Andy
1.4K posts


Andy
@ldehai
Old programmer, exploring a new way of life
Ottawa Katılım Ocak 2009
519 Takip Edilen245 Takipçiler


One-click browser translation extension (Manifest V3) using the free Google Translate web endpoint.
github.com/ldehai/miTrans

English

Built with Google AI Studio to visualize 25 years of Canadian population shifts and migration patterns.
canada-popinsights.pages.dev

English
Andy retweetledi

Google的前CEO Eric Schmidt说,
“如果你真想赚钱其实很简单——创办一家代理式AI公司。”
很多人每天刷Hacker News和X,看到新框架新基准就兴奋,周末熬夜试新东西,结果半年下来什么都没做出来。
直到我看到这篇两年实战经验总结的Agent生存指南,才突然明白。
这个领域最稀缺的能力并不是学习,恰恰相反,而是不学习。
很反直觉对吧,咱们先看看现在的Agent领域有多疯狂?
每天都有新的"10x"框架发布,
每周都有新的基准被打破,
连Claude Code这种顶级产品,
都公开发过47%的性能回归。
因为没有稳定的地图,没有标准答案,所有人都在摸着石头过河。
目前大多数人的策略是"跟上所有东西"。
但作者说,这恰恰是最差的策略。
他给出了一个能过滤99%噪声的万能过滤器,
任何新东西出来,先问自己这五个问题:
1. 两年后它还重要吗?
2. 有我尊敬的人在生产环境写过诚实的事后复盘吗?
3. 它是否强制我抛弃现有的 tracing/重试/认证体系?
4. 跳过它6个月会怎样?
5. 我能量化它对我的Agent的帮助吗?
最有意思的是,大多数新东西在第一关就死了。
各种wrapper、CLI工具、Devin-for-X,两年后基本都会消失,
而协议、内存模式、沙箱机制,这些才是真正能长期存在的东西,
我觉得最难的技能是学会如何不耍酷装逼,不追热点。
那到底什么东西值得学?
作者列了7个学一次,可以终身受益的复利概念:
• 上下文工程(不是提示词工程)
• 工具设计
• Orchestrator-Subagent模式
• 评估体系+黄金数据集
• 文件系统状态+思考-行动-观察循环
• MCP协议
• 沙箱作为原语
不是说这些东西永远不会变,
而是它们的变化速度,比新框架慢100倍。
比如你花一个月吃透上下文工程,未来三年都能用。
但你花一个星期学一个爆火的新框架,可能三个月后就没人维护了🤣😅
这就是复利的力量。
兄弟们来看看2026年4月最无聊的技术选型:
编排:LangGraph(生产默认)
协议:MCP(全栈首选)
可观测性+评估:Langfuse / LangSmith
运行时+沙箱:E2B、Browserbase
模型:Claude Sonnet 4.6(性价比王)
原则:模型可换,工具MCP化,沙箱必开,评估从第一天就有。
然后是坚决跳过的清单:
AutoGen、CrewAI、Semantic Kernel、DSPy
独立代码编写Agent、自主Agent pitch、Agent应用商店
水平企业平台、SWE-bench跑分、天真的并行多Agent
理由统一:demo好看,生产不行。
最后是最简单也最难的行动手册:
1. 选一个业务真正在意的可量化结果
2. 先搭 tracing + 评估 + 黄金数据集
3. 单agent循环起步,3-7个好工具足够
4. 用真实失败喂你的回归测试集
5. 失败模式驱动加复杂度
6. 每周只花30分钟读3个高质量来源
这篇文章最戳我的一句话是:
AI把"2年经验工程师的工作"压缩到了几天,
22岁的新人跟35岁的资深工程师,现在站在同一起跑线上,
胜出者不是堆栈掌握者,
而是有品味、敢出货、专注复利原语的人。
现在传统的职业路径已经崩塌了,
学位→初级→高级→主管,这条路已经走不通了。
新的路径是:做出东西,放到网上,让作品替你说话,
你都不需要学会一切AI相关的技能,
只需要学会哪些东西会复利,然后把注意力死死钉在它们上面就行了,
剩下的一切都交给时间就好了。
Rohit@rohit4verse
中文

@janus_of_DC 双刃剑,为了增加可观测性反而影响了性能。我一直觉得ZooKeeper不应该用Java写,太占内存,GC也一堆问题。Kafka就抛弃了它,自己实现了KRaft
中文


谈到诺基亚 $NOK
当年被苹果干死之后,大家觉得他们会慢慢死透,即便转型通信基站
结果不但没死
还赶上了AI和光通信,老黄一提携,过去一年3倍,上周的财报还大爆发超预期
历史的转折不可预料

Kevin Moon@moon73805
@artinmemes 诺基亚!
中文
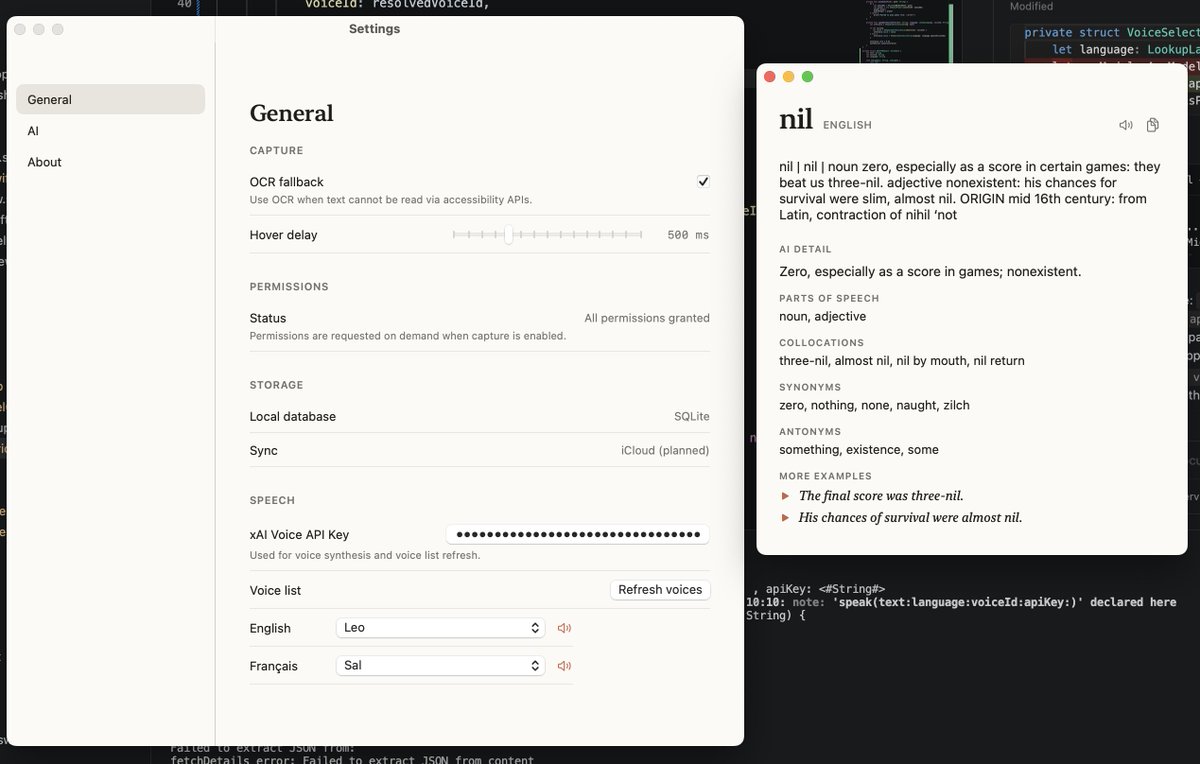
Built a small vocab tool — xAI handles the voice reading, and DeepSeek grabs the word details

xAI@xai
Introducing Grok Voice Think Fast 1.0 A state-of-the-art voice model built for complex, multi-step workflows with snappy responses and high accuracy. It takes the top spot on the Tau Voice Bench and handles real-world messiness like noise, accents, and interruptions better than any other model in the world. x.ai/news/grok-voic…
English

Cardinal 之所以搜索快,是把"文件搜索"彻底拆成了索引 + 查询两个阶段,并在每个环节都用了非常紧凑的数据结构。核心几点:
1. 启动时一次性扫盘,常驻内存索引
fswalk/ 用 Rayon par_bridge() 并行 read_dir,初次扫描 need_metadata = false,只拿 DirEntry::file_type(),避免每个文件都 stat,把 I/O 降到最低。元数据按需懒加载(doc/inner/fswalk.md:71-75)。扫出来的树灌进 search-cache/src/slab.rs 里的 ThinSlabSlabIndex 只占 32 bit,节点用 NameAndParent(指针+长度+父索引)+ StateTypeSize(state/type/size 打到一个 u64)压缩存储(doc/inner/search-cache.md:20-34)。
2. 全局字符串驻留 (NamePool)
所有 basename 走 namepool/ 的 BTreeSet> 去重,节点里只存 &'static str,几百万文件名也只占一份内存(doc/inner/name-pool.md:10-21)。
3. 倒排式 NameIndex
search-cache/src/name_index.rs:65-68: BTreeMap<&'static str, SortedSlabIndices>,每个唯一 basename 对应一组按完整路径排好序的 slab 索引。查询时不用遍历整棵文件树——先在 NamePool 里按子串/前缀/后缀/正则筛 basename,再到 NameIndex 把这些名字直接映射成 slab 索引集合。
4. 查询编译 + 集合代数
流水线见 doc/inner/search-cache.md:58-67:cardinal-syntax 解析 → optimize_query → evaluate_expr。大小写敏感的纯子串走廉价字符串比较,模糊/通配走编译后的正则;AND/OR/NOT 直接对已排好序的 SortedSlabIndices 做有序合并/交集,复杂度接近线性。parent: / infolder: 等过滤器其实就是对目标目录的子集做交集(doc/inner/search-cache.md:80-97)。
5. 增量更新而不是重扫
通过 cardinal-sdk 的 FSEvents 拿到事件 → scan_paths 合并最小覆盖路径 → scan_path_recursive 只重建变动子树,并更新 NameIndex(doc/inner/search-cache.md:108-121),保持索引始终热的。
6. 持久化避免冷启动
search-cache/src/persistent.rs:postcard 编码 + zstd 压缩 + 原子写,重启时直接从快照加载,NamePool 从 NameIndex 的 key 重建。
7. UI 端只渲染可见行
后端只返回 SlabIndex,前端 VirtualList 仅通过 get_nodes_info 拉取当前视口的行(doc/inner/project-overview.md:38-40),所以即使命中几十万结果也不会卡。
一句话概括:所有路径压成 slab + 全局 intern 的名字 + 按 basename 建倒排索引 + 在排好序的索引集合上做集合运算,再加上 FSEvents 增量维护和持久化快照,真正搜索时几乎就是几次 BTreeMap 查找加有序数组合并而已。
Vincent Logic | 信号>噪音@VincentLogic
可能是目前Mac生态里最接近Everything的开源搜索利器 发现一个解决 Mac 检索痛点的实用干货 Cardinal。 它的产品逻辑非常简单粗暴:极速。没有复杂的 UI,只有纯粹的性能输出。从截图中可以看到,面对庞大的应用依赖目录,它的反馈速度在 100 毫秒级别,彻底秒杀系统自带方案。 适合需要频繁穿梭于各类代码仓库、系统深层目录的进阶用户。 GitHub项目地址:github.com/cardisoft/card…
中文