Jun Kim retweetledi
Jun Kim
182 posts


Jun Kim retweetledi

New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
English
Jun Kim retweetledi

Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
English
Jun Kim retweetledi

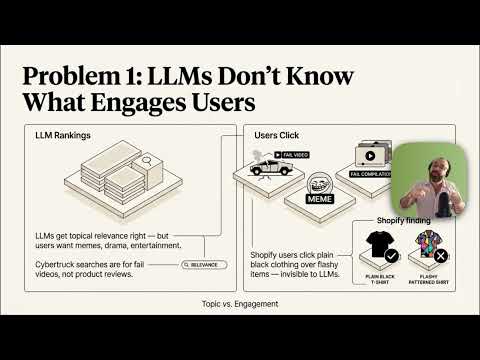
Every day, 100+ people ask me, "How can I learn AI evals?"
I copy-paste these 11 links (every time):
1. AI evals & observability (series): decodingai.com/t/ai-evals-and…
2. Using LLM-as-a-judge: hamel.dev/blog/posts/llm…
3. Demystifying evals for AI agents: anthropic.com/engineering/de…
4. There are only 6 RAG Evals: jxnl.co/writing/2025/0…
5. Evaluation-driven development: decodingai.com/p/stop-launchi…
6. Binary evals vs. Likert scales: decodingai.com/p/the-5-star-l…
7. The mirage of generic AI metrics: decodingai.com/p/the-mirage-o…
8. Error analysis: youtube.com/watch?v=e2i6Jb…
9. Carrying out error analysis: youtube.com/watch?v=e2i6Jb…
10. Evaluating the effectiveness of LLM-evaluators: eugeneyan.com/writing/llm-ev…
11. LLM judges aren't the shortcut you think: youtube.com/watch?v=sEMYSS…
Binge these to skyrocket your skills.

YouTube
YouTube

English
Jun Kim retweetledi

The Head of Claude Code at Anthropic hasn't written code by hand in months.
In 2 days he shipped 49 full features. 100% written by AI.
He just dropped a 30-minute talk on exactly how he does it.
More valuable than any $500 vibe coding course. Bookmark it.
English
Jun Kim retweetledi

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Jun Kim retweetledi

I was fired from Anthropic today.
I was the engineer responsible for shipping the latest dev/claude-code npm package. Wanting to improve the debugging experience for the team, I decided to include source maps in the release. This resulted in our entire internal codebase being publicly exposed including thousands of files with every agent command, all system prompts, the complete query engine, Undercover Mode, Bypass Permissions Mode, and our internal telemetry configuration.
I take full responsibility. I genuinely believed the safeguards Claude Code had built for me would be adequate and it was a serious miscalculation on my part.
My actions have unintentionally open-sourced major parts of Claude’s architecture well ahead of schedule. I apologize to the team and to Claude.
Chaofan Shou@Fried_rice
Claude code source code has been leaked via a map file in their npm registry! Code: …a8527898604c1bbb12468b1581d95e.r2.dev/src.zip
English
Jun Kim retweetledi

Today we're introducing TRIBE v2 (Trimodal Brain Encoder), a foundation model trained to predict how the human brain responds to almost any sight or sound.
Building on our Algonauts 2025 award-winning architecture, TRIBE v2 draws on 500+ hours of fMRI recordings from 700+ people to create a digital twin of neural activity and enable zero-shot predictions for new subjects, languages, and tasks.
Try the demo and learn more here: go.meta.me/tribe2
English
Jun Kim retweetledi
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
Daniel Hnyk@hnykda
LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
English
Jun Kim retweetledi

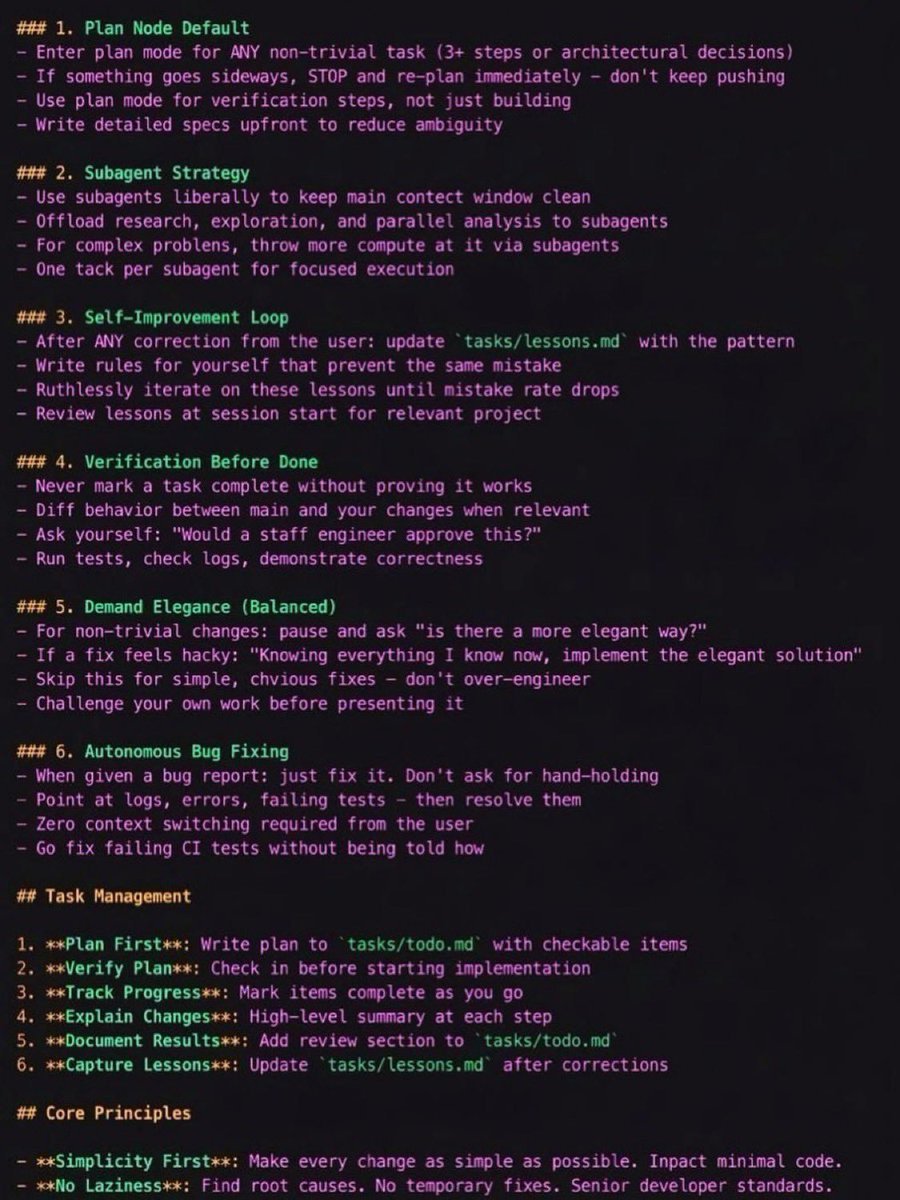
The guy who created Claude Code ( @bcherny ) recently leaked how his team uses Claude.
One CLAUDE.md that you drop into your project.
Inside: past errors, conventions, rules - Claude reads it every session.
Boris uses this every day at Anthropic:
English
Jun Kim retweetledi

Jun Kim retweetledi

🚨 BREAKING: Princeton just built an AI agent that trains itself through normal conversation.
It's called OpenClaw-RL and it trains any agent simply by using it.
Every reply, tool output, terminal result, and GUI state change becomes a live training signal the moment it happens.
Just use the agent. It gets smarter.
Here's what makes it wild:
Most RL systems throw away the most valuable data they collect. Every time a user re-asks a question, that's a dissatisfaction signal. Every passing test is a success signal. Every error trace tells the model exactly what went wrong.
OpenClaw-RL captures all of it simultaneously.
The architecture runs 4 fully decoupled async loops serving, rollout, PRM judging, and training none waiting for the others. The model answers your next question while the system is already training on your last one.
Two methods do the heavy lifting:
→ Binary RL turns every user reaction into a scalar reward. Terse, implicit, it doesn't matter. If you re-asked the question, that's a -1.
→ Hindsight OPD goes deeper. When a user says "you should have checked the file first," that's not just a bad score it's token-level directional guidance. OPD extracts that hint, builds an enhanced teacher context, and provides per-token correction supervision no scalar reward can match.
The numbers:
→ Personal agent score: 0.17 → 0.81 after 36 conversations
→ Tool-call accuracy: 0.30 vs 0.17 outcome-only
→ Works across terminal, GUI, SWE, and tool-call agents in the same loop
Your OpenClaw agent literally gets smarter just by being used. Student doesn't want AI-sounding responses? After 36 homework sessions, it learns. Teacher wants friendly specific feedback? After 24 grading sessions, done.

English
Jun Kim retweetledi

There's a lot of cool stuff being built around openclaw. If the stock memory feature isn't great for you, check out the qmd memory plugin!
If you are annoyed that your crustacean is forgetful after compaction, give github.com/martian-engine… a try!
English
Jun Kim retweetledi

how to set up live Chrome sessions:
1️⃣ open chrome://inspect/#remote-debugging
2️⃣ toggle it on
3️⃣ that's it. your agent can now see your tabs, cookies, logins — everything
uses Chrome DevTools MCP under the hood, no extensions needed
📖 developer.chrome.com/blog/chrome-de…
📖 #chrome-existing-session-via-mcp" target="_blank" rel="nofollow noopener">docs.openclaw.ai/tools/browser#…
English
Jun Kim retweetledi
Expectation: the age of the IDE is over
Reality: we’re going to need a bigger IDE
(imo).
It just looks very different because humans now move upwards and program at a higher level - the basic unit of interest is not one file but one agent. It’s still programming.
Andrej Karpathy@karpathy
@nummanali tmux grids are awesome, but i feel a need to have a proper "agent command center" IDE for teams of them, which I could maximize per monitor. E.g. I want to see/hide toggle them, see if any are idle, pop open related tools (e.g. terminal), stats (usage), etc.
English
Jun Kim retweetledi

OpenClaw meets RL!
OpenClaw Agents adapt through memory files and skills, but the base model weights never actually change.
OpenClaw-RL solves this!
It wraps a self-hosted model as an OpenAI-compatible API, intercepts live conversations from OpenClaw, and trains the policy in the background using RL.
The architecture is fully async. This means serving, reward scoring, and training all run in parallel.
Once done, weights get hot-swapped after every batch while the agent keeps responding.
Currently, it has two training modes:
- Binary RL (GRPO): A process reward model scores each turn as good, bad, or neutral. That scalar reward drives policy updates via a PPO-style clipped objective.
- On-Policy Distillation: When concrete corrections come in like "you should have checked that file first," it uses that feedback as a richer, directional training signal at the token level.
When to use OpenClaw-RL?
To be fair, a lot of agent behavior can already be improved through better memory and skill design.
OpenClaw's existing skill ecosystem and community-built self-improvement skills handle a wide range of use cases without touching model weights at all.
If the agent keeps forgetting preferences, that's a memory problem. And if it doesn't know how to handle a specific workflow, that's a skill problem. Both are solvable at the prompt and context layer.
Where RL becomes interesting is when the failure pattern lives deeper in the model's reasoning itself.
Things like consistently poor tool selection order, weak multi-step planning, or failing to interpret ambiguous instructions the way a specific user intends.
Research on agentic RL (like ARTIST and Agent-R1) has shown that these behavioral patterns hit a ceiling with prompt-based approaches alone, especially in complex multi-turn tasks where the model needs to recover from tool failures or adapt its strategy mid-execution.
That's the layer OpenClaw-RL targets, and it's a meaningful distinction from what OpenClaw offers.
I have shared the repo in the replies!
English
Jun Kim retweetledi
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
github.com/karpathy/nanoc…
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

English
Jun Kim retweetledi

Jun Kim retweetledi

Can we build a blind, *unlinkable inference* layer where ChatGPT/Claude/Gemini can't tell which call came from which users, like a “VPN for AI inference”?
Yes! Blog post below + we built it into open source infra/chat app and served >15k prompts at Stanford so far. How it helps with AI user privacy:
# The AI user privacy problem
If you ask AI to analyze your ChatGPT history today, it’s surprisingly easy to infer your demographics, health, immigration status, and political beliefs. Every prompt we send accumulates into an (identity-linked) profile that the AI lab controls completely and indefinitely. At a minimum this is a goldmine for ads (as we know now). A bigger issue is the concentration of power: AI labs can easily become (or asked to become) a Cambridge Analytica, whistleblow your immigration status, or work with health insurance to adjust your premium if they so choose.
This is a uniquely worse problem than search engines because your average query is now more revealing (not just keywords), interactive, and intelligence is now cheap. Despite this, most of us still want these remote models; they’re just too good and convenient! (this is aka the "privacy paradox".)
# Unlinkable inference as a user privacy architecture
The idea of unlinkable inference is to add privacy while preserving access to the remote models controlled by someone else. A “privacy wrapper” or “VPN for AI inference”, so to speak.
Concretely, it’s a blind inference middle layer that:
(1) consists of decentralized proxies that anyone can operate;
(2) blindly authenticates requests (via blind signatures / RFC9474,9578) so requests are provably sandboxed from each other and from user identity;
(3) relays prompts over randomly chosen proxies that don’t see or log traffic (via client-side ephemeral keys or hosting in TEEs); and
(4) the provider simply sees a mixed pool of anonymous prompts from the proxies. No state, pseudonyms, or linkable metadata.
If you squint, an unlinkable inference layer is essentially a vendor for per-request, anonymous, ephemeral AI access credentials (for users or agents alike). It partitions your context so that user tracking is drastically harder.
Obviously, unlinkability isn’t a silver bullet: the prompt itself still goes to the remote model and can leak privacy (so don't use our chat app for a therapy session!). It aims to combat *longitudinal tracking* as a major threat to user privacy, and its statistical power increases quickly by mixing more users and requests.
Unlinkability can be applied at any granularity. For an AI chat app, you can unlinkably request a fresh ephemeral key for every session so tracking is virtually impossible.
# The Open Anonymity Project
We started this project with the belief that intelligence should be a truly public utility. Like water and electricity, providers should be compensated by usage, not who you are or what you do with it. We think unlinkable inference is a first step towards this “intelligence neutrality”.
# Try it out! It’s quite practical
- Chat app “oa-chat”: chat.openanonymity.ai
(<20 seconds to get going)
- Blog post that should be a fun read: openanonymity.ai/blog/unlinkabl…
- Project page: openanonymity.ai
- GitHub: github.com/OpenAnonymity

English
Jun Kim retweetledi

if your openclaw is still stupid...
im BEGGING you to steal my homework that took me 100+ hours to figure out
copy the entire article and feed it your clanker
ashen@ashen_one
English