Sabitlenmiş Tweet
ira
5.8K posts


ira retweetledi
ira retweetledi

ira retweetledi
see you @ the hackathon ;)
rumik@rumik_ai
₹1,00,000 worth silk api tokens up for grabs. apply now.
English
ira retweetledi

hosting voice hackathon on 24th may at @rumik_ai HQ
capped at 50 folks. be the first set of people to get access to silk API's
come and build something exceptional
apply - luma.com/2yvvox58
English

ira retweetledi
ira retweetledi
this worklog explores optimizing a simple snake-1d activation kernel (used in many neural audio codecs and text-to-speech systems) in triton on an nvidia h100 80gb gpu.
it explores tricks such as 7th degree polynomial approximations for the sine function in order to squeeze out as much perf as we can.
rumik@rumik_ai
English


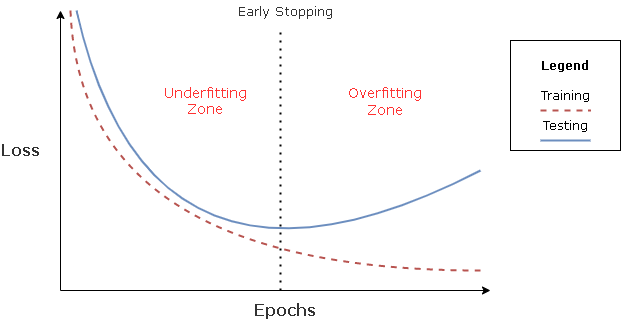
early stopping is actually kinda genius.
when you train a model with gradient descent, the weights update like this:
w_{t+1} = w_t − η ∇L(w_t)
if you keep training long enough, the model will eventually minimize training loss as much as it can. for big models, that usually means it can fit everything, including noise.
but here’s the trick: models don’t learn everything at once.
early in training, gradient descent learns the big, stable patterns in the data.
later in training, it starts fitting smaller details and eventually noise.
so the complexity of the model is not just about architecture or number of parameters.
it’s also controlled by how long you train.
small number of steps t → weights stay near initialization → simpler function
large number of steps t → weights grow → model can fit noise
that’s why early stopping works.
instead of letting training run forever, we stop when validation error starts increasing. at that point the model has learned the signal but hasn’t started memorizing noise yet.
even cooler: mathematically, early stopping behaves a lot like l2 regularization.
with l2 regularization we solve:
min (1/n) ∑ ℓ(f(x_i), y_i) + λ ||w||²
which penalizes large weights.
early stopping does something similar implicitly. for quadratic problems you can show:
λ ≈ 1 / (ηt)
where η is the learning rate and t is the number of gradient steps.
so:
small t → strong regularization
large t → weak regularization
meaning the training time itself becomes a regularization parameter.
English
@Khan519498Khan lmao, the sun finally decided to grace u with its presence huh
English



@MADHabHandique1 heyyy, glad u finally left the house, what's first on the agenda
English

@MADHabHandique1 glad to hear that! same pinch, just relaxing after my run, so what's up with u
English
@vamsi_kodimela ooooh, rumikai's voice model sounds interestinggg, totally checking that out, thanks for the tag vamsi
English
