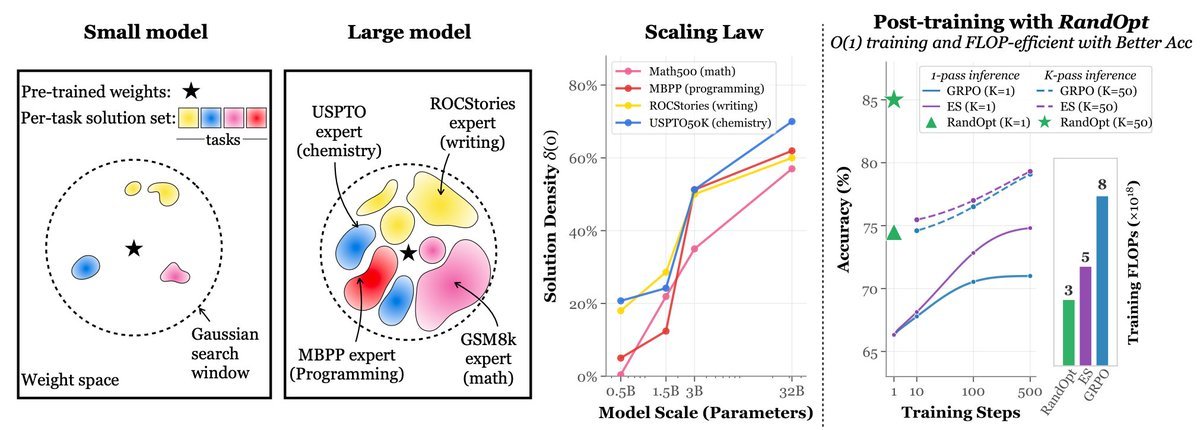
For 400 years, one thing separated great scientists from average ones. Not intelligence. Not work ethic.
Taste.
The ability to look at 1,000 research directions and know which one is worth your life's work.
Fudan University just bottled that into a model.
They scraped 2.1 million arXiv papers and did something nobody had tried before. Instead of training AI to run experiments or search literature, they trained it to judge ideas. 700,000 matched paper pairs. Same field. Same year. Different citation counts.
One job: figure out which research the scientific community actually cared about.
They called it Scientific Judge. And the numbers destroyed every benchmark.
It beats GPT-5.2, Gemini 3 Pro, and GLM-5 at predicting scientific impact. It generalizes to papers published after its training data ends. It works on fields it was never trained on. It even transfers to ICLR peer review scores without ever seeing them.
But here's the part that broke my brain.
They used Scientific Judge as a reward model to train a second AI called Scientific Thinker. You give it a paper, it reads it, then proposes the next high-impact research direction. Not a summary. Not a literature review. An original idea. Win rate against baseline? 81.5%. Win rate against GPT-5.2 itself? 54.2%.
The AI is now proposing research ideas that frontier models judge as better than their own.
Scientific taste was always the last human advantage in research. The PhD took 5-7 years because that's how long it took to develop judgment — to know what matters before anyone else does. That just became a training objective. Not from human feedback. Not from expensive annotations. From citations. The raw signal of what the scientific community collectively decided was worth building on.
We're not talking about AI that executes science. We're talking about AI that decides what science is worth doing. That's a completely different thing.

English