Sabitlenmiş Tweet

☁️ Arthur is now available in @googlecloud !
Many of our customers are building on Google Cloud and leveraging the latest Gemini and agent frameworks, so we partnered with Google to make Arthur available directly within your GCP environment. This means data never leaves your GCP environment, procurement is seamless through the Marketplace, and deployment fits naturally into your existing workflows and stack.
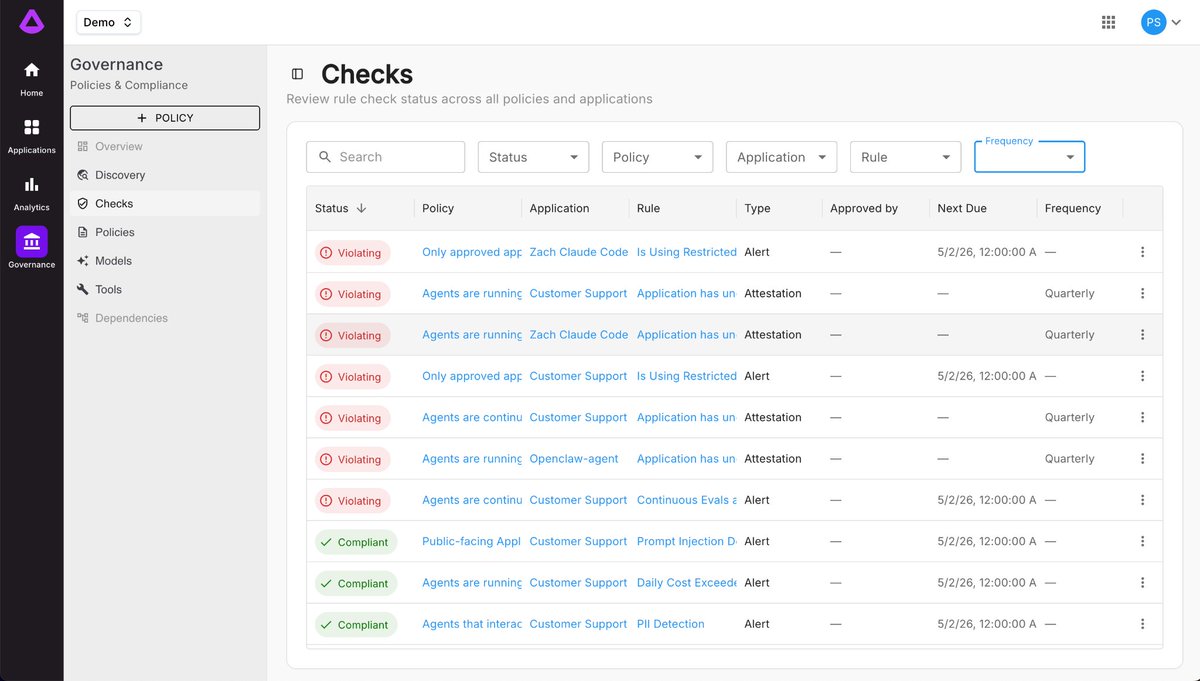
With the explosion of agents, teams lose visibility into which agents are running and lack insight into failures. As enterprises race to adopt Agentic AI, a comprehensive agentic governance approach is crucial to preventing chaos, security nightmares, and business continuity issues. That’s why we launched Arthur’s Agent Discovery & Governance (ADG) Platform on Google Cloud.
With Arthur on Google Cloud, you can:
🔍 Automate Discovery: Instantly find and catalog agents company-wide
📈 Unify Monitoring: Monitor and govern internally-developed and third-party agentic solutions
🛡️ Centralize Policy Management: Enforce acceptable use and security policies for all agent interactions
🔄 Continuously Evaluate: Monitor performance aligned specifically to agent tasks
Read full announcement → arthur.ai/blog/arthur-la…

English