Technically, LWD combines distributional implicit value learning from heterogeneous fleet data and adjoint matching for policy extraction in flow-based VLAs. Across 8 real-world tasks, one generalist policy reaches 95% average success.
Excited to share LWD: Learning While Deploying. Our robots learn while doing real tasks—restocking groceries, brewing Gongfu tea, making cocktails, making juice, and packing shoes. Deployment is no longer just evaluation; it becomes the training loop.
🧵
The takeaway: scaling robots becomes a way to scale learning.
SOP suggests a shift in how we build robot foundation models:
not “pretrain → fine-tune → freeze,”
but deploy → learn → redeploy—continuously.
Project and paper: agibot.com/research/sop
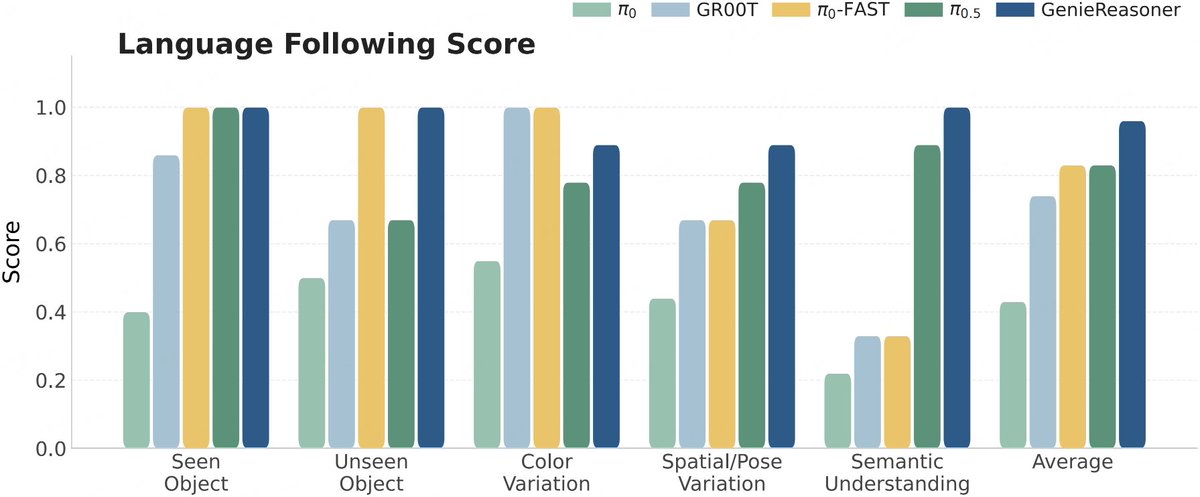
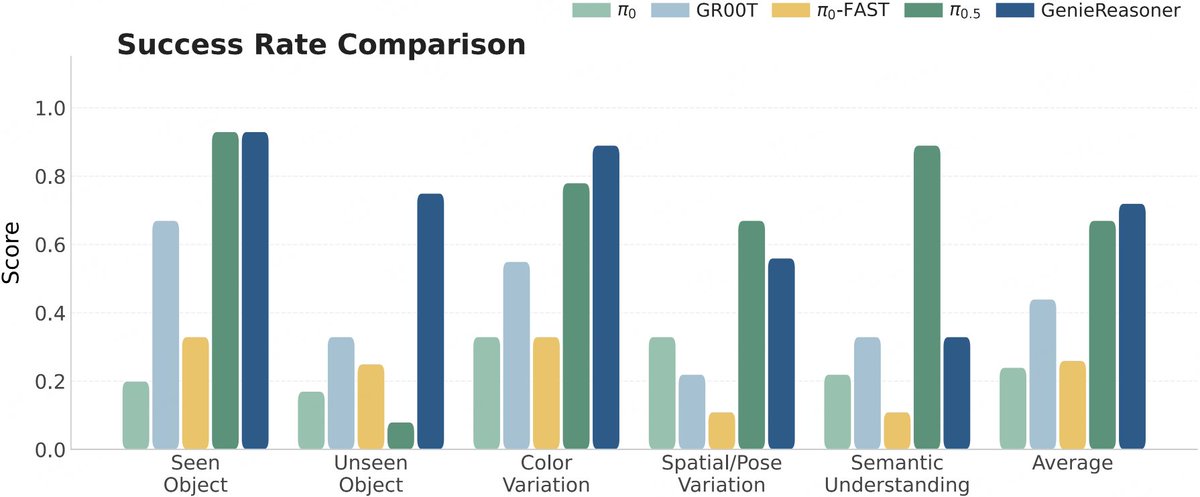
Generalist robots don’t fail due to a lack of generality.
They fail due to a lack of proficiency where it matters.
We introduce SOP, enabling generalist policies to improve from real-world experience across distributed robot fleets, without sacrificing generality.
🧵 agibot.com/research/sop
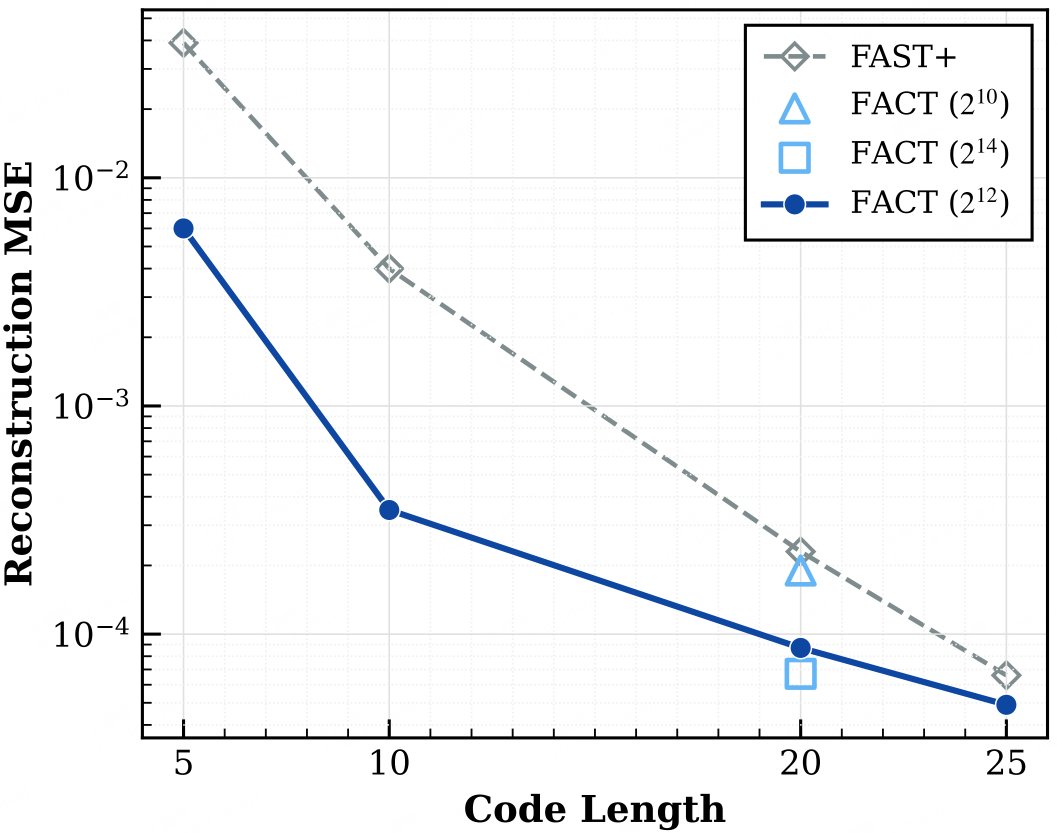
One core bottleneck in VLA models is action representation.
Discrete tokens scale beautifully with VLM pretraining—but lose precision.
Continuous actions are precise—but often break VLM reasoning.
In our new work, we resolve this tension at the representation level. 🧵
On real robots, Act2Goal shows strong zero-shot generalization.
With reward-free online adaptation (hindsight goal relabeling + lightweight LoRA finetuning), success rates on challenging OOD tasks improve from ~30% → ~90% within minutes of autonomous interaction.
Long-horizon visual goals remain surprisingly hard for robot manipulation.
We introduce Act2Goal, a goal-conditioned policy that uses a visual world model to reason about progress toward a goal, and practice it autonomously in the real world.