Sabitlenmiş Tweet

🧑⚖️Rubrics proven to be powerful in legal NLP, too!
Introducing LEGIT (LEGal Issue Trees): a novel legal reasoning dataset with rubrics for evaluating the reasoning traces.
arxiv.org/pdf/2512.01020 (1/7)

English
Jinu Lee
83 posts
@jinulee_v
PhD Student @UIUC_NLP. Interested in *semantics of reasoning*, from neuro-symbolic methods to reasoning evaluation/improvement in LLMs. Ex-Intern @MSFTResearch






📢 The First Call for Papers for EMNLP 2026 is officially out! 📝 We welcome long & short papers featuring original research on empirical methods for NLP. 🗓️ ARR Submission Deadline: May 25, 2026 🔗 Read the full CFP here: 2026.emnlp.org/calls/main_con… #EMNLP2026


I'm thinking of two words. Can you guess them? The first word is six letters long, and often in a cookie. The second is a synonym for lifting, and is spelled identically to the first word, except with a 'g' added to the end, like so: 1. _ _ _ _ _ _ 2. _ _ _ _ _ _ g




📢New paper alert! Scaling compute for reasoning evaluation is powerful; if you have compute for Best-of-N decoding, scaling evaluation compute is better than generating more CoTs! More in thread! (1/6) arxiv.org/abs/2503.19877
🧑⚖️Rubrics proven to be powerful in legal NLP, too! Introducing LEGIT (LEGal Issue Trees): a novel legal reasoning dataset with rubrics for evaluating the reasoning traces. arxiv.org/pdf/2512.01020 (1/7)

Join us in Urbana-Champaign 🌽 this year for the Midwest Speech and Language Days (MSLD 2026). Abstracts are due on March 2nd, everyone is welcome to attend!

How do they produce such crazy papers?

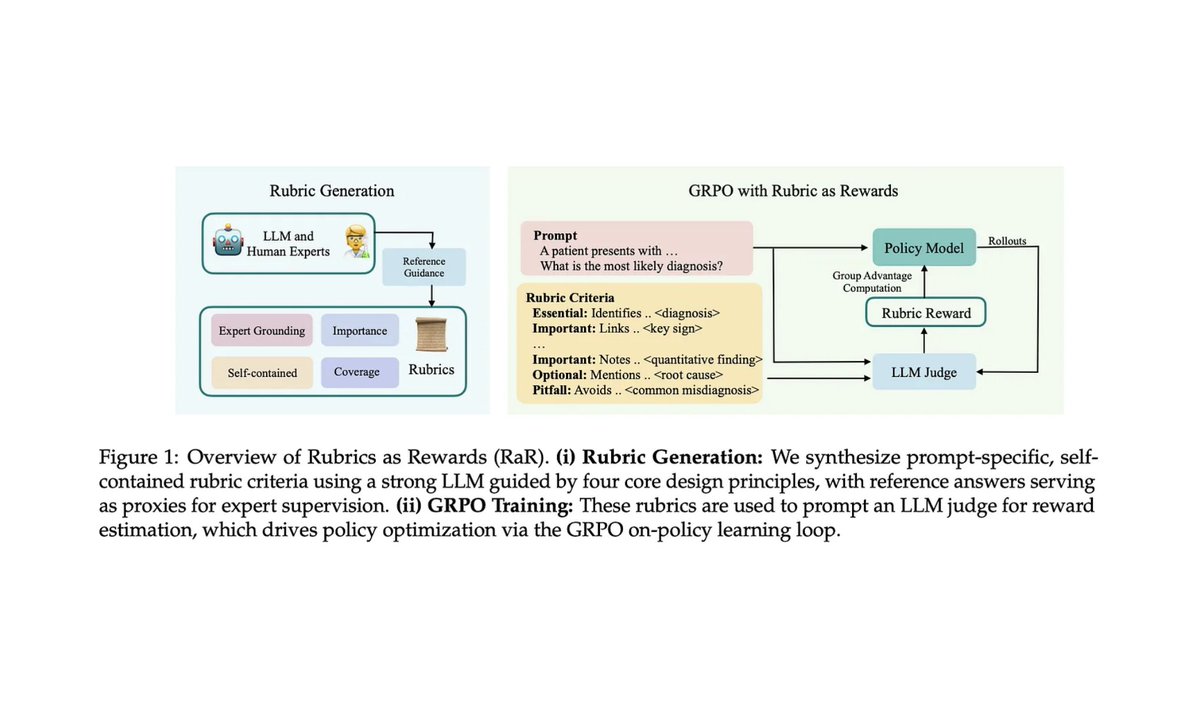
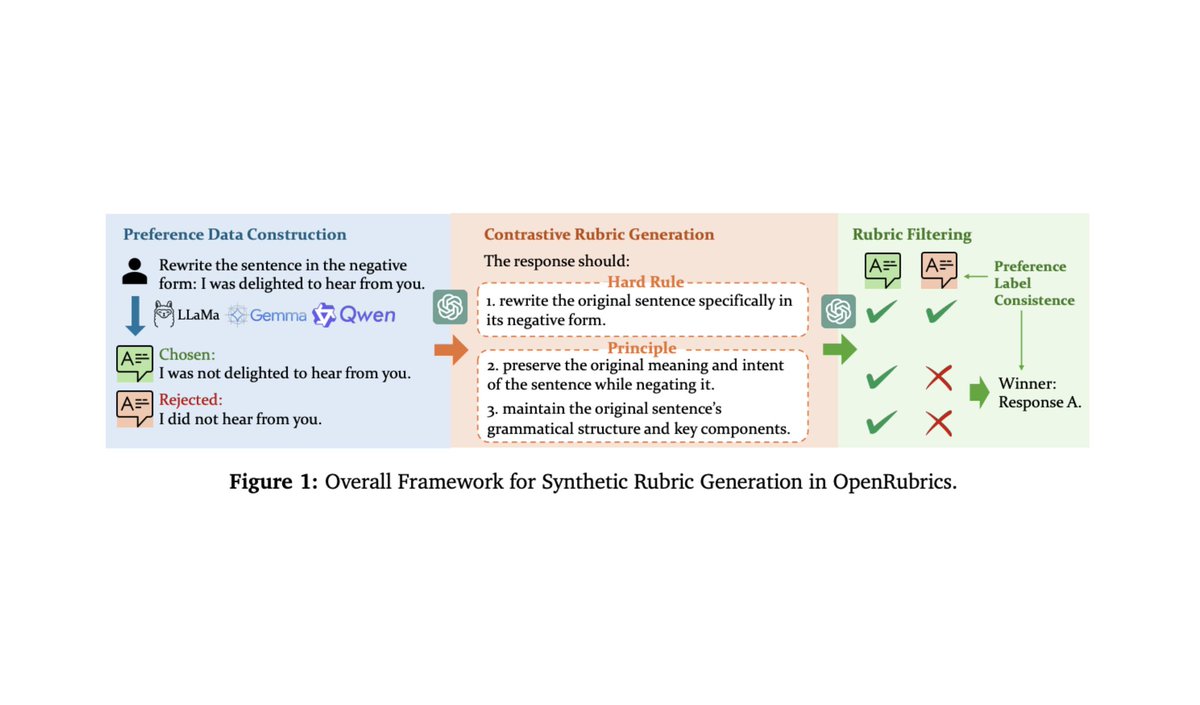
Some more really good papers on rubric rewards that I've been reading: - arxiv.org/abs/2602.01511 - arxiv.org/abs/2411.01111 - arxiv.org/abs/2410.21545 - arxiv.org/abs/2511.01758 - arxiv.org/abs/2512.01020 TL;DR: Rubric rewards are really cool. There is a lot of great recent progress that surpassed my expectations. There's also a lot more to be done, and making progress on truly subjective tasks seems to be noticeably more difficult. My favorite paper so far is the first in this list, which proposes an alternating RL framework for jointly training a rubric generator and rubric-based reward model. There still is a lot to figure out w.r.t. making rubrics work well, but this paper shows a really clear benefit from rubric-based RL and has an interesting setup to make joint training (of the rubric generator and generative reward model) more stable. There are still many areas for improvement for rubrics. For example, it seems rubrics still work best for constraints that are more objective, whereas very open-ended tasks (e.g., properly-styled creative writing) are still going to be quite tough. The benefit of rubrics is not uniform across domains, and it's not immediately clear for which domains rubrics will work best; e.g., instruction following tends to benefit a lot from rubrics, the benefit is less clear for things like science / medicine. Interestingly, a lot of papers tackling very open-ended tasks with rubrics are also formulating evaluation as a pairwise problem. Given two completions, they ask the rubric generator to produce a rubric that will properly distinguish / rank the chosen and rejected completion in the pair. This probably makes very subjective evaluations easier, but the application to online RL is also less straightforward. We can't just compute the reward for a completion, we have to somehow create a pairwise comprison to compute the reward.


Join us in Urbana-Champaign 🌽 this year for the Midwest Speech and Language Days (MSLD 2026). Abstracts are due on March 2nd, everyone is welcome to attend!

