Sabitlenmiş Tweet

Ivan Kutil
1.2K posts

@ivankutil
👨💻 Cloud | AppsScript | Workspace 👾 @GoogleDevExpert (GDE) 💡 @GoogleCloud Champion Innovator 🚀 co-founder&CTO @AppSatori 🤖 AI & ML 🔬 science 🃏 h4x0r














Having a deep think...

Automate your workflows in #GoogleWorkspace with AI agents 1.Describe task in text 2. Let ✨Gemini 2.0 Flash Thinking generate the code 3. Run it instantly in #GoogleAppsScript #VertexAISprint @workspacedevs @GoogleDevExpert @googledevs @GoogleCloudTech kutil.org/2025/02/agents…

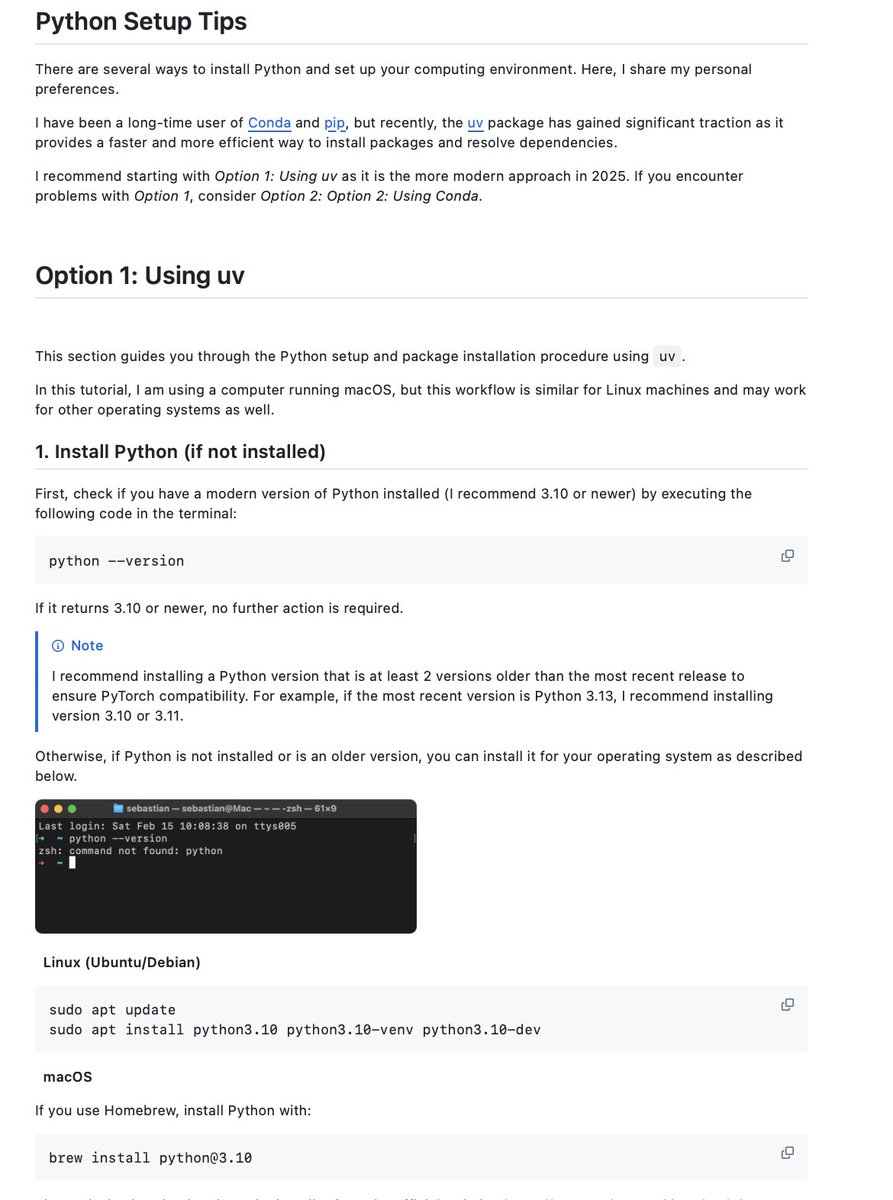



Built-in AI in Chrome (dev channel)
Veo Imagen 3 Google Search Grounding Gemini 2.0 Agents










