Sabitlenmiş Tweet

Training with more data = better LLMs, right? 🚨
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵+arXiv 👇
1/9

English
Jacob Springer
126 posts

1/ To retain post-training capabilities after further fine-tuning, mix that data into pretraining. The effect can be invisible until fine-tuning begins; early exposure may not help post-training performance, but it changes what persists. How a model learns a task matters.


Spending billions to train the "best" base model? You might be optimizing the wrong thing! 🎯 We show that controlling sharpness during mid-training leads to over 35% less forgetting after fine-tuning / quantization... even when the base model itself gets worse. 🧵 Takeaways for pretraining: - Use SAM (Sharpness-Aware-Minimization) in the final steps (~10%) - Try much higher learning rates (yes, even ~10× larger) 1/9
Spending billions to train the "best" base model? You might be optimizing the wrong thing! 🎯 We show that controlling sharpness during mid-training leads to over 35% less forgetting after fine-tuning / quantization... even when the base model itself gets worse. 🧵 Takeaways for pretraining: - Use SAM (Sharpness-Aware-Minimization) in the final steps (~10%) - Try much higher learning rates (yes, even ~10× larger) 1/9

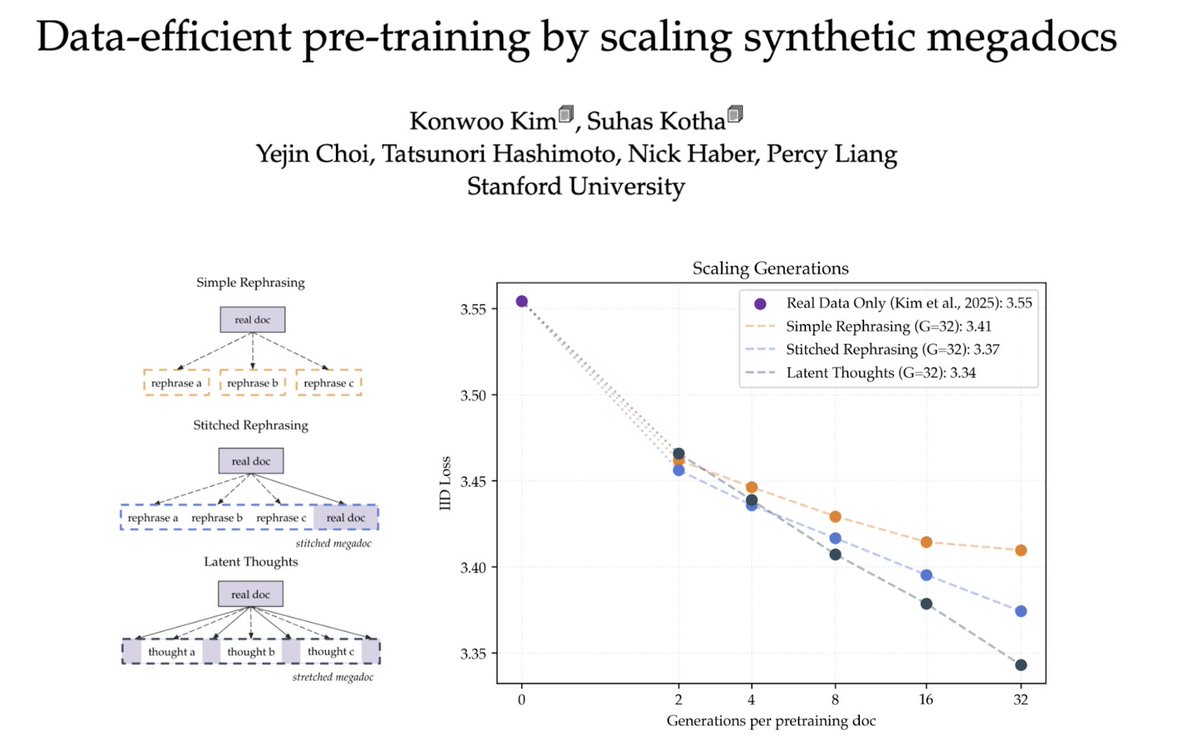




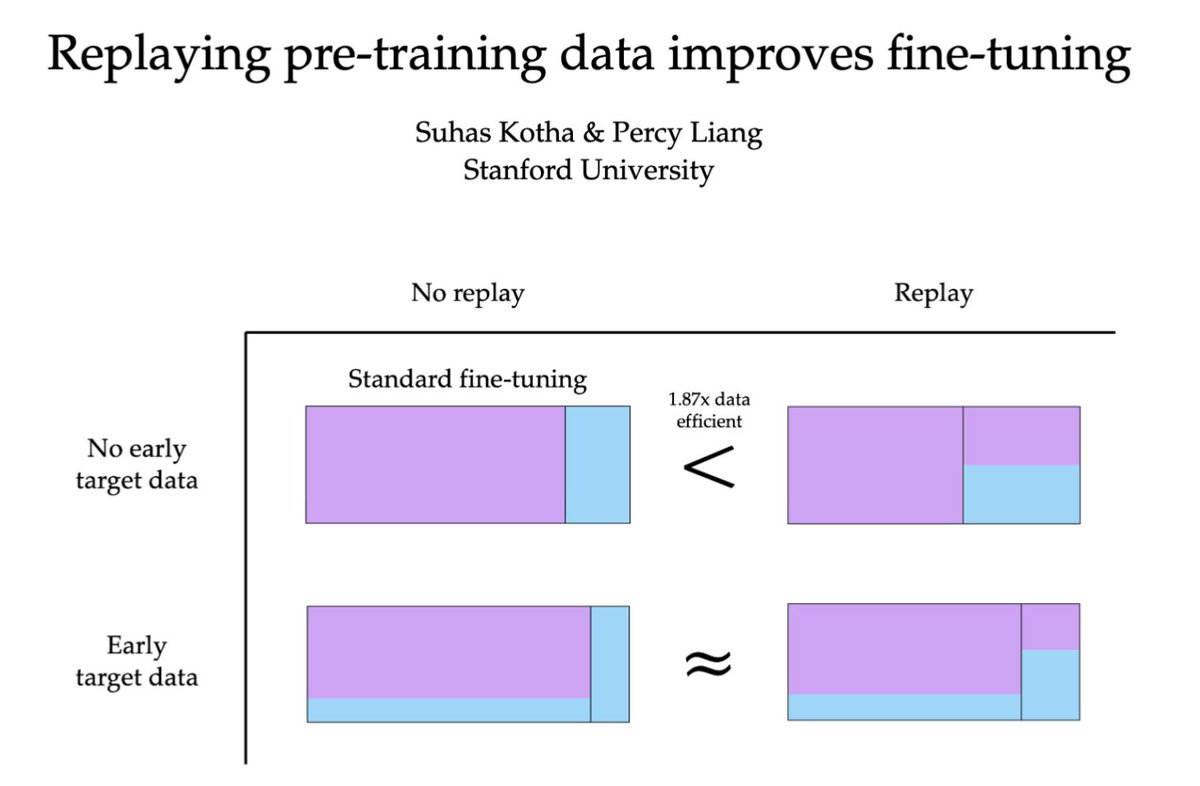
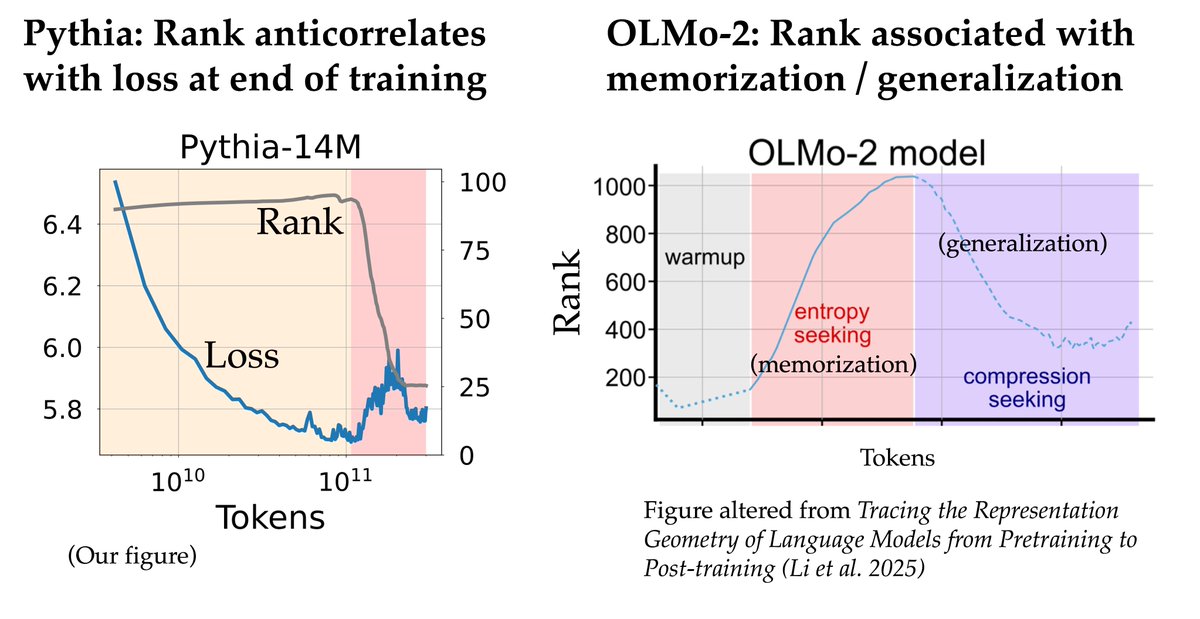
Is the geometry of language model weights really predictive of performance?🔍 Our new work challenges the popular hypothesis that low rank unembedding matrix hurts LLM performance; and the answer is more complicated than you'd think! arxiv.org/abs/2602.20433 (1/8)




