@grokmen321@AdamSchefter Can’t win games? 🤔 spent last decade with nothing but losing seasons? 🤔🤔
Are you just making shit up to try and justify your fake rage?
Houston Texans dropping $1B+ on a shiny 83-acre Toro District HQ & entertainment zone opening in 2029.
Bold move for a team that’s spent the last decade building nothing but losing seasons and fan frustration.
Can’t win games, so they’re building a theme park instead. Peak cope.
The Houston Texans announced they are building a sports and entertainment destination that will include their headquarters and training complex. It's going to be an 83-acre project in Bridgeland, which is Northwest Houston, and called “Toro District”. It is scheduled to open in 2029.
It worked for the first leg, so I’m wearing another yellow Arsenal shirt for the game (in honour of the 2006 away win).
Going with the banana kit this time! 🍌
Coffee: Made
Schedule: Cleared
Food: Ordered
Sweats: On
Let’s have a damn day.
- Burnley v. Watford
- SMU v. Penn State
- Texans v. Chiefs
- Clemson v. Texas
- Steelers v. Ravens
- Tennessee v. Ohio State
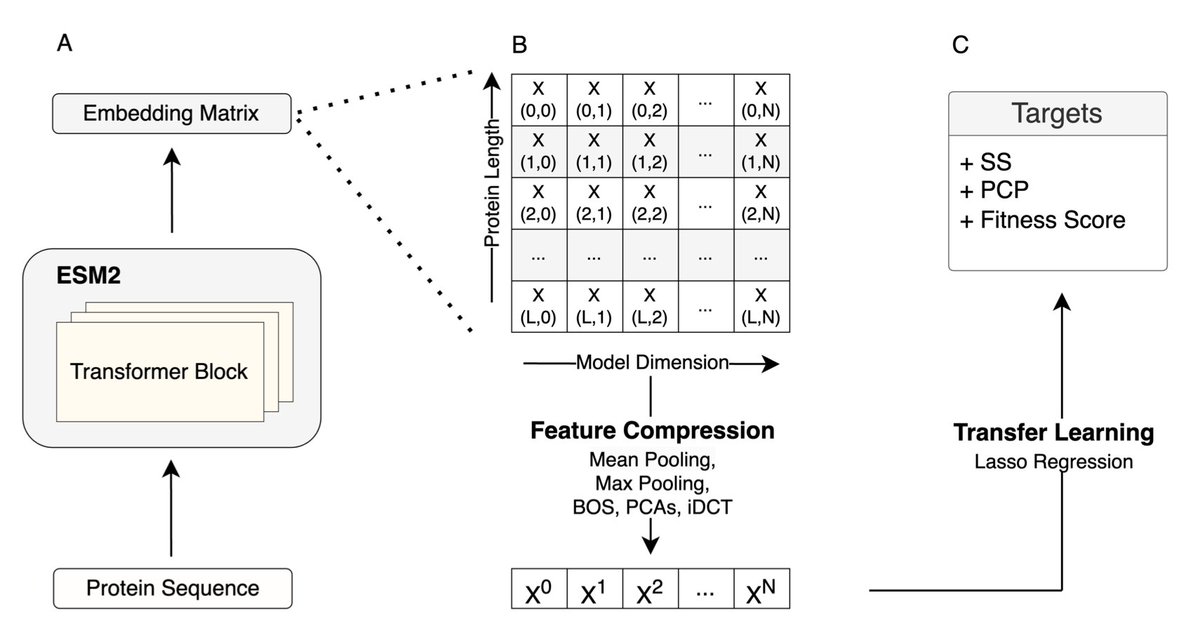
Scaling Down for Efficiency: Medium-Sized Transformer Models for Protein Sequence Transfer Learning
• A surprising finding: medium-sized protein language models like ESM2 650M perform nearly as well as the largest ones (ESM2 15B), even when handling complex biological datasets.
• The study demonstrates that larger models are not always better for transfer learning, especially when data is limited, making smaller models both efficient and effective.
• Mean embeddings outperformed other compression methods across diverse datasets, offering a practical solution for dimensionality reduction without losing critical features.
• Smaller models like ESM2 650M significantly reduce computational costs while maintaining high accuracy, democratizing access to advanced protein analysis tools.
• Interestingly, the study shows diminishing returns for extremely large models in limited data scenarios, challenging the trend of scaling up indiscriminately.
• The analysis spanned over 40 deep mutational scanning datasets and diverse protein sequences, underscoring the generalizability of these findings.
• ESM2 650M proved to strike the best balance between performance and efficiency, especially in datasets below 10,000 samples.
• This work paves the way for more accessible, cost-effective protein sequence analysis, promoting wider adoption of ML techniques in structural biology.
@ClausWilke
💻Code: github.com/ziul-bio/SWAT
📜Paper: biorxiv.org/content/10.110…#ProteinLanguageModels#TransferLearning#Bioinformatics#MachineLearning#ESM2