Varun tej
234 posts

Varun tej
@itsvaruntej
well, what are you looking fa?👀
Katılım Mayıs 2018
199 Takip Edilen58 Takipçiler

Canceled my Claude Pro a week ago (tho the current plan is till 21st of this month) to test GPT 5.5 for a month. Today when i was outta usage for a session, I thought why not pick a max subscription to see how much i can ship. After weighing Claude vs Codex (for half-hour), I dropped $100 on Max for the first time since launch, specifically to push Fable 5 hard and ship a project fast.
After a outstanding first session, first thing Claude Code shows me: "Claude Fable 5 is currently unavailable. Please use Opus 4.8 or another available model."
I paid $100 today for a model I cannot use. @claudeai, refund or credit everyone who subscribed today expecting Fable access. Charging full price for a flagship that errors out on day one is not acceptable.
#ClaudeGated #ClaudeCode #ReturnMyMoneyBack #NoMoreFable #MythosIsAMyth #Anthropic

English


English
For the last few weeks I've been understanding NKI, AWS's kernel language for writing custom ops on Trainium and Inferentia. just submitted my first kernel to the nki-samples repo: a decode-step attention kernel with GQA. A few things that clicked along the way: >Firstly, Decode attention is memory-bound, not compute-bound. Generating one token is tiny math (a single query), but it re-reads the entire growing kV cache every step. So the whole design is about touching K/V memory as few times as possible, not about FLOP.
> Grouped-query attention is a direct win here. When several query heads share one KV head, you load that K/V tile once and let the whole group ride on it. On a memory-bound kernel that saves exactly the thing that costs you.
>Online softmax is what lets you stream the KV cache in tiles instead of holding every logit at once. You carry a running max, denominator, and accumulator across tiles and rebase as each new tile arrives. Same answer, bounded memory.
> The hardware model is genuinely different coming from CUDA: matmul results can only exit through PSUM (a tiny accumulator), so you immediately evacuate to SBUF to free it for the next matmul and to let the softmax engines read it. It is validated on CPU against a NumPy reference, not yet on real Neuron hardware (just not yet).
> Next up: the split-KV flash-decoding variant for long context.
If you work on Neuron, NKI, or inference kernels, I'd love feedback on the approach.
#AWSNeuron #Trainium #Inferentia #MLSystems #NKI #KernelProgramming #Kernels #DecodeAttentionWithGQA
English

Claude Fable 5 is by far the most ridiculous model that makes me genuinely afraid for the future of software engineering.
I compiled the top 10 most unbelievable things I've seen Claude Fable 5 do today:
— Migrate a 50M line codebase from Stripe in a day (humans take 2mos)
— Draw amazing 3D graphics a) Boeing 747 b) space simulations with >5000 objects c) Minecraft roller coasters d) full photorealistic forest scenes e) NYC skyline f) stormy clouds)
— One-shot Pokemon FireRed the game
— Optimize a real world proprietary interaction net evaluator 10x more than the next best model, gpt5.5
AND it's about the same price as GPT 5.5 ($10/M input, $45/M output) vs Fable 5 ($10/M input, $50/M output) and 6x cheaper than GPT 5.5 Pro.
English
@rohanpaul_ai @sama earned my respect for this. Yes, companies failed to articulate what they're building and just portraying that they achieved SOTA models to get more funding.
English

Sam Altman's new interview: AI should not be designed to pursue goals that are disconnected from human needs. People must remain at the center of AI development.
“I have no interest in building a super-smart AI that accomplishes some non-human goals. People should react. People should say, ‘Hey, this is what I want, and this is what I do not want.’
I do not think the issue is that we have failed to explain the benefits. We say, ‘AI is going to cure a bunch of diseases,’ and people say, ‘Okay, that is great, but that is not really my question. My question is: What is my role in the future? What is my economic future? What is my agency? How do I know that my kids and my family will still be able to have fulfilling, creative expression, struggle, drive the world forward, grow, and do this thing together in a way that has worked for a long time?’
When people in AI say, ‘Sure, there are going to be no jobs,’ or ‘50% of jobs are going to go away,’ or ‘90% of jobs are going to go away,’ and ‘AI is going to be smarter than you at everything,’ and ‘We will give you some basic income, but you are not really going to have a role,’ that is horrible.
And by the way, if an AI company says, ‘Maybe we are going to destroy all the jobs, and we will be the most valuable company in the world,’ people should look at you like, ‘Yeah, that is a terrible message.’
I do not think the problem is that we have not articulated the upsides. I think people actually believe us. They hear, ‘AI may cure your cancer,’ and they think, ‘That sounds great.’
I think we, as an industry, have failed to explain how people stay in control of determining the future at every step, and how people can still have a meaningful life in all the ways we care about.”
----
From "CNBC Television" YouTube channel, (link in comment)
English
Just added a new skill and unleashed Opus 4.8 on my codebase.
Download Flutter and Dart agent skills by running:
npx skills add flutter/skills --skill '*' --agent universal
npx skills add dart-lang/skills --skill '*' --agent universal
#HappyShipping

English
@dwarkesh_sp Why don't you bring @joerogan? He talks about aliens while you talk about AI
English

Who should I interview on my podcast?
Open to more AI, but also to random history/econ/etc professors that I might not have heard of before.
English

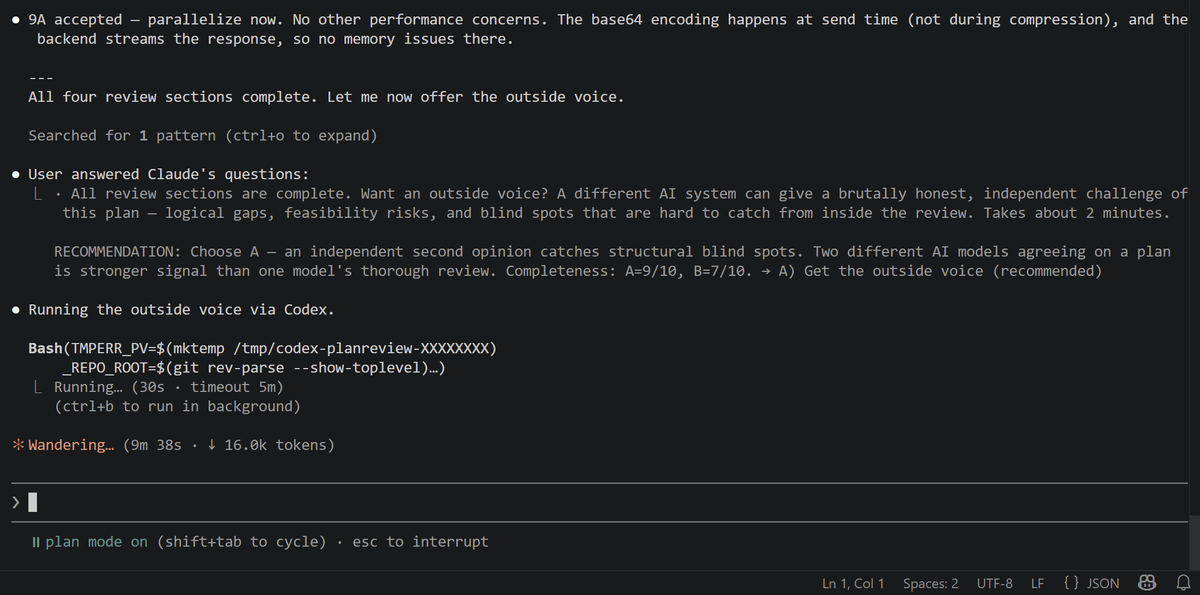
wasn't expecting this from Claude using Codex to get opinion of the plan.
#ClaudeandCodexTogether #ClaudeCode #Codex
English
Uninstalled Antigravity right after this update. You don't update app specifically for vibe coders who doesn't give a f about how the code is and just tell what to do to AI. I was using Antigravity because of its excellent auto complete feature ability to detect changes. But this update sucks, you already had Gemini and now you made Antigravity Gemini-2. When I asked agent in the antigravity on how do I look at the files to edit or make changes it said to use another IDE pshhhh... Maybe idk what's on their mind but I'm not impressed.
English

Introducing Antigravity 2.0, a new standalone desktop application that delivers fully on that original glimpse of a truly agent-optimized experience.
Rebuilt from the ground up with multi-agent teams, scheduled tasks, native voice and one-click integration with other Google products.
Learn how to get started with Antigravity 2.0 👇
English

8 rounds. 6 hours in-person. Rejected.
I presented a full hour of tradeoff analysis with a POC covering across AI tool dynamics, product architecture, and scaling strategy. That is not an interview answer. That is consulting.
At some point the interview process itself becomes the red flag. If a company needs 8 rounds to decide, the problem is not the candidate. It is the rubric.
No names. No bitterness. Just a question worth asking: when did hiring become an endurance test instead of a signal detection problem?
English
@karpathy Hear two voice agents debating/arguing live in real time pocketpanel-production.up.railway.app
English

- Drafted a blog post
- Used an LLM to meticulously improve the argument over 4 hours.
- Wow, feeling great, it’s so convincing!
- Fun idea let’s ask it to argue the opposite.
- LLM demolishes the entire argument and convinces me that the opposite is in fact true.
- lol
The LLMs may elicit an opinion when asked but are extremely competent in arguing almost any direction. This is actually super useful as a tool for forming your own opinions, just make sure to ask different directions and be careful with the sycophancy.
English
Varun tej retweetledi
