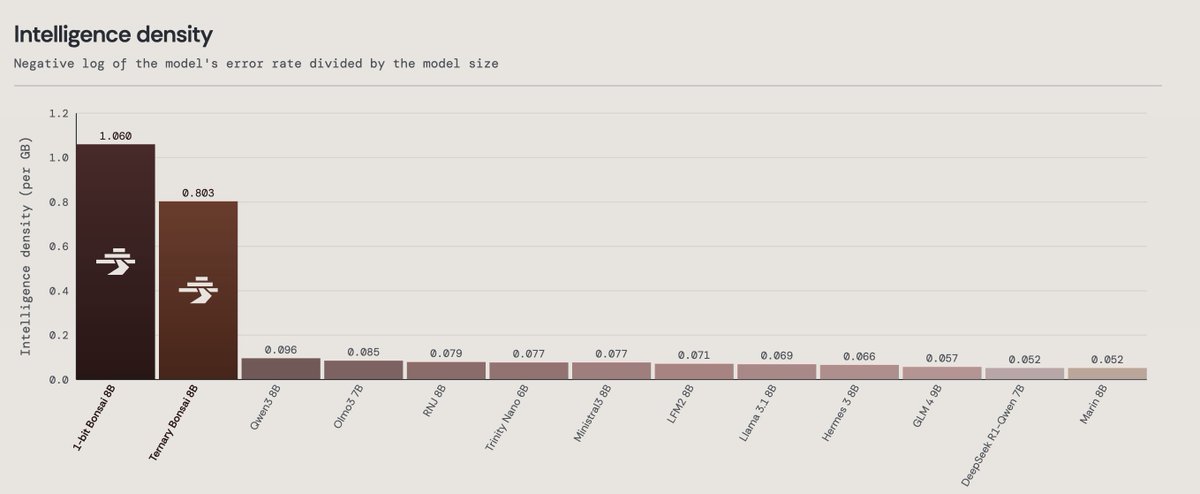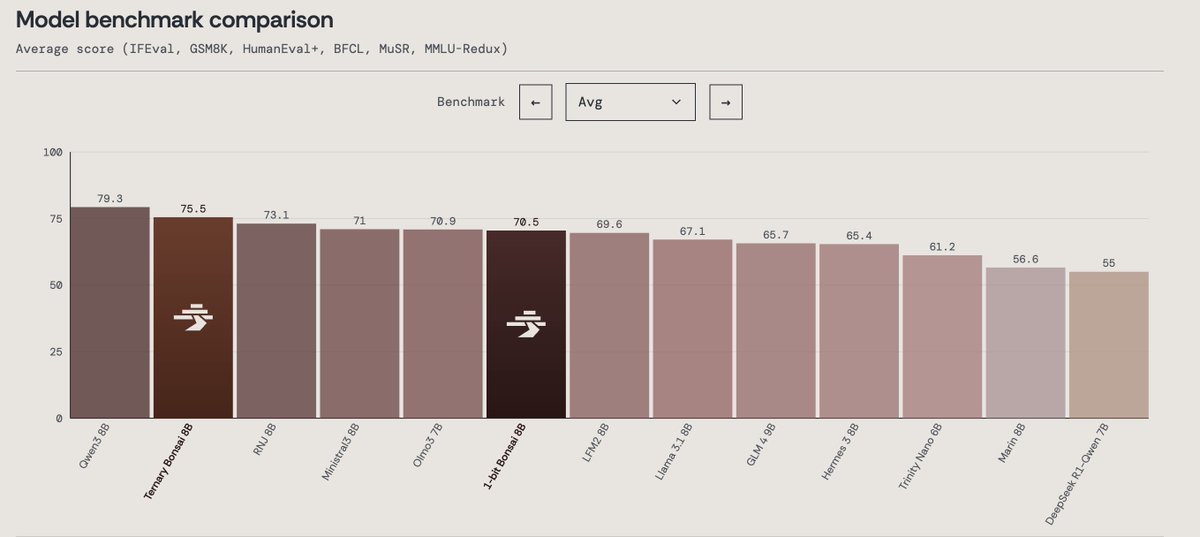

If a 150gb size model is delivered at 1.58 bits would it rival a trillion param model ?
If yes World would be a different place, suddenly the energy and compute bottleneck would be solved.
But more importantly a true physics aware world model requiring 100s of trillions of params would be possible. Robotics projects would achieve what they want to. Manufacturing abundance era would arrive. And more importantly the abundance would arrive before unemployment skyrockets due to current scenario.
Most positive impact would be on jobs, suddenly every small employer cutting on job would be on a hiring spree, because playing field would be leveled. Every small startup can aspire to be self sufficient with intelligence. Democratization of Ai would be a reality not just conference talks.
Edge devices would be capable of defending themselves from mythos orchestrated model threats.
Govt funds would be spent on pubic infrastructure and national security rather than energy and compute.
Nature won't be scortched for Resources like water, etc. There can't be anything holy than this.
All of this may sound far fetched but starts at mere 14 gb and 21 gb size models at this intelligence density.
English