Sabitlenmiş Tweet

What if your video generator could refine itself—at inference time?
❌No new models. ❌No retraining. ❌No external verifier.
💡 Introducing Self-Refining Video Sampling
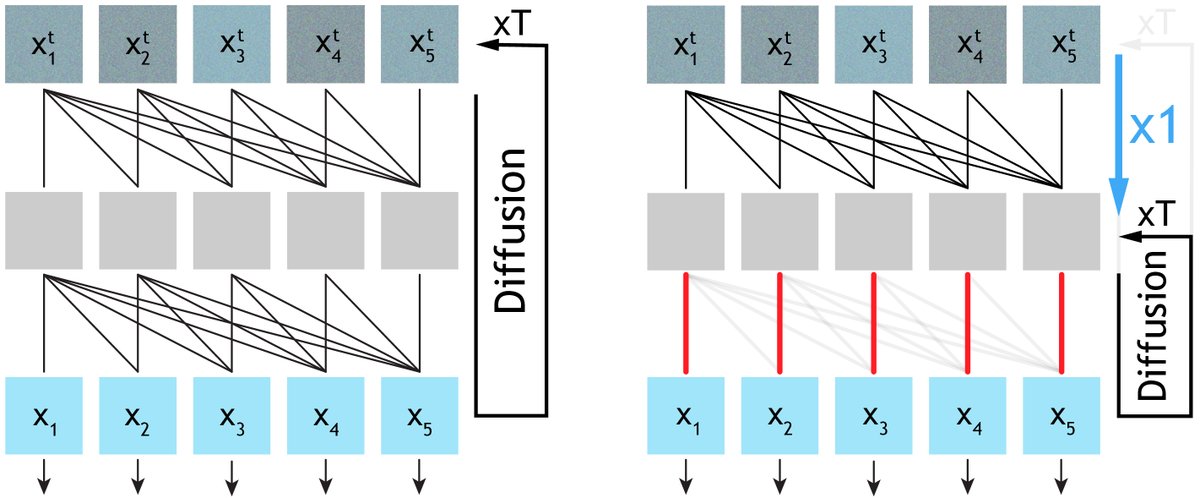
By reinterpreting a pretrained generator (Wan2.2, Cosmos) as a denoising autoencoder, we enable iterative self-refinement at inference time ➡️dramatically improving physical realism and achieving over 70% human preference!
🧵
English