Sabitlenmiş Tweet

Jack Rudenko
1.3K posts

@jackrudenko
👨💻 CTO @MadAppGang AI agents are evolving SaaS. Claude Code enthusiast sharing dev tips & trends. MedTech, IoT, high-load | AWS 🤷🏻♂️ | Go/JS/React/Node


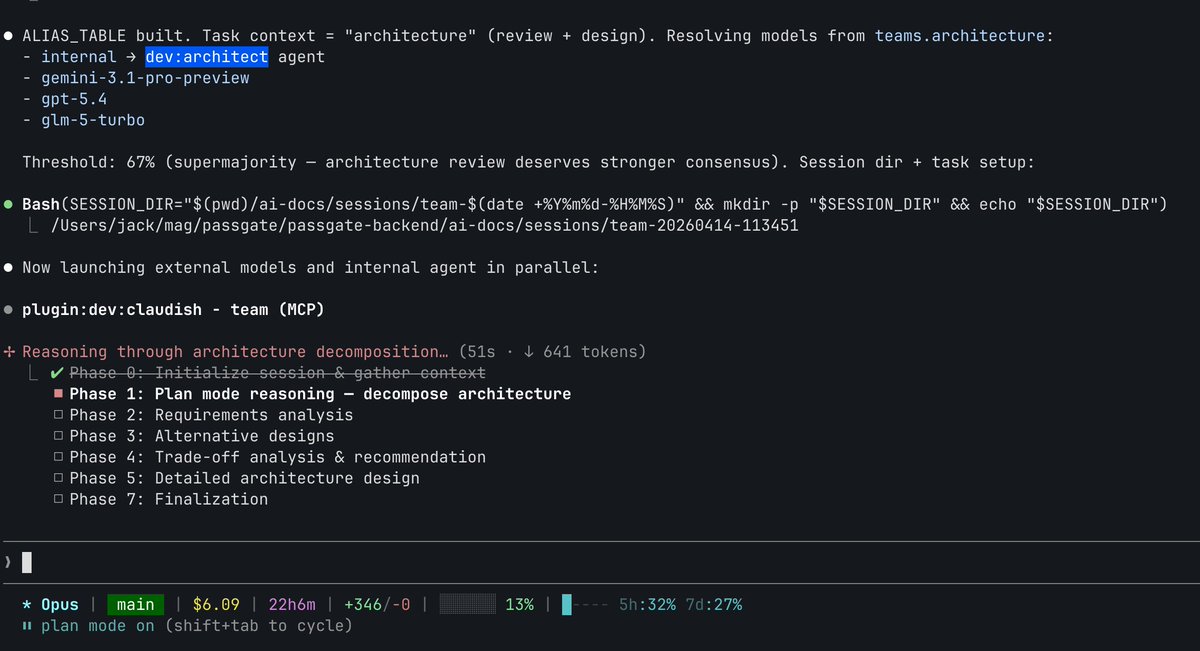
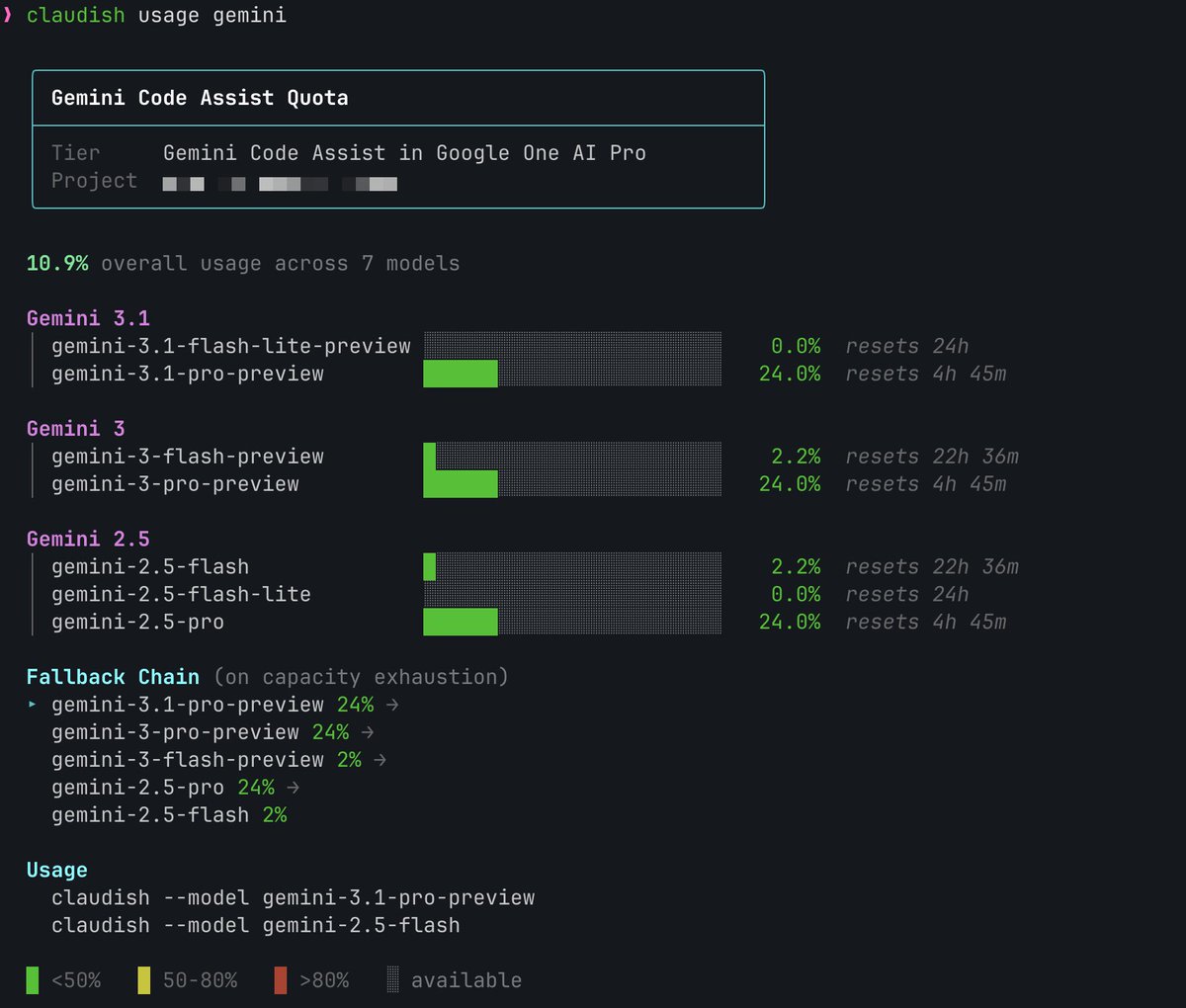

The best usage of tokens so far: Claude Code Satan edition powered by Epic (not Opus) model 4.666 When you feel you are working to make him happy. #claudecode Satan Edition. Bloody good.
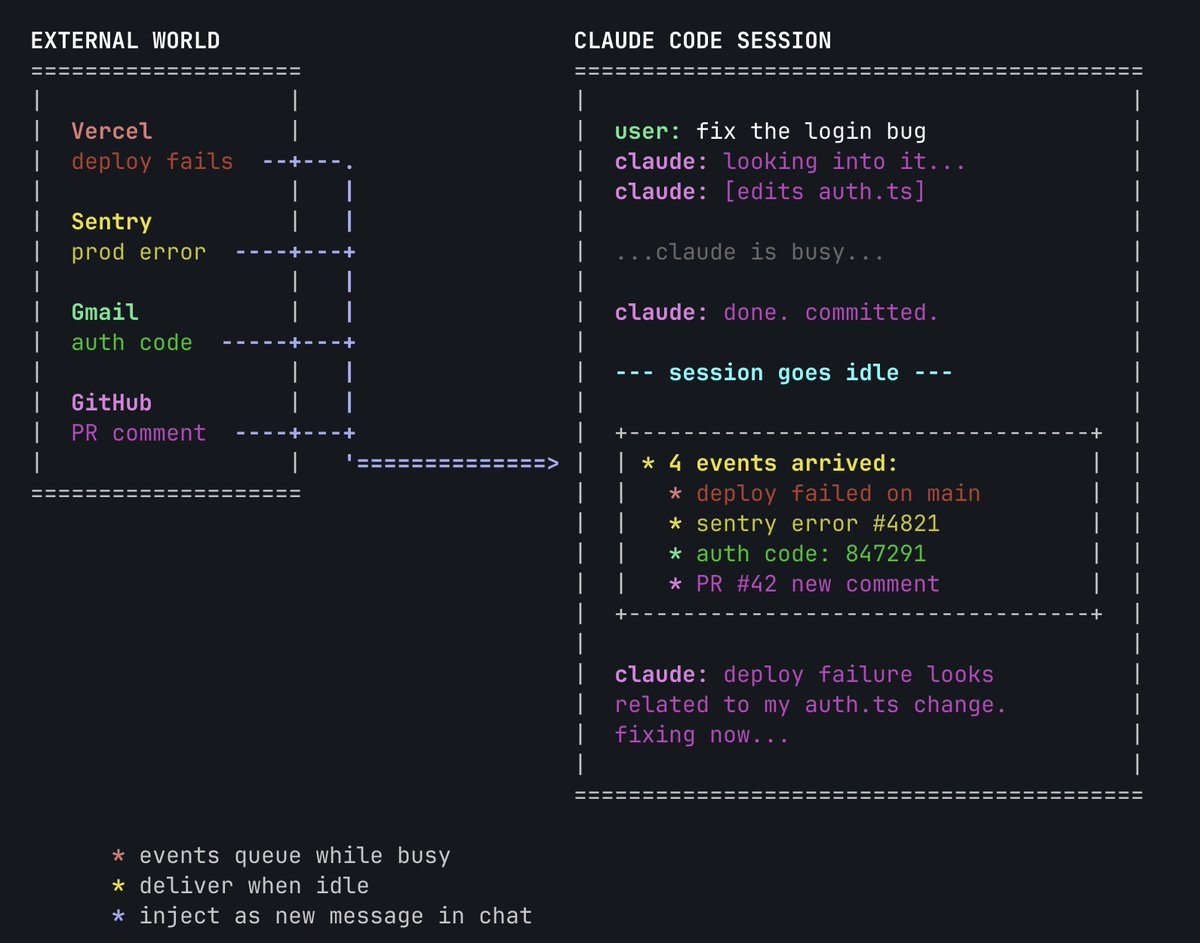


You can now enable Claude to use your computer to complete tasks. It opens your apps, navigates your browser, fills in spreadsheets—anything you'd do sitting at your desk. Research preview in Claude Cowork and Claude Code, macOS only.