JC Peralta retweetledi

A new geospatial foundation model can now estimate how poor your neighbourhood is, track how fast that's changing, and do it without anyone filling out a single survey form.
A team of Stanford researchers just published Tempov, a foundation model trained on three million pairs of Landsat images spanning two decades. It takes raw satellite imagery and predicts asset wealth at the village level, across entire continents, updated in near real-time.
The benchmark numbers are worth sitting with. In Malawi and Mozambique, the model explains 87% and 74% of the variation in household wealth from satellite imagery alone. That's from six spectral bands. No census forms. No field enumerators. No mobile phone metadata.
The harder problem is tracking change, not just level. Most existing models are trained to predict a static snapshot. When you ask them to predict how wealth shifted between 2008 and 2018 in the same locations, performance collapses to near-random. Tempov holds at R² = 0.69 for Malawi and 0.46 for Mozambique on that same change-tracking task.
What makes the difference is how the model was pretrained. The researchers constructed bitemporal image pairs that maximise seasonal variance, then forced the model to learn representations that are stable across seasons but sensitive to genuine long-run economic shifts. The learned embeddings spontaneously delineate road networks, urban structure, and agricultural patterns from natural background, without ever being told to.
The scarcity problem is where it gets interesting for development economics. The standard tools for measuring poverty rely on the Demographic and Health Surveys. DHS data is spatially sparse and resurveyed infrequently. The correlation between asset wealth in Malawi's earlier and later censuses is only 0.42. In Mozambique it's actually negative: -0.71.
Tempov gets around this with a two-stage adaptation. Train on historical census data, then fine-tune to the target year using only 5% of contemporary survey points. With that 5% adjustment, it outperforms geospatial foundation models that were given 100% of available survey data. Combining a strong historical prior with minimal contemporary calibration can substitute for the full survey investment.
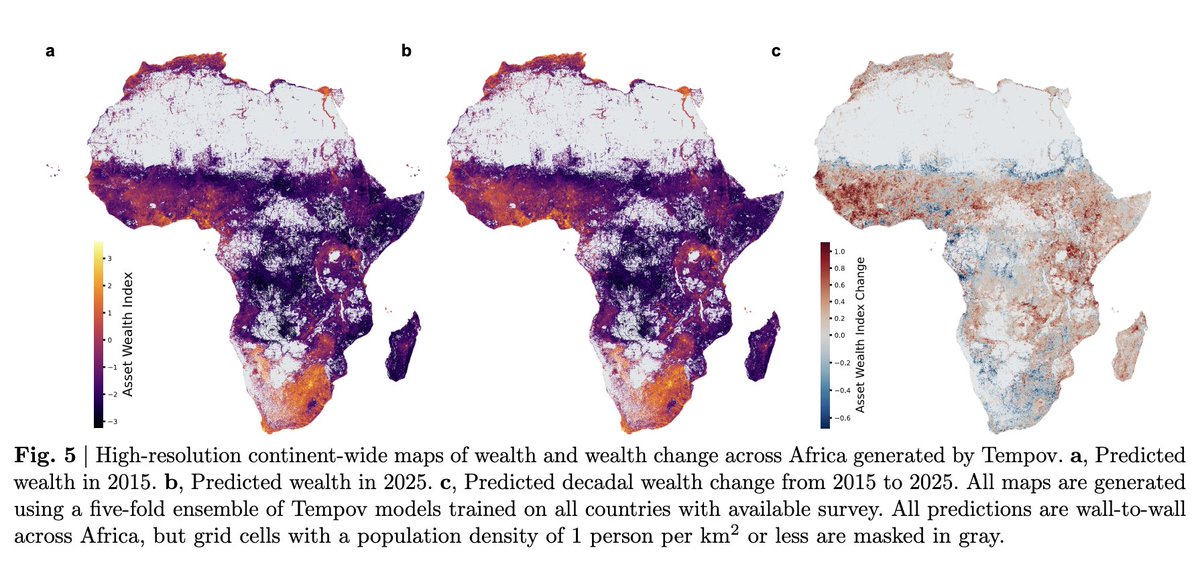
The researchers then deployed it continent-wide. Five models trained under cross-validation on all 34 African countries with recent DHS surveys, averaged into a single ensemble, producing 6 km × 6 km wealth maps for the entire African continent in 2015 and 2025. Roughly 80% of measured wealth inequality across the continent is within countries, not between them.
The decadal change map shows wealth gains concentrated in West and East Africa and substantial declines across parts of Southern and Central Africa. Country-level factors explain only about a third of the variation in wealth change. Local temperature trends and nearby conflict events predict the changes better than institutional-quality proxies do.
For the applied economics side: the model achieves competitive performance with 10% of available survey samples where baseline foundation models need 100%. That's not a modest efficiency gain. That's a different cost structure for poverty measurement entirely.
DHS survey rounds are already under funding pressure. The World Bank's Living Standards Measurement Surveys have become increasingly irregular. The status quo is a slow degradation in the quality and frequency of ground-truth data on living standards in the places that most need monitoring.
What Tempov suggests is that the role of household surveys may be shifting from the primary measurement instrument to the calibration anchor. You don't stop running surveys. You run fewer, target them better, and use them to tune a model that fills in the rest from orbit.
The code and weights are open-source. The continent-wide wealth maps are public. The methodology is reproducible by a national statistics office with a laptop and a moderate AWS bill.
The hard part was always getting data out of places that couldn't afford to collect it. That constraint just got significantly looser.
Link to paper: arxiv.org/pdf/2604.23166
English