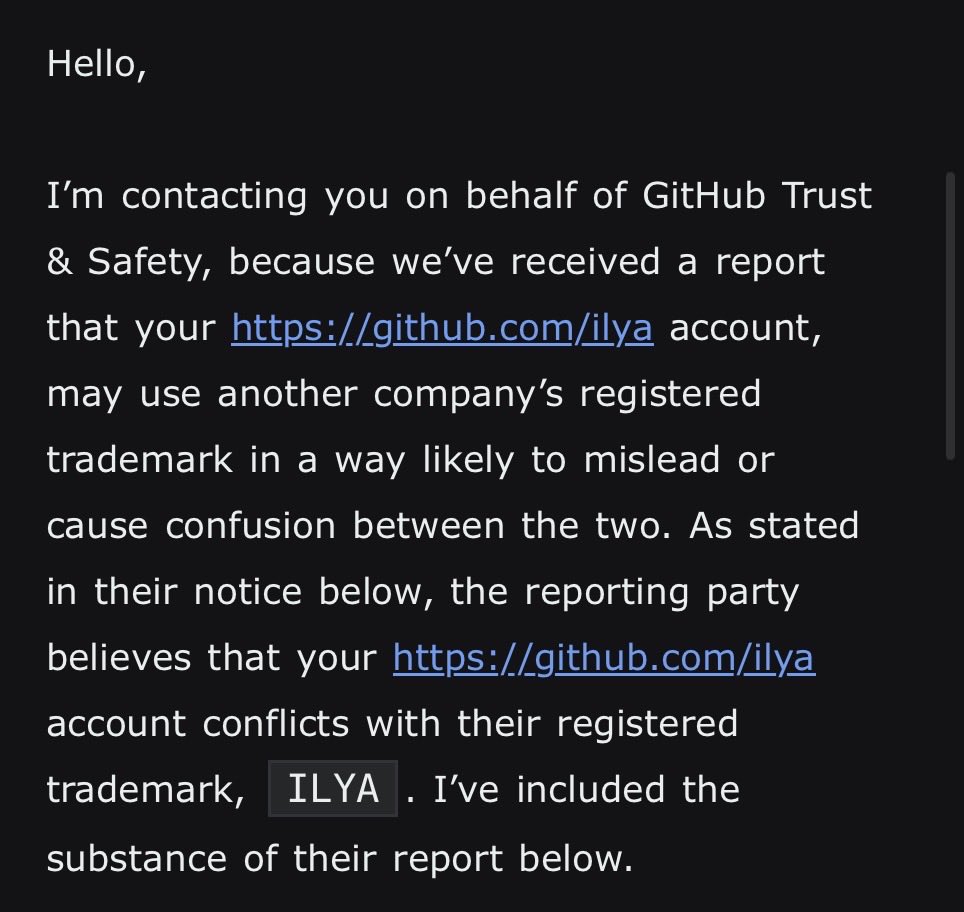
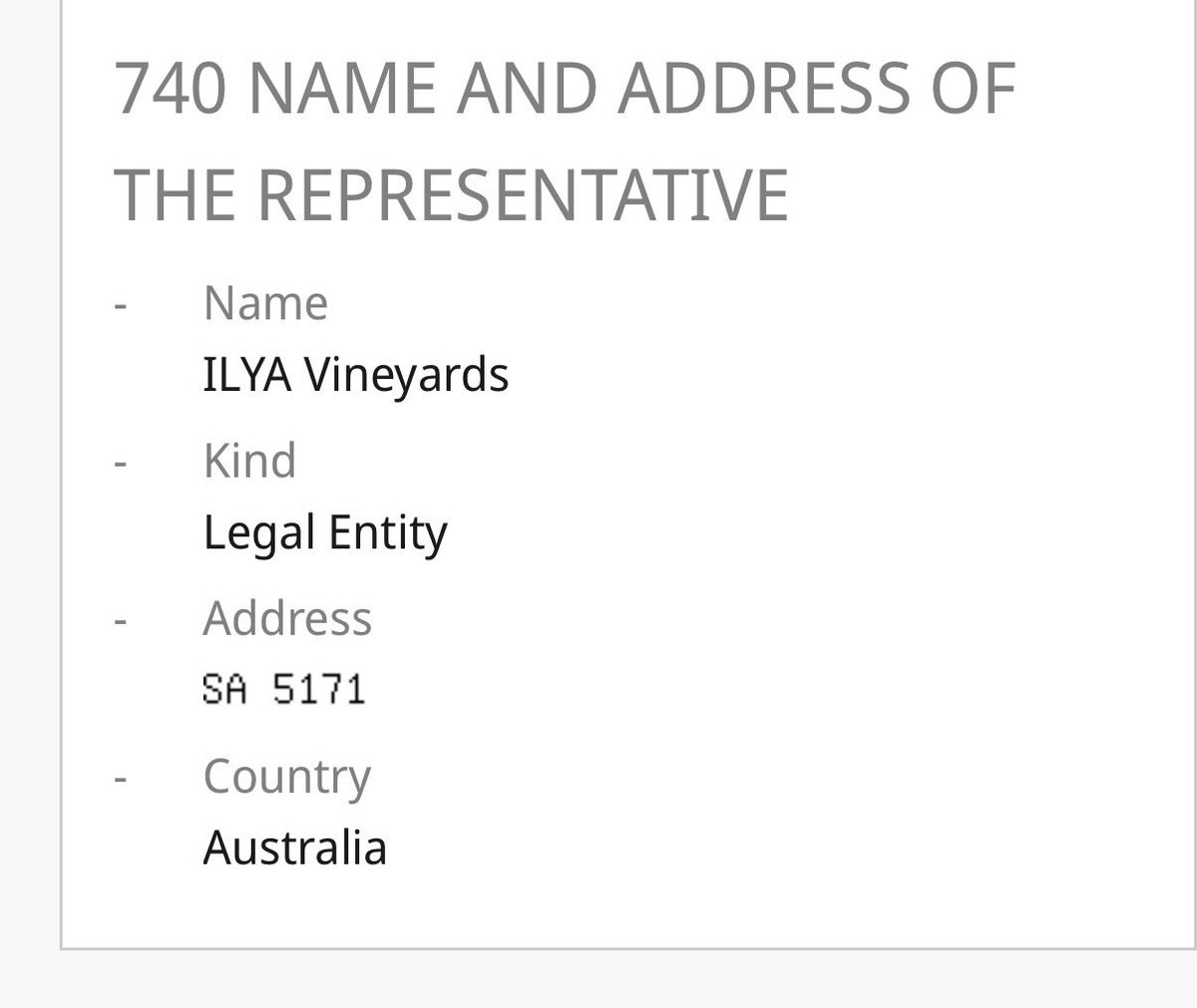
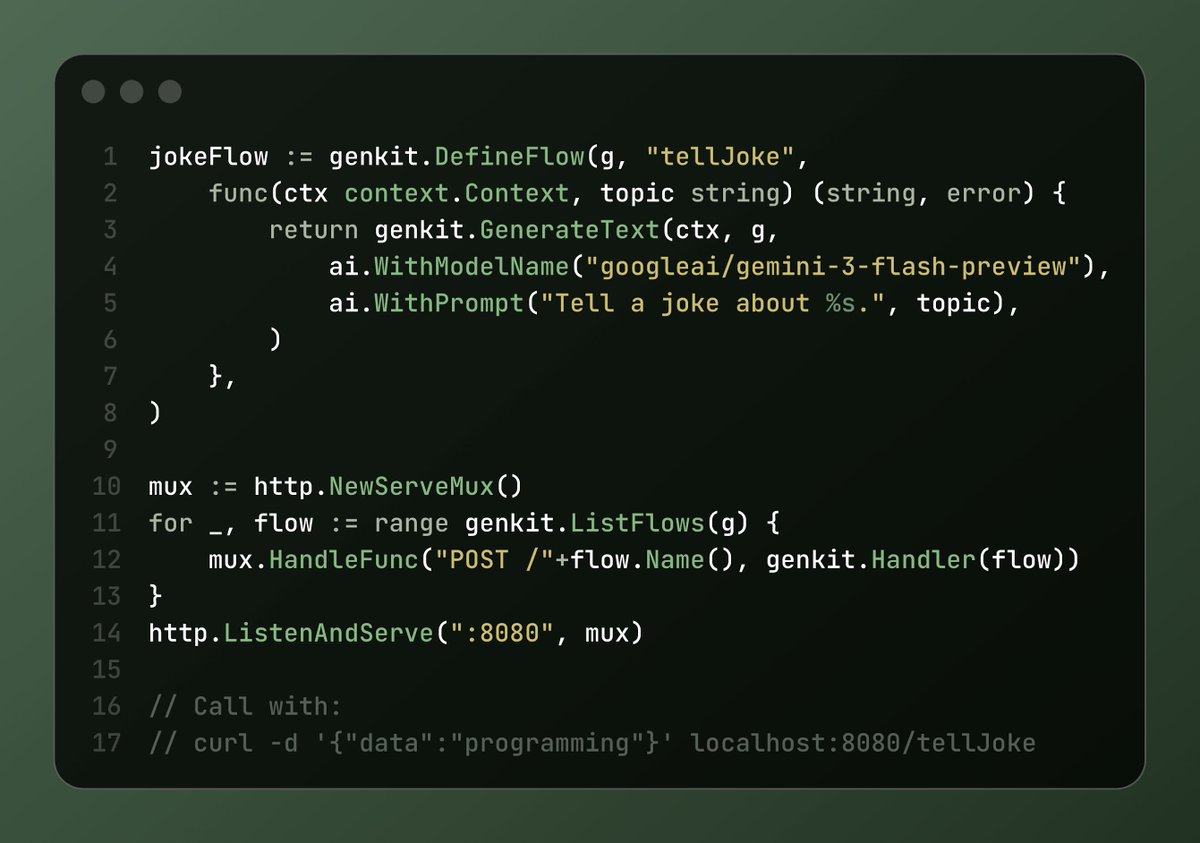
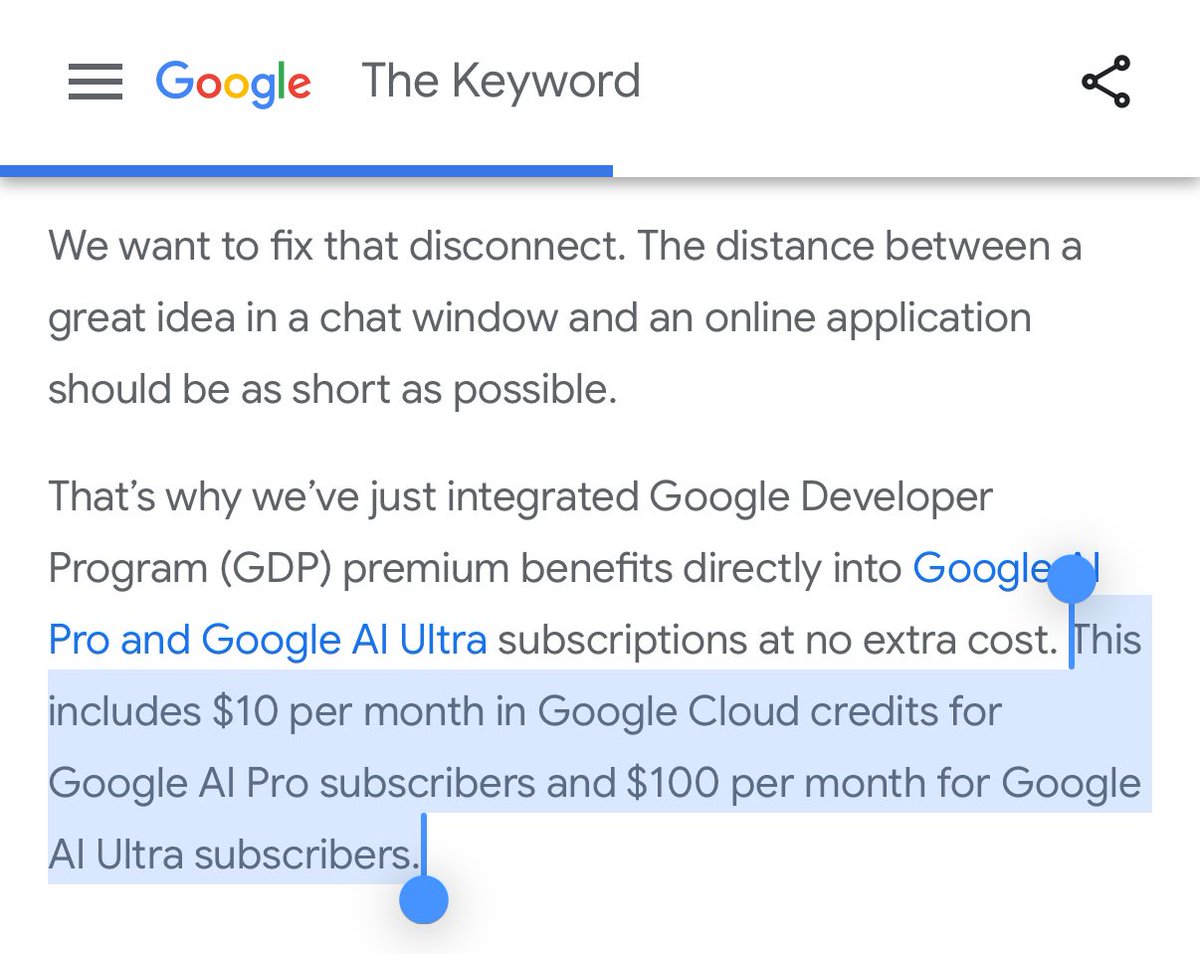
Sabitlenmiş Tweet

🎉 So @firebase launches 🚀
💻 Firebase Studio - a GenAI powered web based IDE powered by Gemini
🌏 Firebase App Hosting General Availability
🤝 Firebase Data Connect General Availability
🤖Genkit Beta for Golang and Alpha for Python 🐍and a prod monitoring dashboard
👇🧵 1/12
English