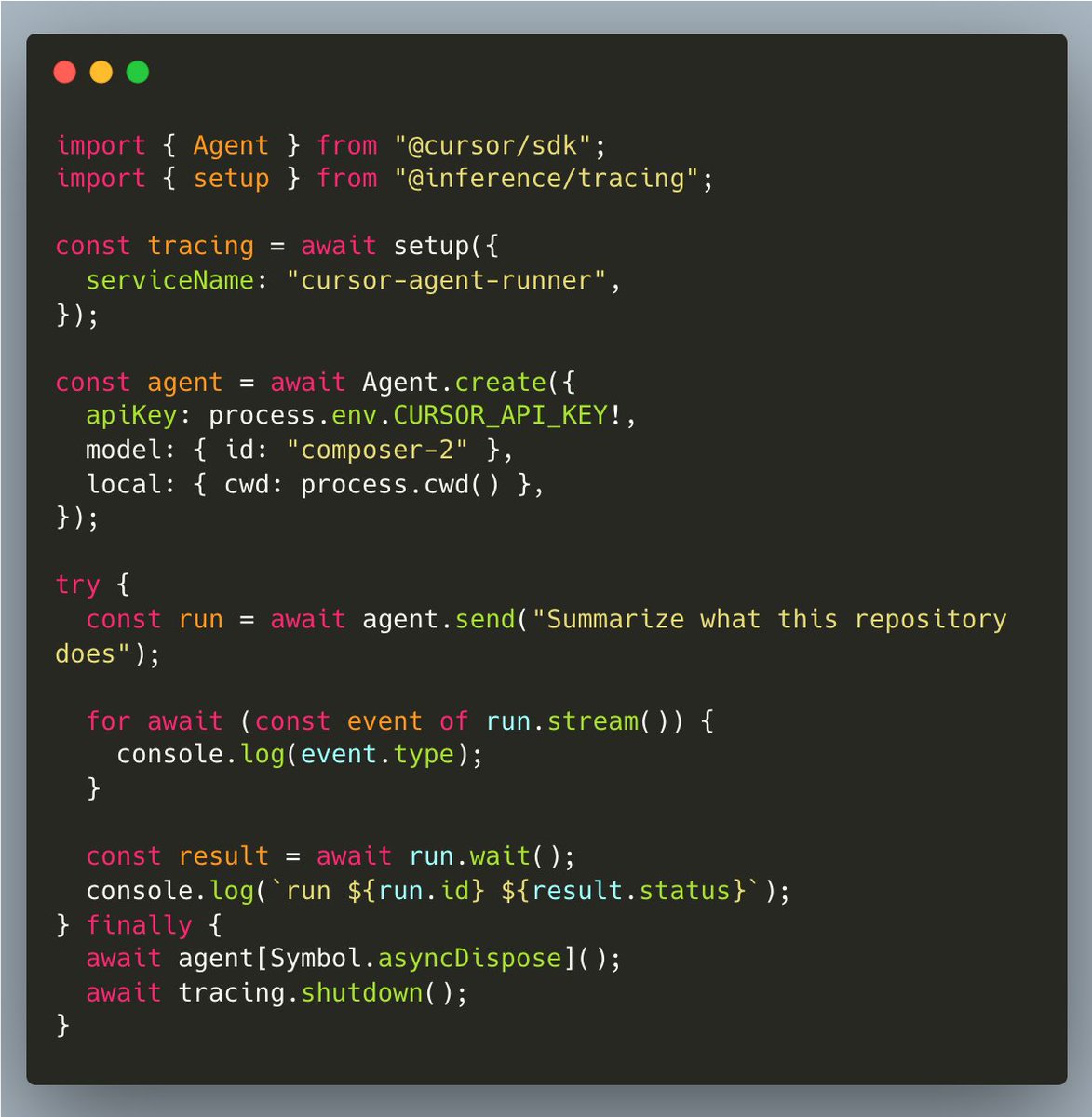
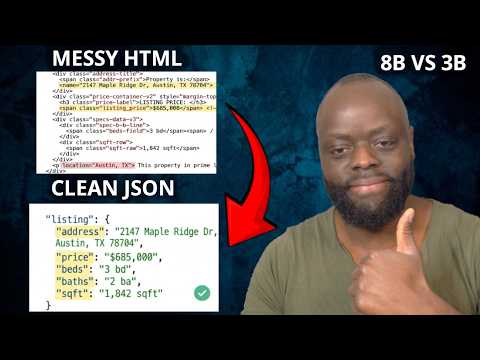
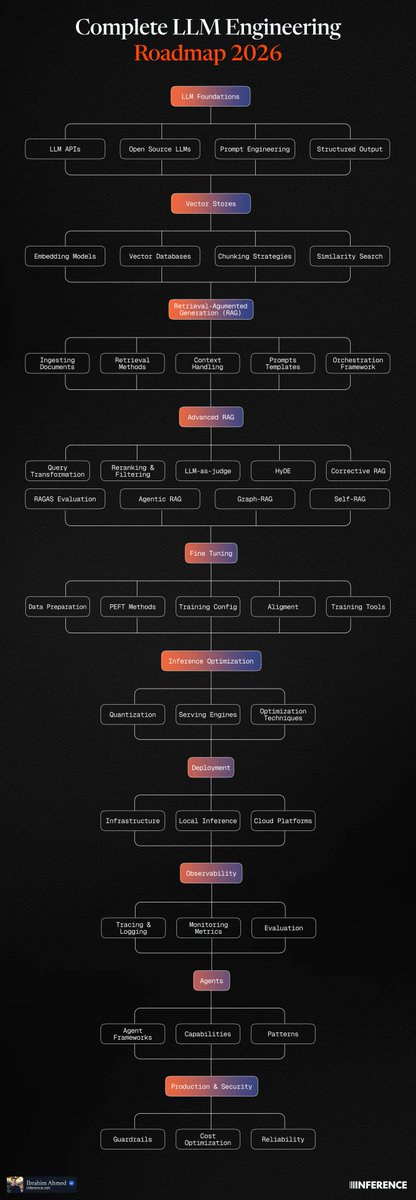
Introducing Catalyst: a developer platform to monitor, train & deploy self-improving AI models built for teams operating AI products at scale Catalyst can automatically: - collect traces from your agents - curate training data & evals - train & deploy models on par w/ Opus 4.6
English