Kush Varshney कुश वार्ष्णेय retweetledi

A blog on how to get frontier-level results from small language models by using Mellea and Granite Libraries do the heavy lifting: mellea.ai/blogs/small-mo…
English
Kush Varshney कुश वार्ष्णेय
8.4K posts

@krvarshney
I wrote a book. Free pdf: https://t.co/rFFL7mySnS Paperback: https://t.co/lF0IgC5T9z Tweets are my own and don't necessarily represent IBM.












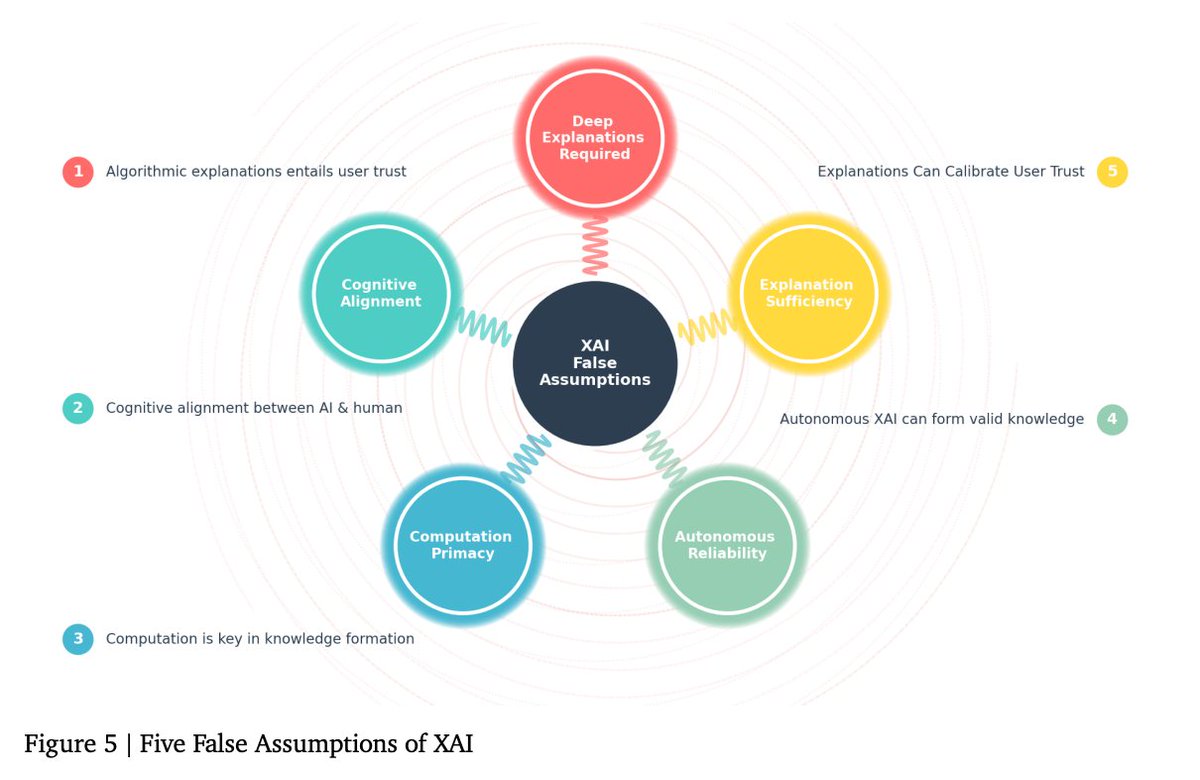


🚨 Deadline Extended to Feb 5 (AoE)! CFP still OPEN for the #AFAA2026 Workshop at @iclr_conf — on fairness across alignment & agentic AI systems. Full & tiny papers welcome • Interdisciplinary work encouraged! 🔗 afciworkshop.org #ICLR2026 #AFAA2026