Sabitlenmiş Tweet

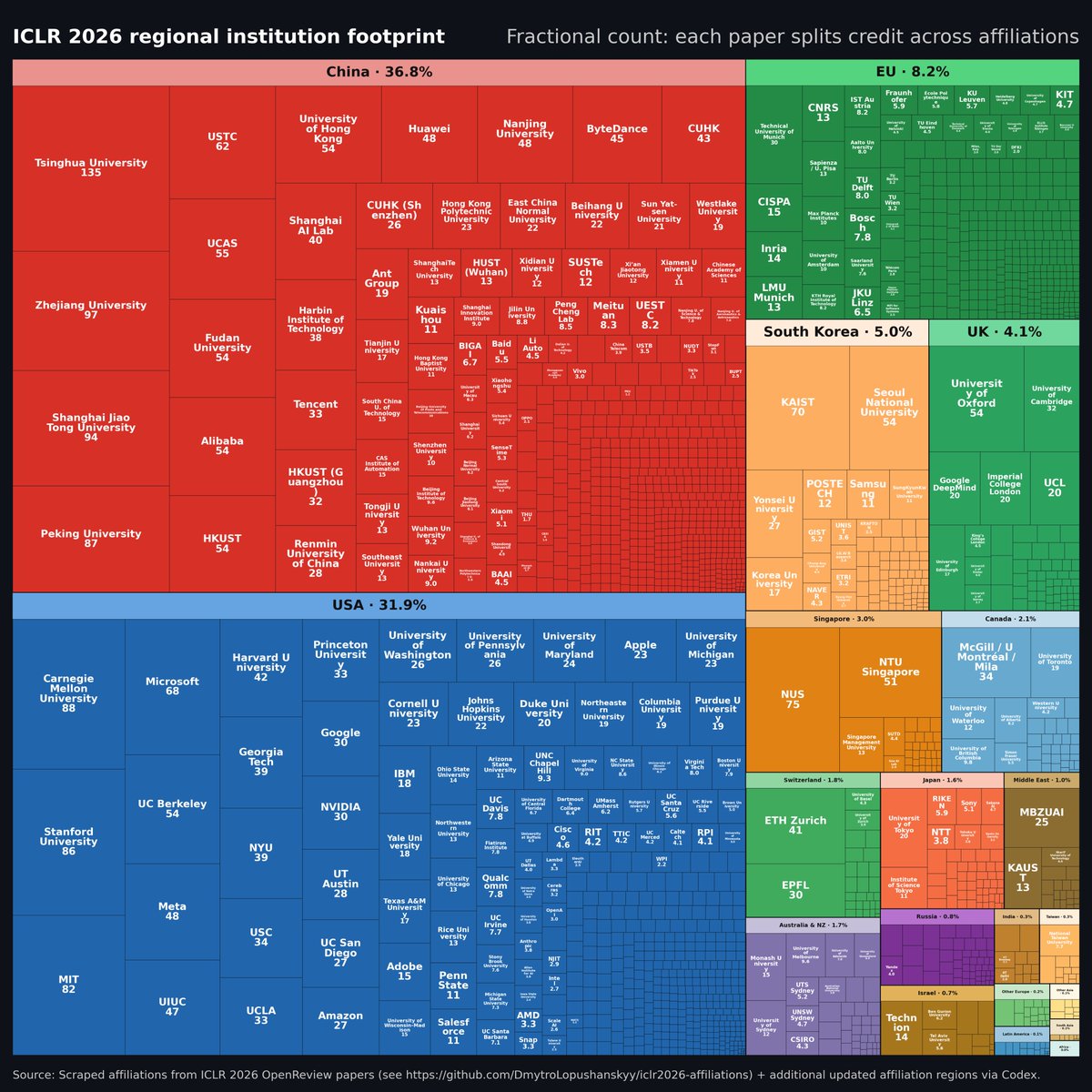
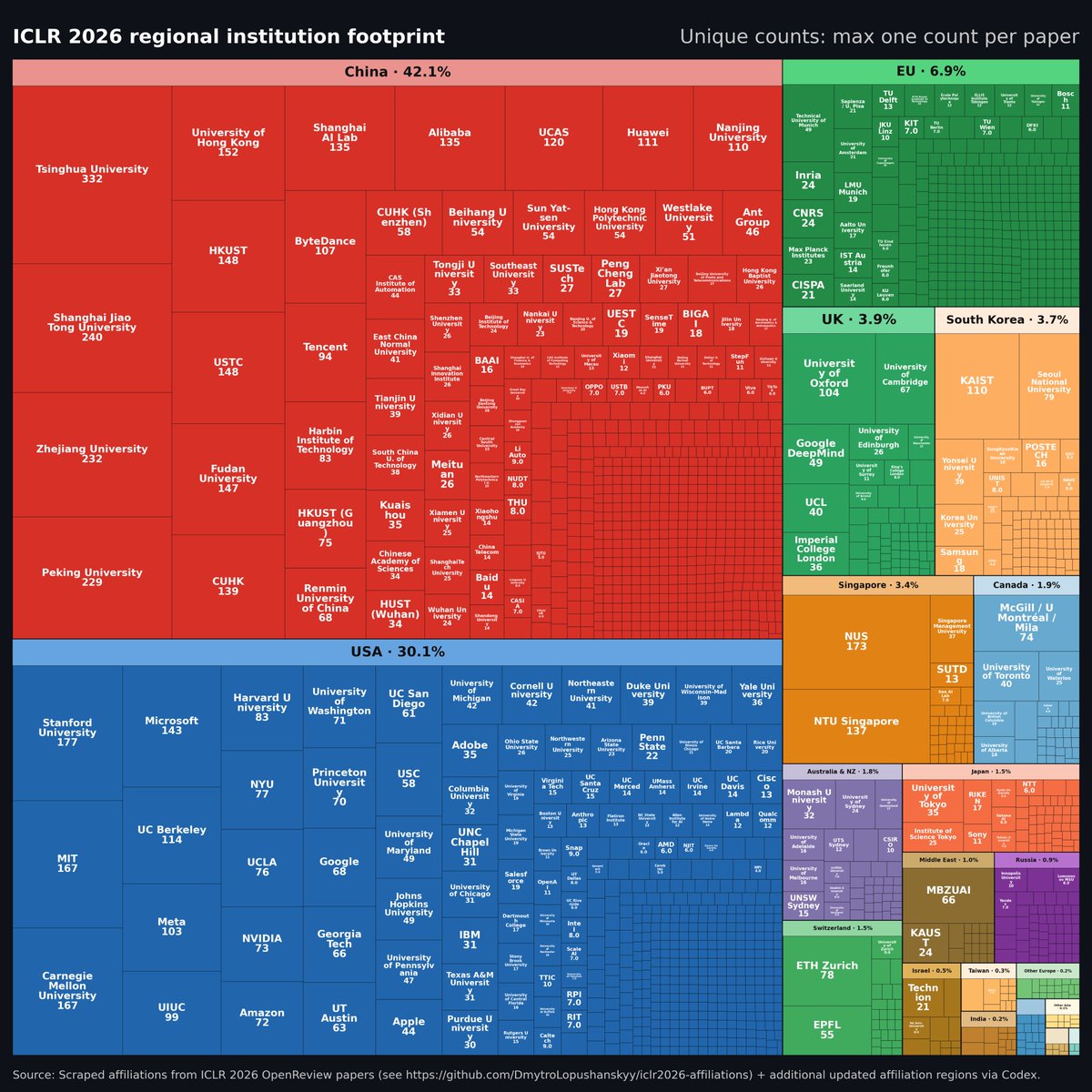
A plot of ICLR papers by country is making the rounds, showing no EU + Japan papers and people are drawing all kinds of conclusions.
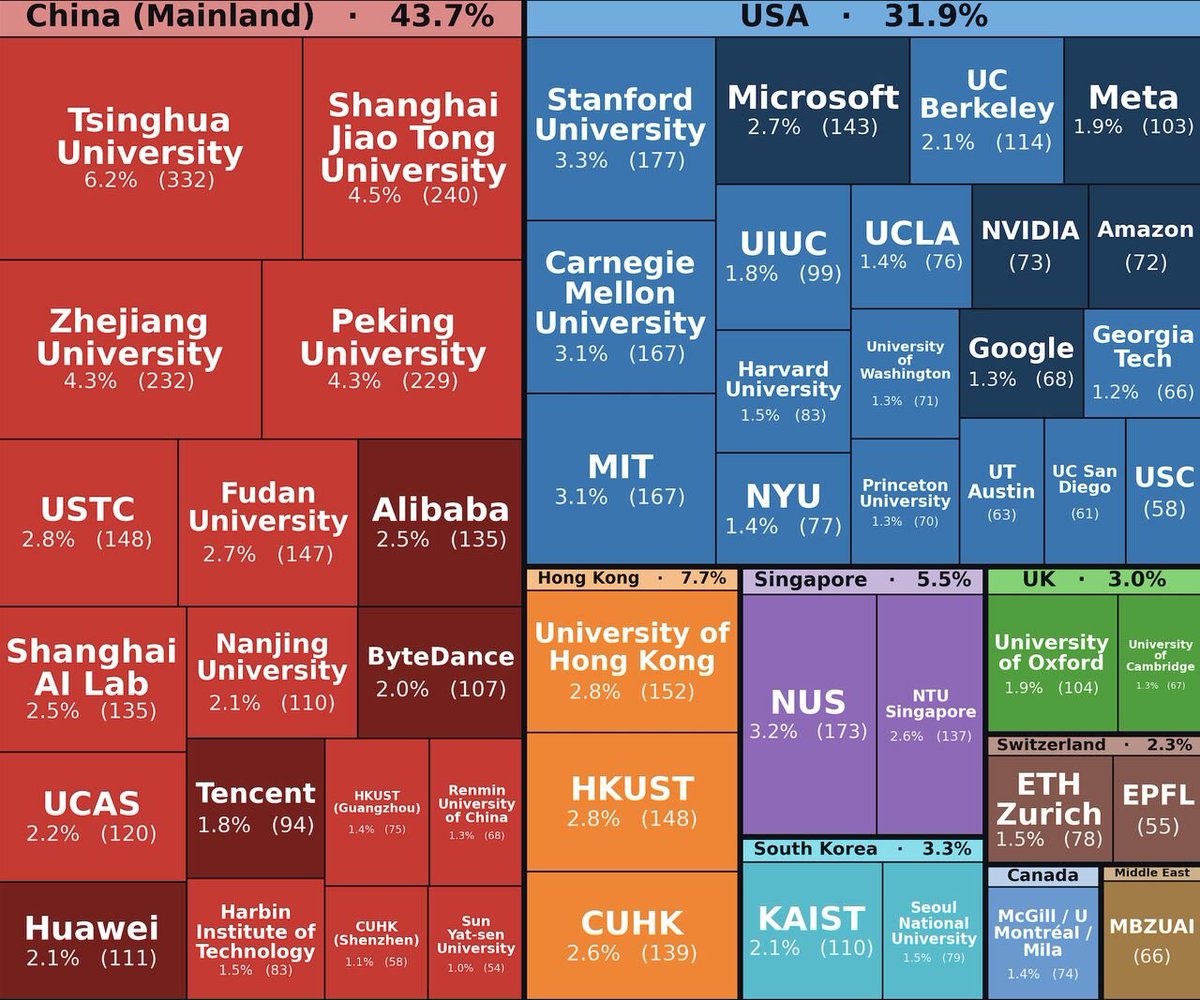
..but the plot excludes all (!) EU institutions due to a cutoff. China + USA still dominant of course but the full picture looks a bit different.

ℏεsam@Hesamation
someone analyzed all 5000+ accepted papers at ICLR 2026, and it's a good signal who's pushing the research of AI: > China has surpassed the US with 43.7% of the papers > Europe's contribution is surprisingly small (5.3% including UK)
English