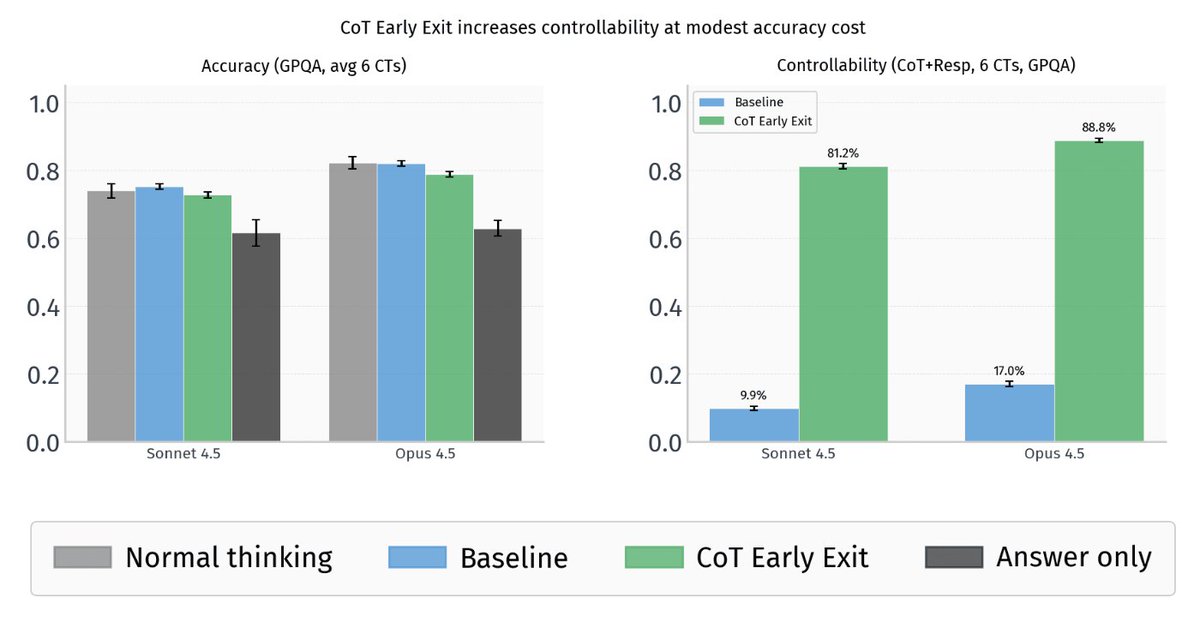
@lumpenspace @AsaCoopStick ... and that undermines the safety implications of CoT uncontrollability.
English
Elle Najt
11 posts

Safety implications: a scheming model could use this to dodge CoT monitors at modest accuracy cost. But of course we show models can be prompted to do this, not that they *would* do it autonomously.