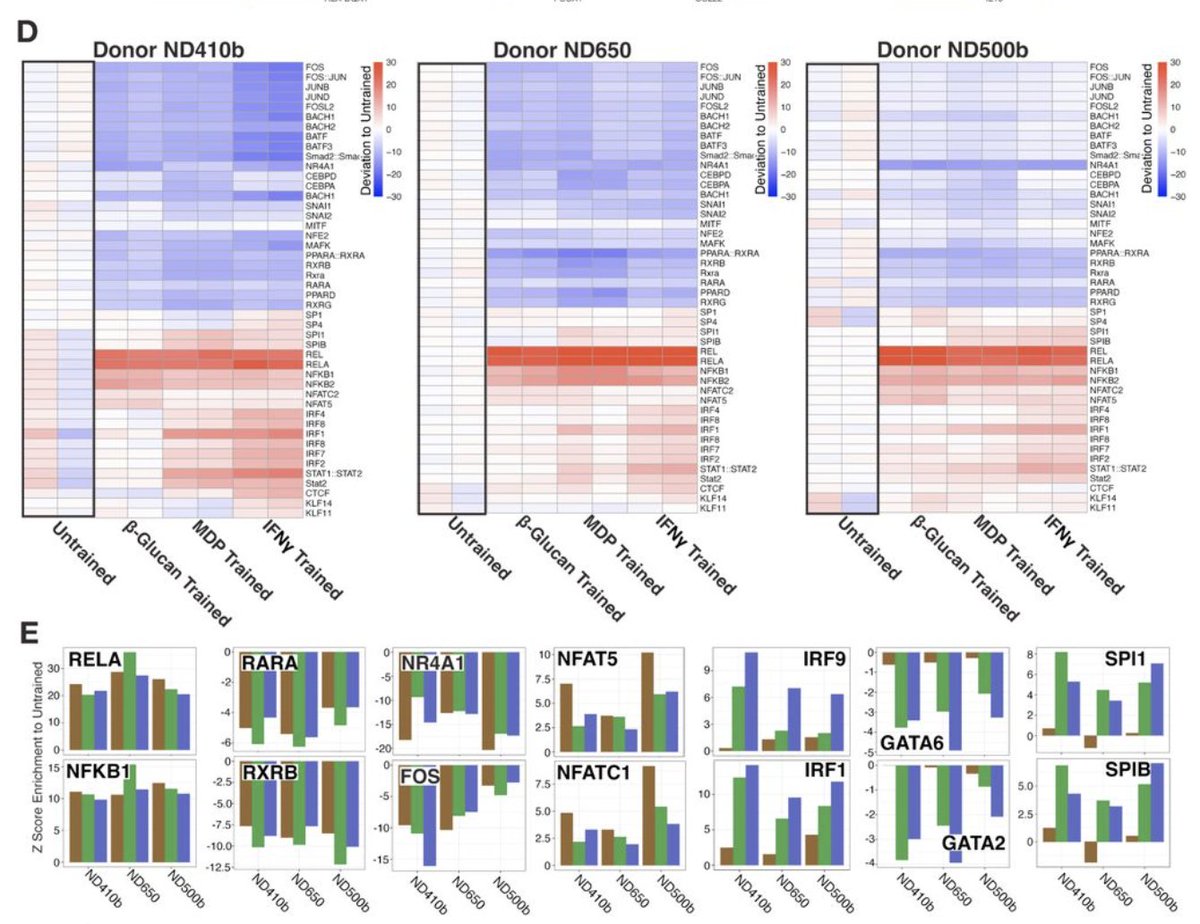
Alexander Fleming's discovery of penicillin is unlikely to have happened in the way he described. It's almost certainly a myth. For decades, scientists and historians have puzzled over inconsistencies in Fleming’s story. The window to Fleming’s lab was rarely (if ever) left open, precisely to prevent the kind of contamination that supposedly led to penicillin’s discovery. Second, the story is strikingly similar to Fleming’s earlier discovery of lysozyme, another antibacterial substance, which also featured lucky contamination from an open window. Third, Fleming claimed to have discovered the historic culture plate on September 3rd, but the first entry in his lab notebook isn’t dated until October 30th, nearly two months later. Last, and most important: penicillin only works if it’s present before the staphylococci. Fleming did not know it at the time, but penicillin interferes with bacterial cell wall synthesis, which only happens when bacteria are actively growing. Visible colonies, however, are composed mostly of mature or dead cells. By the time a colony can be seen, it is often too late for penicillin to have any effect. In fact, the Penicillium mold typically won’t even grow on a plate already filled with staphylococcus colonies. For years, scientists have attempted to replicate Fleming’s original discovery. All have met with failure. Our latest essay, by writer @kevinsblake, explains these inconsistencies and points to what likely happened instead.