kwatra
20 posts



The bitter lesson of AI infra: The hardest part about building faster LLM inference systems is not designing the systems, but rather it is evaluating if the system is actually faster! 🤔 This graph from a recent top systems venue paper about long-context serving shows average normalized input token latency for a trace with both short and 100K+ token requests. System X looks like a clear win: lower normalized latency and higher request rates. But normalized metrics can obscure the actual user experience: at those rates, long inputs see >2hr delays to the first token! Let’s do the math!🧮



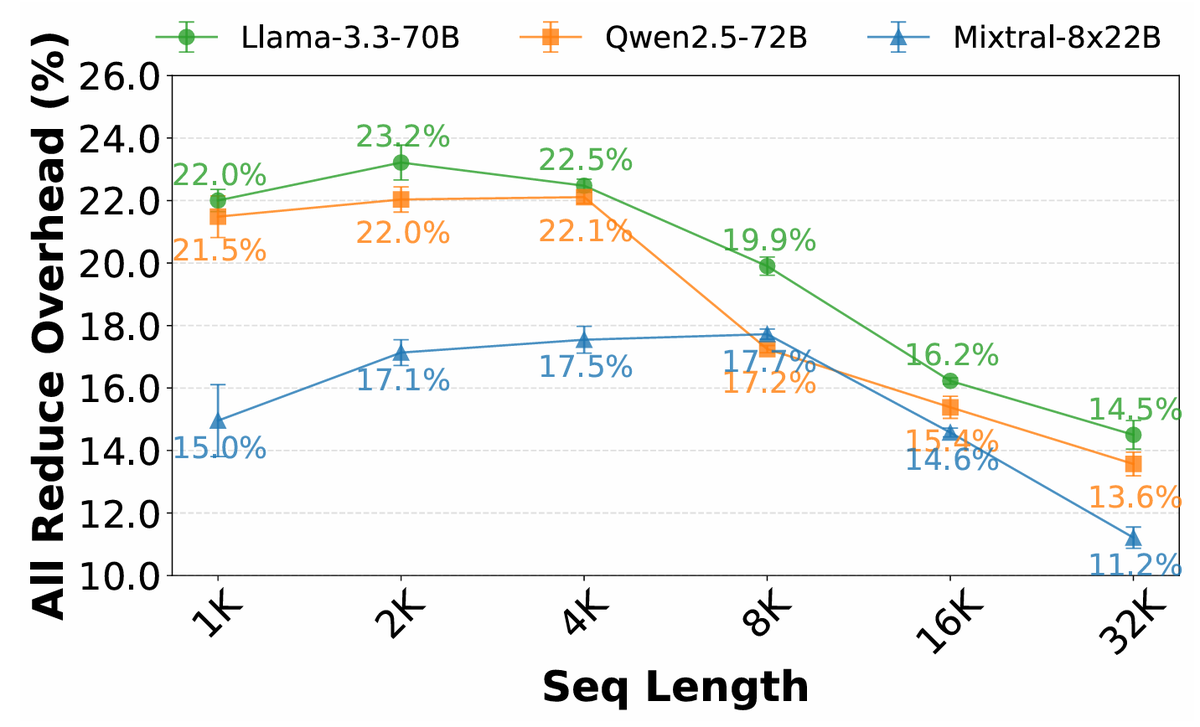
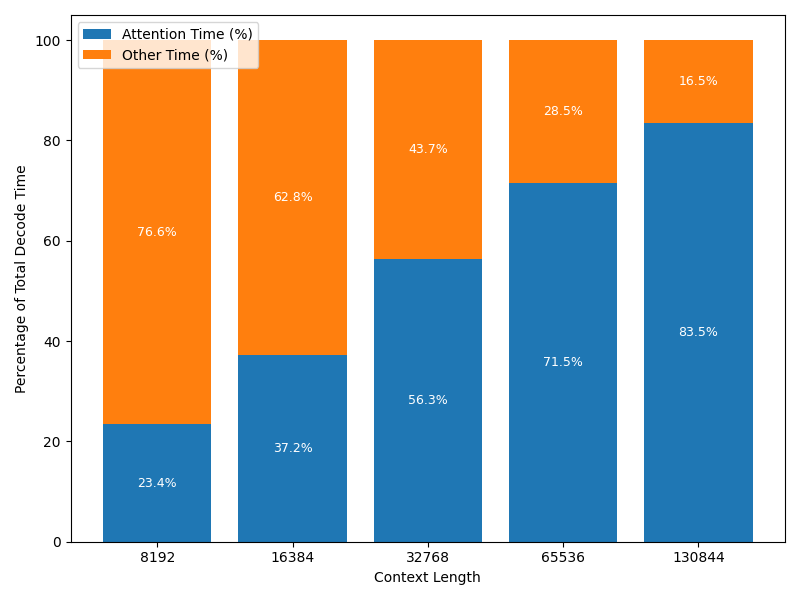
TokenWeave is the first system that almost fully hides the ~20% communication cost during inference of LLMs that are sharded in a tensor-parallel manner on H100 DGXs. Check out the thread/paper below!