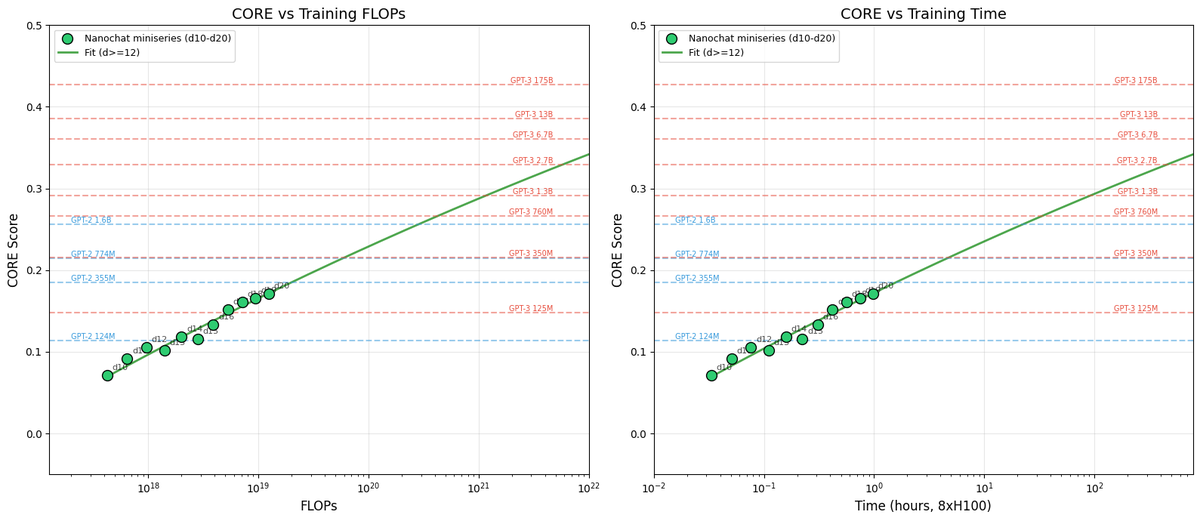
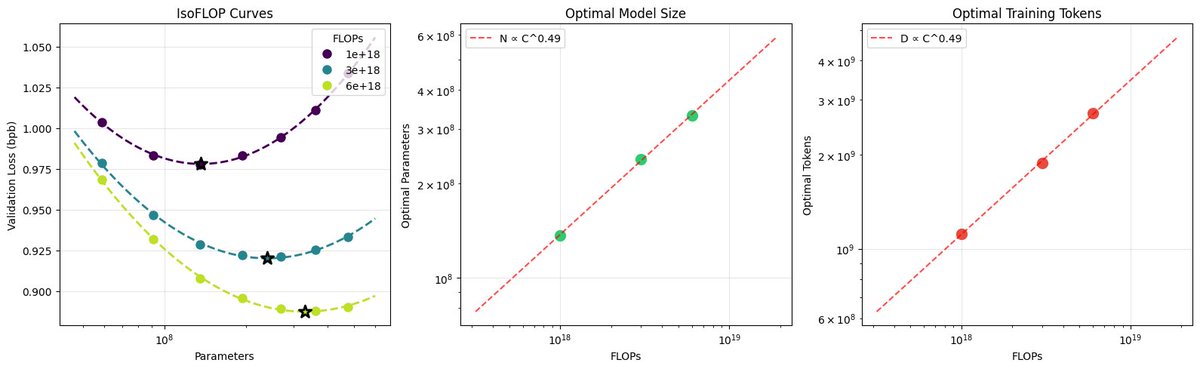
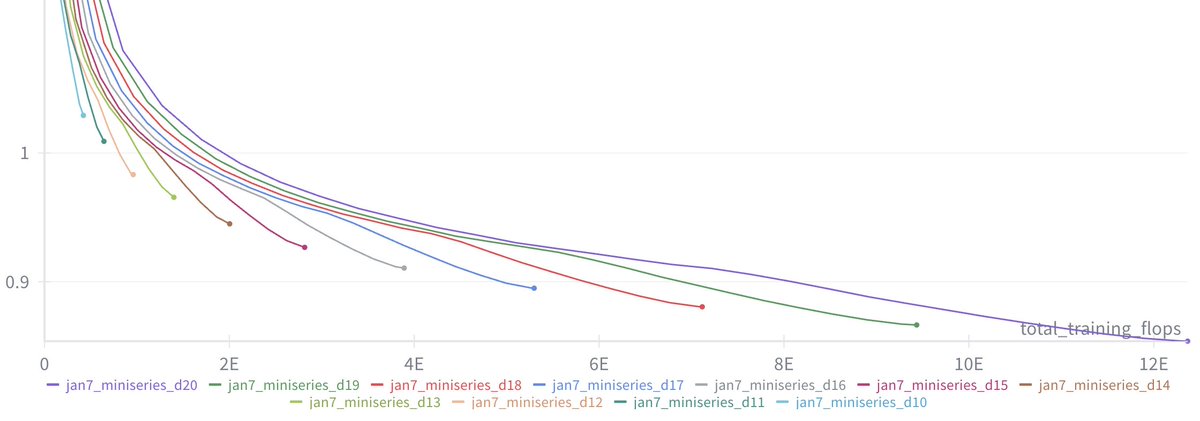
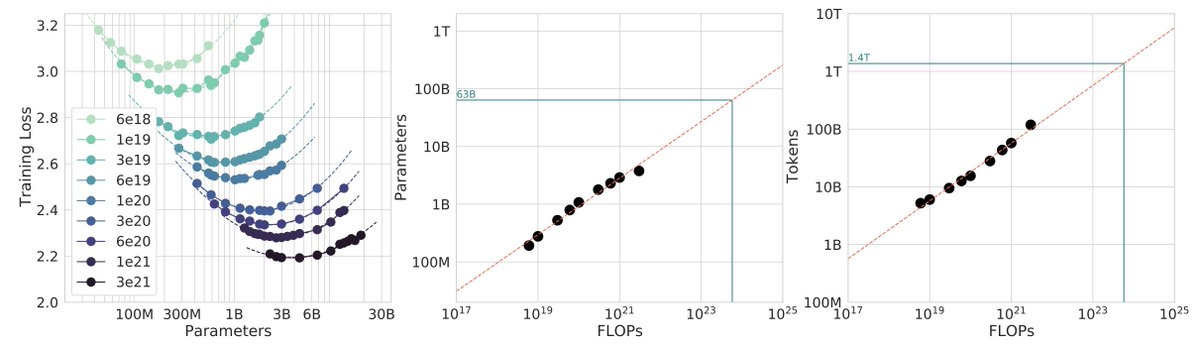
Sabitlenmiş Tweet

You have two engines: one runs on symbols (CPU), the other on vision (GPU). Use both 🔥
Symbolic reasoning is a valuable but i think Spatial reasoning is more accessible.
Mathematical ideas are still communicating in very narrow bandwidth medium and legacy static pdf/paper

English