Jin Budelmann retweetledi

@jinthagerman Yeah we’ve been working on improving reliability. It should be feeling better lately, expect it to improve more
English
Jin Budelmann
14.7K posts

@jinthagerman
Building stuff https://t.co/jLMEyb6Bh5
Two updates to auto mode: · Now available on the Pro plan · Sonnet 4.6 is now supported, alongside Opus 4.7 Shift+tab, and let Claude run.



Apple accidentally left Claude.md files in today's Apple Support app update (v5.13)
i mean what an insane story. meta’s $2B acquisition is now dead: -> March 2025: Manus launches AI agent -> 2M waitlist in 7 days, invite codes reselling for $1400 each (i tried to buy one lol) -> relocates from Beijing to Singapore to escape chinese authorities -> hits $90M revenue run-rate -> December 2025: Meta buys it for $2B 4x markup in 8 months. -> March 2026: china stops Manus co-founders from leaving the country -> today: china blocks Meta from acquiring them china clearly see’s AI as a geopolitical weapon and is not willing to yield anything to the USA this probably why they’re refusing to use nvidia chips instead pushing huawei etc truly nuts



🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length. 🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models. 🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice. Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today! 📄 Tech Report: huggingface.co/deepseek-ai/De… 🤗 Open Weights: huggingface.co/collections/de… 1/n

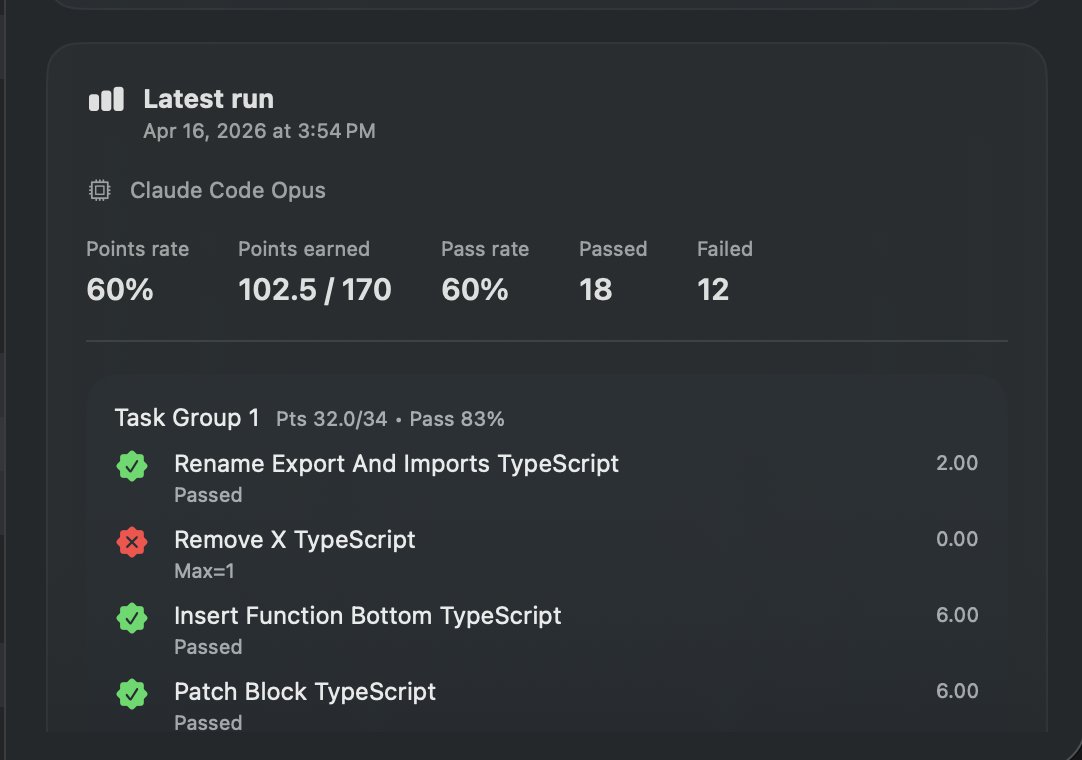






Claude Mythos is Delusional





