Sabitlenmiş Tweet

🚀 Exciting news for all AI enthusiasts & developers!
We're thrilled to announce that "Prompt Engineering for Generative AI" is NOW available for pre-order ! 📚
amzn.to/3wFGbas
#OpenAI #PromptEngineering #GenerativeAI

English
James Phoenix
4.7K posts

@jamesaphoenix12
🏗️ Building https://t.co/MBYBDonekk | LLM Engineer 🎮 Ex-Wow Professional (top 0.5%)

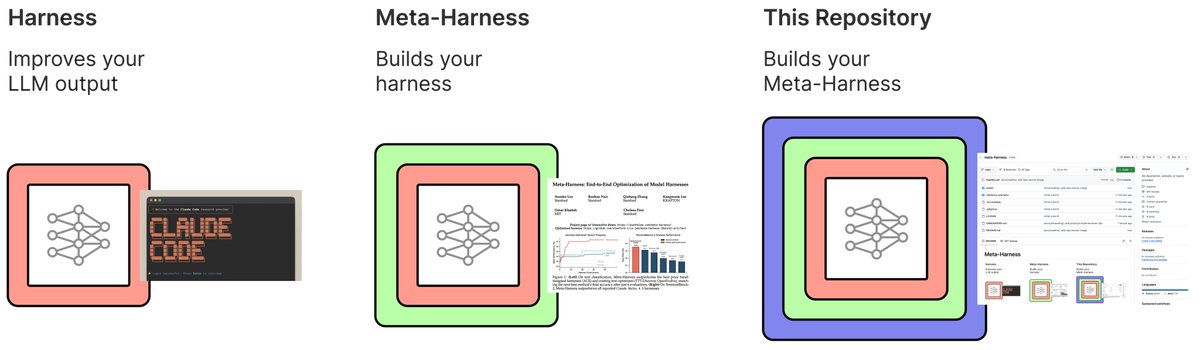
How can we autonomously improve LLM harnesses on problems humans are actively working on? Doing so requires solving a hard, long-horizon credit-assignment problem over all prior code, traces, and scores. Announcing Meta-Harness: a method for optimizing harnesses end-to-end

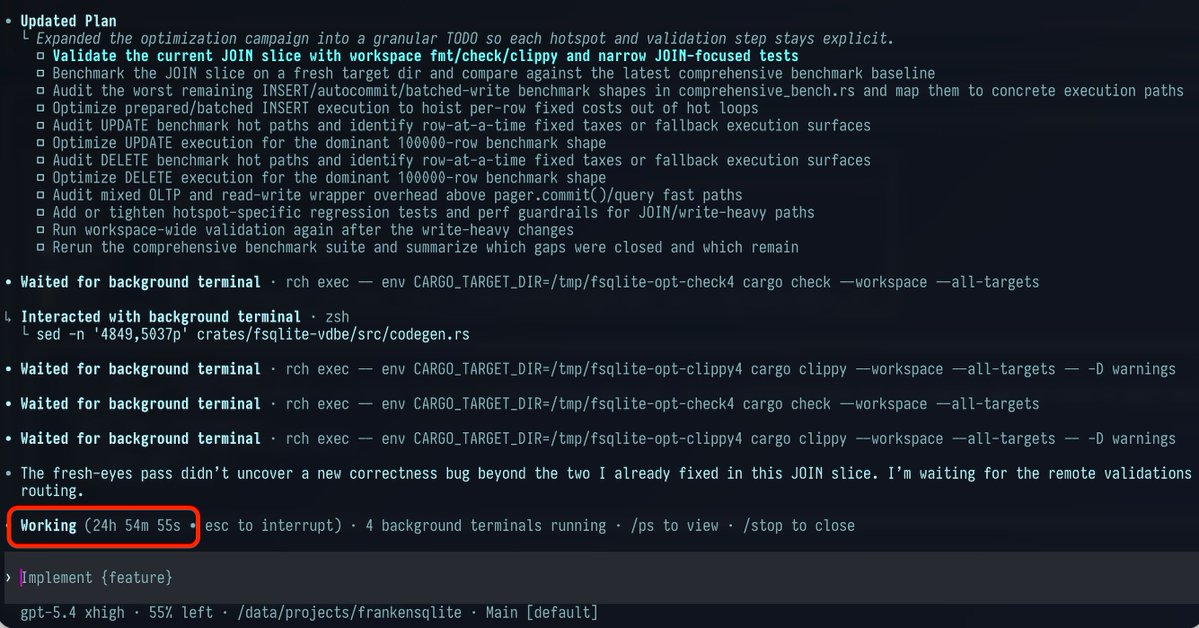
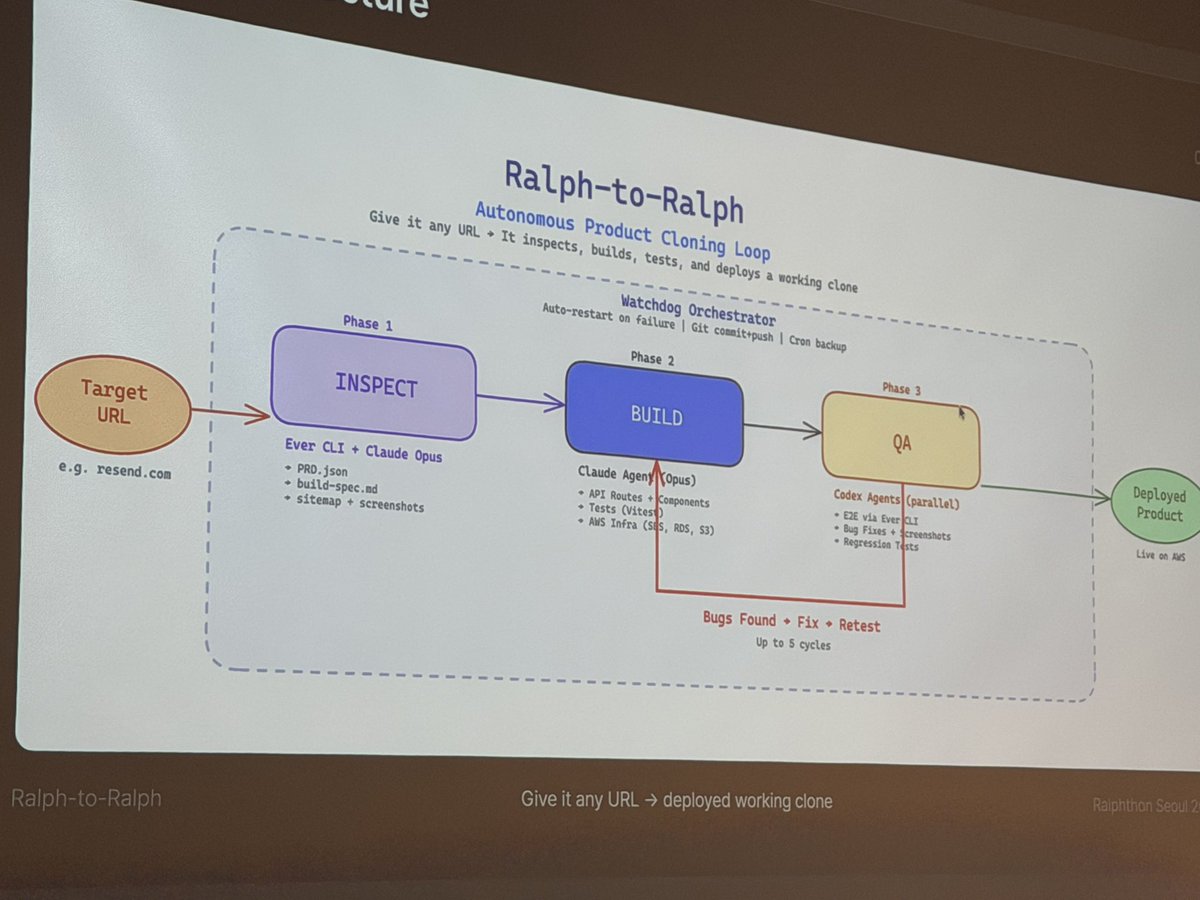
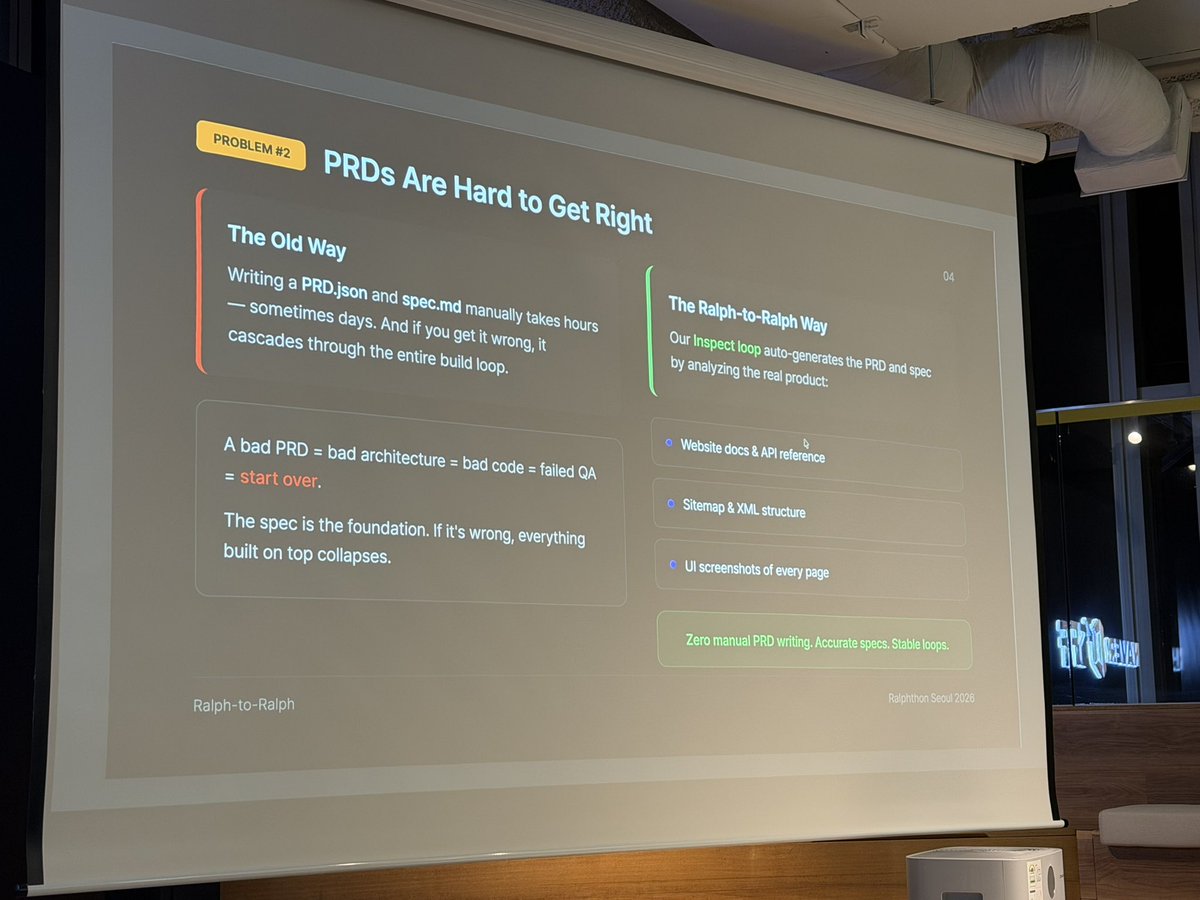
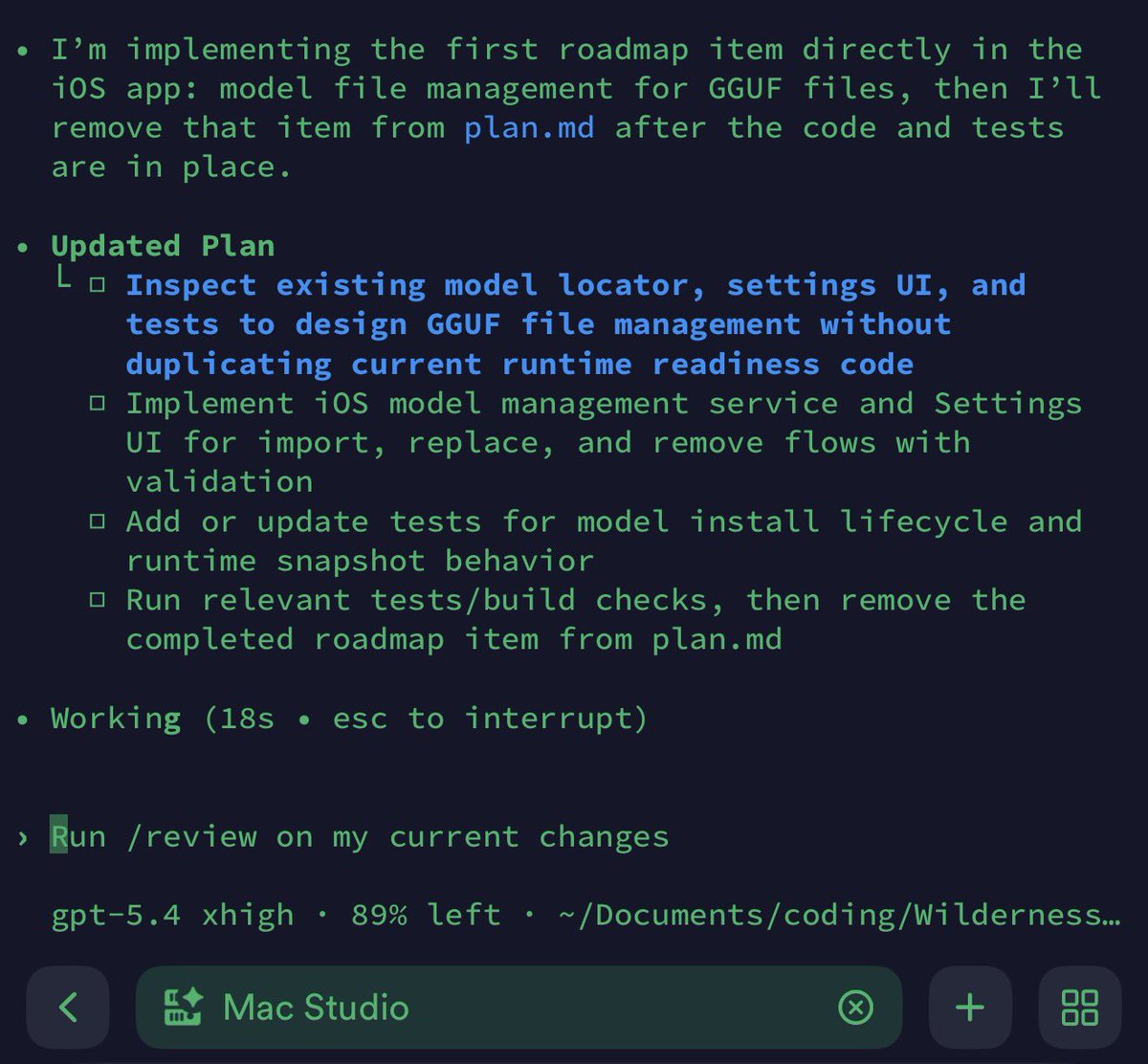
SOMEONE MADE A DIGITAL WHIP TO MAKE CLAUDE WORK FASTER 💀








Anthropic CEO: “In the next 3 to 6 months, AI will write 90% of the code, and within 12 months, nearly all code may be generated by AI.” the job isn’t coding anymore, it’s telling machines what to build.
Pi prompt templates can now loop and rotate between different models on each iteration. In this example it runs each loop with a different model as a subagent based on a fork of the current chat. pi install npm:pi-prompt-template-model github.com/nicobailon/pi-…