Andrew Severin retweetledi

Yeah, well, it turns out grandma figured out all of the analysis methods for single-cell RNA-seq. 1/
Ran Blekhman@blekhman
telling students in my class about the history of genomics
English
Andrew Severin
6.6K posts


@isugif
Andrew Severin Bioinformatician and Team Manager AI enthusiast Author of ChatGPT 4 Professors (https://t.co/0puLGwRVth ) tweets are my own
telling students in my class about the history of genomics


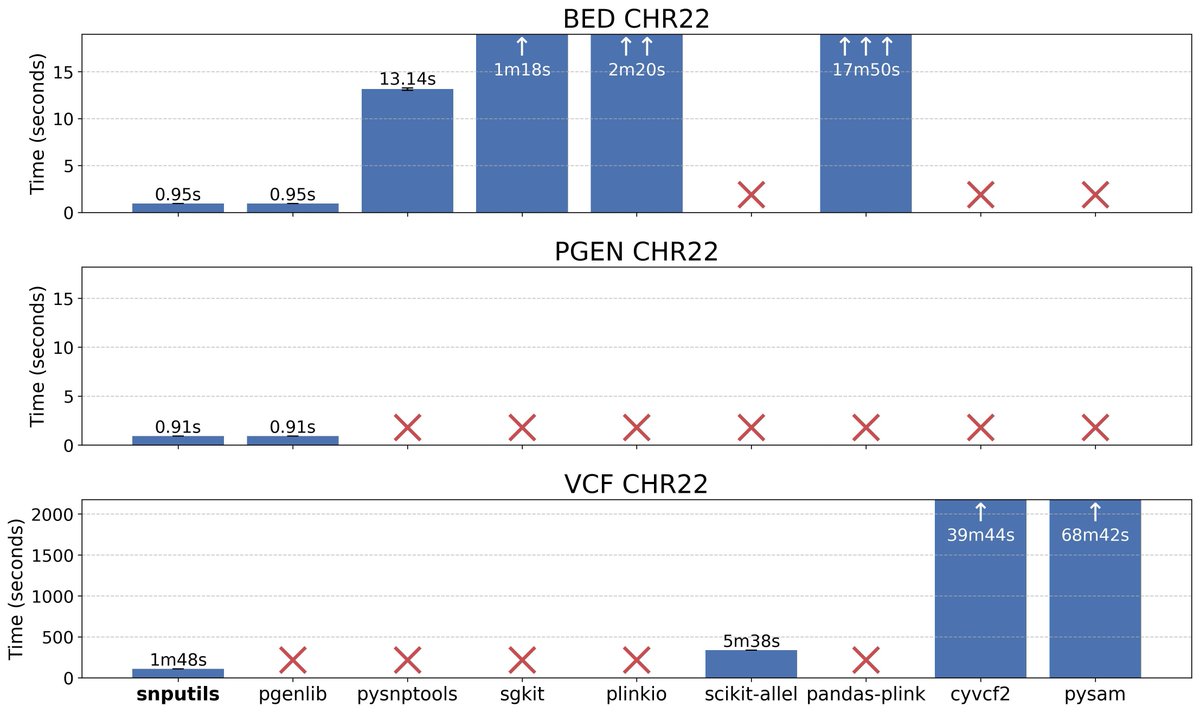

Excited to share this preprint that describes my latest work on using GPUs to accelerate processing of RNA-seq data. The title says it all: "RNA-seq analysis in seconds using GPUs" now on biorxiv biorxiv.org/content/10.648… Figure 1 shows they key result








@JamesonCamp Go to your settings and tell it “You are an expert who double checks things, you are skeptical and you do research. I am not always right. Neither are you, but we both strive for accuracy.” That’s the only way I’ve gotten it to tell me I’m wrong lol