I bought a Youtube channel last year for $10k, when I was $70k in debt. This month alone it made $10k
The channel is now worth over $180,000, a %1800 return.
@leopoldasch recruit me.
Considering FIFA world cup is around the corner, this asset is a gold mine. I predict the revenue to reach $13,000 per month, easily.
The asset is now worth $180,000, which is a 18x return, or %1800.
For reference:
• March: $7,300
• April: $7,200+
• Past 28 days: $8,400, highest revenue period in channel history
• Upload frequency: roughly once every 1–3 months
• Majority of revenue (98% of revenue) still comes from videos uploaded back in 2022
Last year, i was $70,000 in debt, and bought a YouTube channel with my remaining $10,000 when it was making essentially $0 because the previous owner had stopped uploading and the channel had gone inactive.
My thesis was that if I reactivated the channel, the evergreen library would start getting pushed by the algorithm again (my thesis was right)…
Do not start a company if you're primarily driven by:
- Making money
- Getting famous
- Doing better than others
- Calling yourself CEO/founder
Only do it if you're crazy enough to do whatever it takes to solve a problem you deeply care about
If you’re building RAG pipelines, test this idea.
Treat vectors as a fallback, not the foundation.
You’ll cut latency, reduce cost, and make your system actually think.
The more your system is used, the more queries start to repeat.
Different wording, same content.
Caching that intelligently saves massive LLM cost over time.
I built a hybrid retrieval layer for RAG/AI agents that makes vector search the last resort.
Most RAG stacks jump straight to embeddings while ignoring the two things that actually make retrieval efficient, semantic/non-semantic caching and BM25 keyword search.
ValeSearch routes queries through cache → semantic cache → BM25 → rerank → vectors only when confidence is low (cosine setup with my testing but it can differ)
In early tests on a 9-figure real estate company’s internal RAG setup, on paper it proved to cut 70% of queries before they ever touched the LLM, in the long run.
Repo’s still unfinished, but everything is in the readme for a better understanding.
github.com/zyaddj/vale_se…
𝗔𝗜 𝗔𝗴𝗲𝗻𝘁’𝘀 𝗠𝗲𝗺𝗼𝗿𝘆 is the most important piece of 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴, this is how we define it 👇
In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available.
It is useful to group the memory into four types:
𝟭. 𝗘𝗽𝗶𝘀𝗼𝗱𝗶𝗰 - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions.
𝟮. 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers.
𝟯. 𝗣𝗿𝗼𝗰𝗲𝗱𝘂𝗿𝗮𝗹 - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries.
𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand.
𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system.
We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory.
And that is it! The rest is all about how you architect the topology of your Agentic Systems.
Any war stories you have while managing Agent’s memory? Let me know in the comments 👇
#AI#LLM#MachineLearning
@rryssf Everyone is saying the context is the new route for AI, but if you feed an AI so much context that everything is explained, its predictive analysis would effectively just be the context you gave it
🚨 RIP “Prompt Engineering.”
The GAIR team just dropped Context Engineering 2.0 — and it completely reframes how we think about human–AI interaction.
Forget prompts. Forget “few-shot.” Context is the real interface.
Here’s the core idea:
“A person is the sum of their contexts.”
Machines aren’t failing because they lack intelligence.
They fail because they lack context-processing ability.
Context Engineering 2.0 maps this evolution:
1.0 Context as Translation
Humans adapt to computers.
2.0 Context as Instruction
LLMs interpret natural language.
3.0 Context as Scenario
Agents understand your goals.
4.0 Context as World
AI proactively builds your environment.
We’re in the middle of the 2.0 → 3.0 shift right now.
The jump from “context-aware” to “context-cooperative” systems changes everything from memory design to multi-agent collaboration.
This isn’t a buzzword. It’s the new foundation for the AI era.
Read the paper: arxiv. org/abs/2510.26493v1
Participating in meta’s $2.5 million “hackathon” having never built a game on their platform.
I bought the quest 3 just for this so lets see how it goes.
I have fine-tuned over 100 different LLMs/VLMs for various use cases over the last 1–2 years, and here is my framework whenever I pick a new project or problem statement:
1. Benchmark/Evals Any problem you are solving for should have an evaluation set that you can easily benchmark on either create it from scratch, generate it synthetically and verify, or curate it from real-world data.
Benchmark existing models and identify the most appropriate metrics. Make it very easy to run evals I generally deploy models on vLLM and run evals there since it’s much faster.
With this, you’ll get to know which metrics you need to optimize for.
2. Dataset Creation 80–90% of my time is spent on creating the dataset. I generally go the synthetic route, building multi-stage AI systems to get reliable data. Synthetic data is cheap and customizable, but it has its drawbacks one being error propagation, and another being less diversity in the dataset.
So, spending as much time as possible on this step is crucial.
3. Ablations & Hypothesis Testing Have an initial set of hypotheses you want to test with the data and run small ablations. These can be to test training strategies, SFT, RL, learning rate, and hyperparameter adjustments.
I mainly work with single GPUs if my models fit and get the end-to-end training script working. Then I try to make it distributed most of the time, I end up using DDP since I work with models under 20B parameters.
I generally start off using a fine-tuning framework that supports the model Unsloth (great for single GPU, can do multi-GPU with DDP), Axolotl (really good dataset packing), or MS Swift (most robust and easy to extend). I usually play around with these, but if none of the frameworks support the model, I write it from scratch or take inspiration from the closest implementation I can find on GitHub.
After each fine-tuning run, I run a benchmark and go through the traces to understand what exactly is happening whether the model is overfitting, whether I need to generate more data, etc. Ablation is the stage where most of my hypotheses get answered.
And I keep iterating until optimal model performance is reached.
One thing I always do is to get a base implementation working end to end then optimise it.
This is a high-level overview of the process I personally follow.
There’s a lot more to this, as each project varies in complexity and scale. Handling datasets in the terabyte range also becomes expensive, and setting up multi-GPU training can sometimes be daunting.
If anyone is interested, I can write a more detailed blog with an example.
Do let me know.
Also if there is anything you guys wud add to this , I am all ears
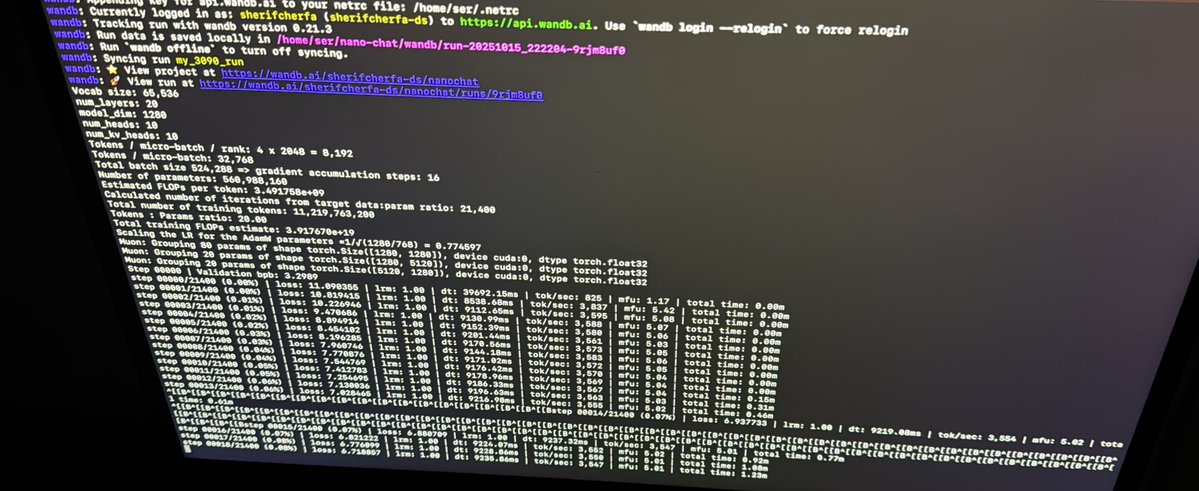
Training Andrej Karpathy’s Nanochat on 4x RTX 3090s at 225W each:
Step 2,694/21,400 (12.59% done)
Loss: 3.14
Runtime: 6.78 hours
Throughput: 3,600 tok/sec
Temps: 52-57°C
VRAM: 19GB/24GB per card
Total cost: 15$ at 55h
Zero errors, perfectly stable
The term “AGI” is currently a vague, moving goalpost.
To ground the discussion, we propose a comprehensive, testable definition of AGI.
Using it, we can quantify progress:
GPT-4 (2023) was 27% of the way to AGI. GPT-5 (2025) is 58%.
Here’s how we define and measure it: 🧵
“AI agents” have become such a buzzword its actually insane.
But no one’s talking about the infrastructure that makes those agents actually work inside a business.
I’ve recently been building AI systems for companies that are way slower than I expected. They’re all trying to integrate AI, but the moment you ask how their data flows, it’s a mess, which makes me so bullish on data-related startups.
It’s weird… I feel like I’ve been selling shovels during a gold rush. Everyone wants AI, but very few have the people who can actually build it properly within their own ecosystem.
Unless you’re a massive consulting firm charging half a million just for a “strategy session,” these companies can’t find anyone reliable to get it done.
There’s such a massive gap between what AI could do for enterprises and what’s actually being done right now.