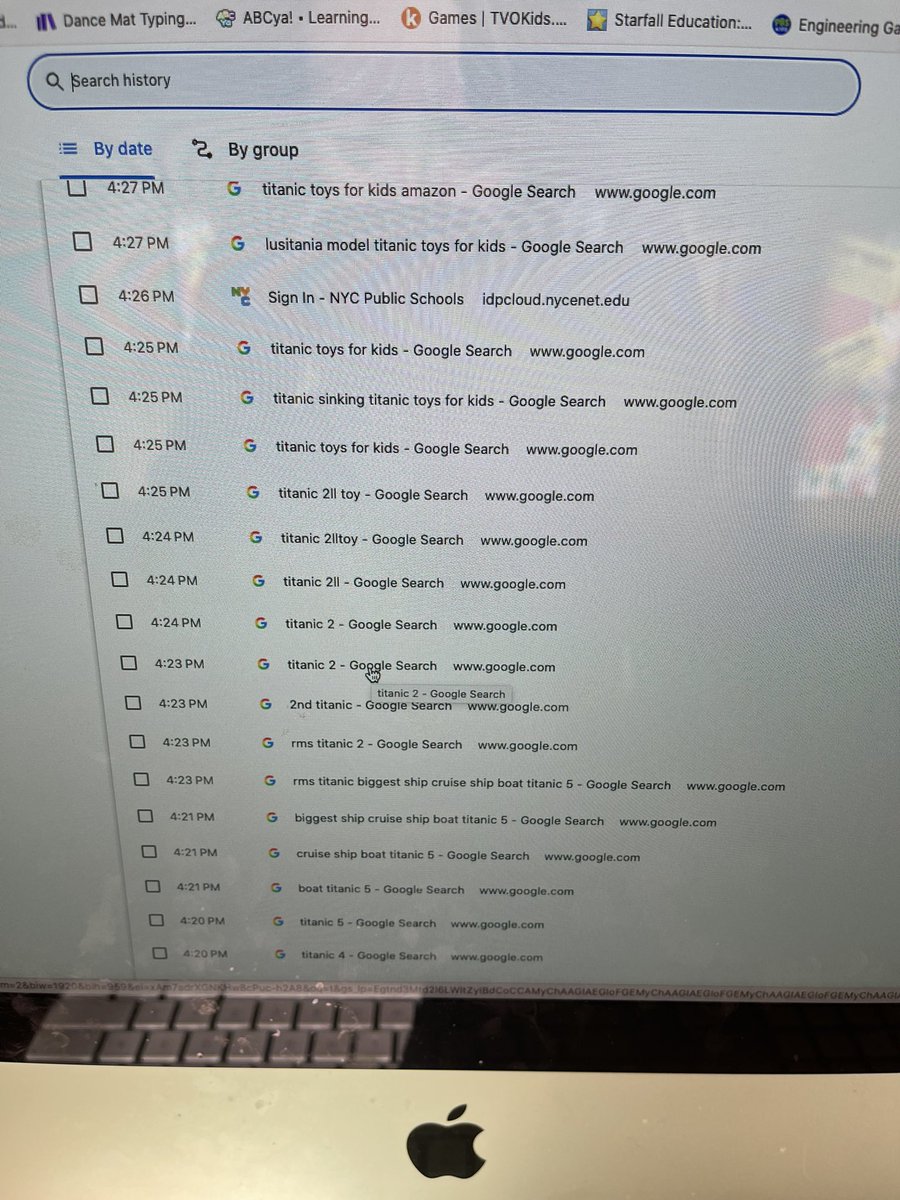
and look at these nice errors , that i wont bother handling, i get
English
julio (bigsxy)
5.4K posts

@juemrami
🇲🇽🤝🇺🇸 LA Software "Engineer" (Unemployed af) Into ML, Web, WoW Addons, Nix, and Embedded LFG Bulletin Board - 250K+ users | $0 MRR https://t.co/Si89fkutRl
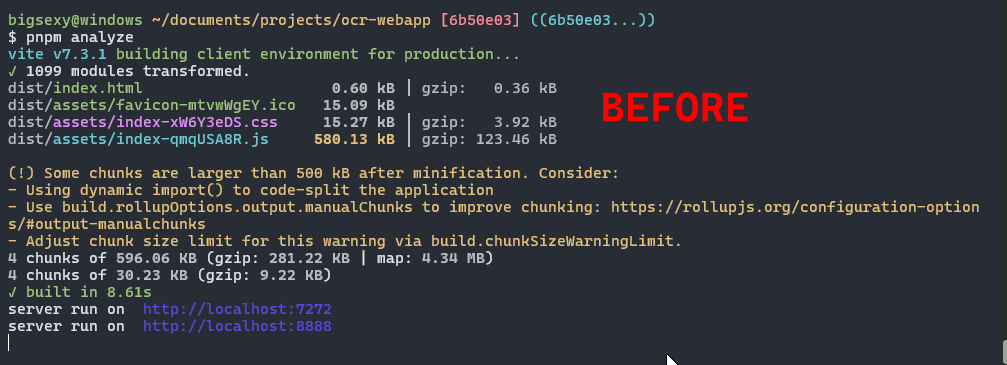
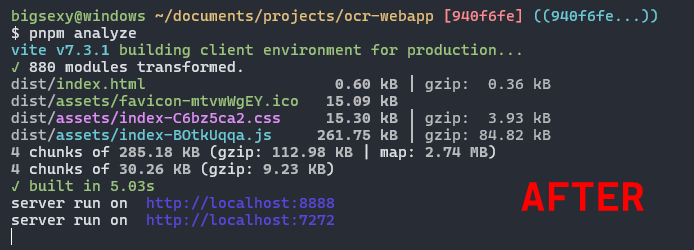
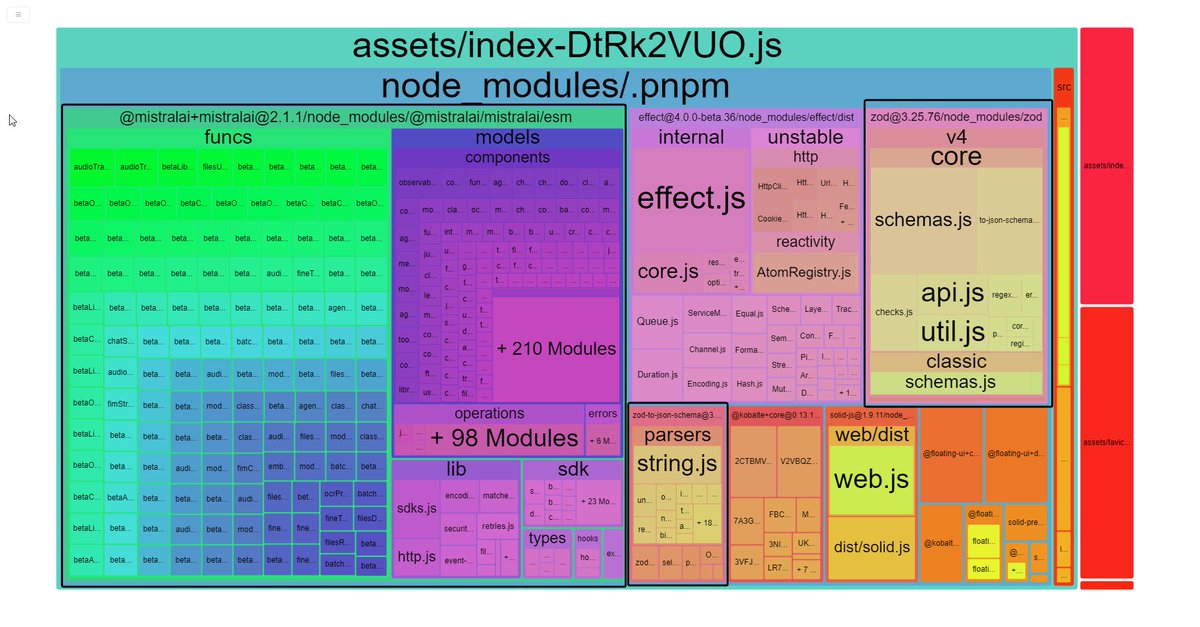
man the mistral-ai typescprit api sdk is so bad at tree shake-ability. Im literally just using 2 of the clients functions atm and its taking up 50% of my bundles real estate. Another reason to use effect if youre building libraries, makes you build in a way that makes DCE ez for bundlers.




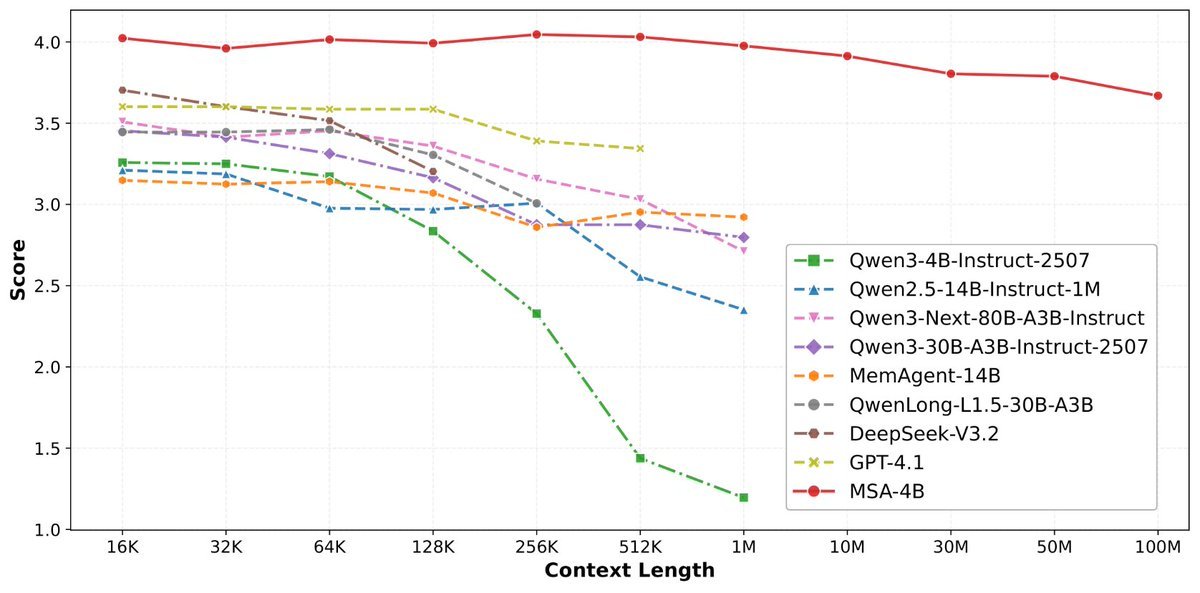
论文来了。名字叫 MSA,Memory Sparse Attention。 一句话说清楚它是什么: 让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。 过去的方案为什么不行? RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。 线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。 MSA 的思路完全不同: → 不压缩,不外挂,而是让模型学会「挑重点看」 核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。 → 模型知道「这段记忆来自哪、什么时候的」 用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。 → 碎片化的信息也能串起来推理 Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。 结果呢? · 从 16K 扩到 1 亿 token,精度衰减不到 9% · 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统 · 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。 说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。 我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏 github.com/EverMind-AI/MSA
@BryanOnel86 What’s your ARR king? We just hit $5M in 11.5 months Didn’t you guys hit that 6 months ago?


i have a phone screening interview today and im incredibly nervous. Im pasta syndrome.

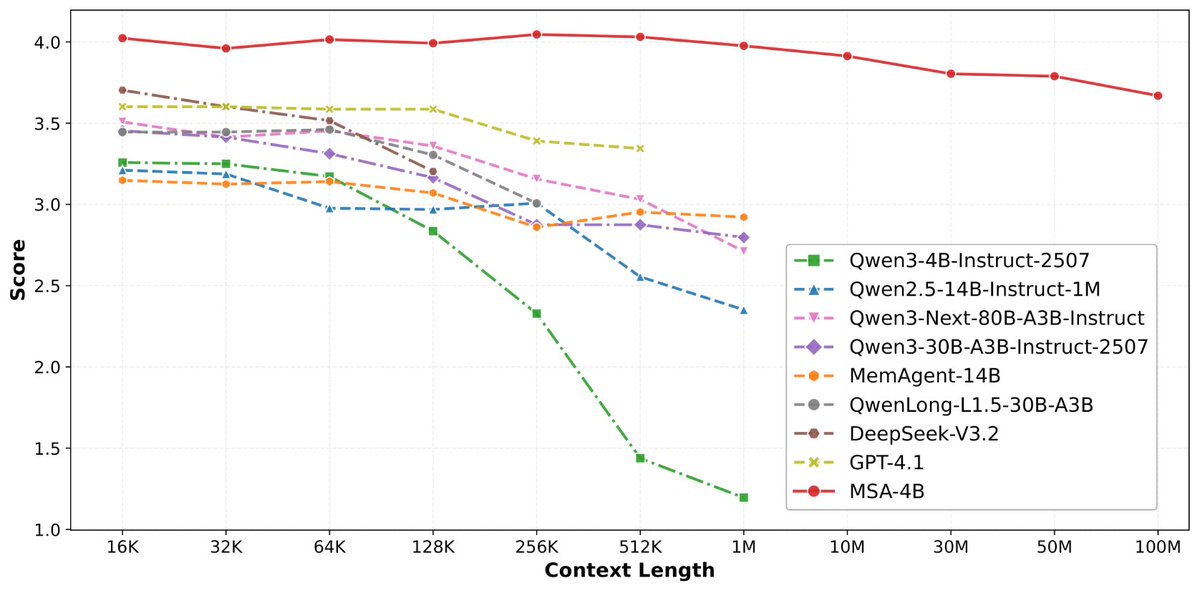
稍微剧透一下,@EverMind 这周还会发一篇高质量论文