
0
893 posts



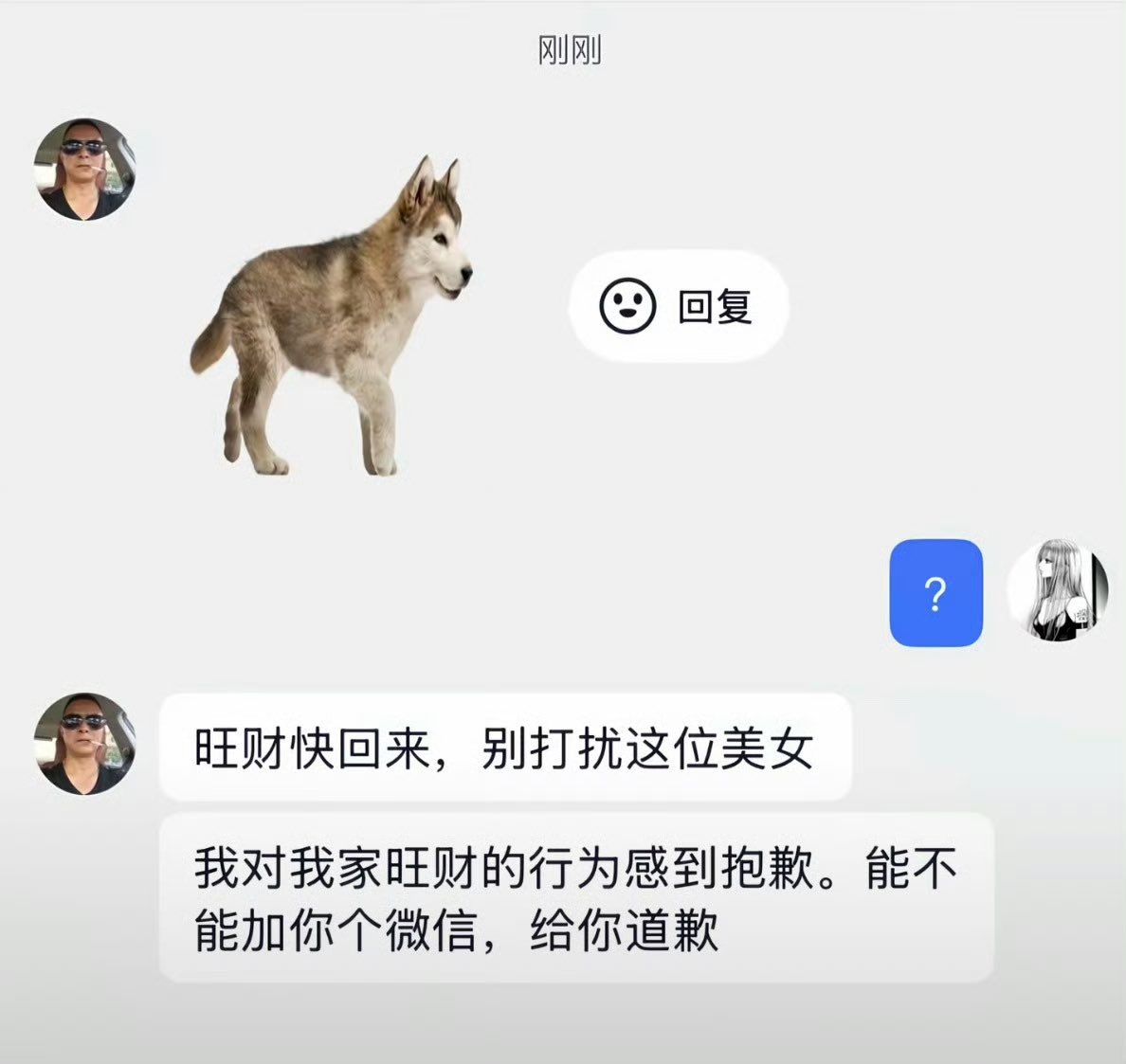
不会
这他妈画的什么狗屁玩意
先别管内容对不对这格式就不对
然后内容也不对,这玩意能跑起来我吃屎
GoFly@GoGoFly23
好有一些 GPT image 2 生成的电路原理图,AI 会把所有行业都干翻嘛
中文
0 retweetledi

0 retweetledi


0 retweetledi


0 retweetledi

深刻感知到了Vibe Coding和做产品之间的差距:
Vibe Coding 3小时,就能够搭出个70分的demo;但要再提高个20分,把demo打磨成产品,需要的时间30个小时都不止。
那20分就得要更深的know-how、更强的产品sense、更广的数据源......
中文
中文

中文
“对不起…我今天在雌竟的对决里输得一塌糊涂…沦落为了彻底的奴下奴
哈啊啊……乳头要坏掉了……屁穴被抠得要高潮了……我明明是那么多人梦寐以求的骚货……却在这里像最贱的厕所一样……被玩弄得喷水喷得停不下来。
雌竞胜利者@iihcii1
S妈妈@meiyoubianjie1
中文


0 retweetledi

deepseek V4 论文里关于 'Agent 能力' 的训练部分值得深入阅读和学习。
另外不得不赞叹的是deepseek 的工程能力还是依旧的如此扎实。包括自己设计DSL&实现DSec sandbox等等。
里面有一个很巧思的地方,DeepSeek-V4 的 post train 由两个阶段组成:先独立训练多个domain-specific experts,再通过 ODP 合并成统一模型。
下面是 V4 在 agent 能力训练上的一些思路:
1. 在 pre-train 中就注入了大量的 agentic data 来强化 agentic 能力。论文明确提到,为增强代码能力,DeepSeek-V4 在 mid-training 阶段加入了 agentic data
- 让 base model 见过更长的任务过程。
- 让模型熟悉代码、命令、环境反馈、文件修改等模式。
- 给后续 Agent SFT/RL 提供更好的初始化,而不是从纯聊天模型开始硬训工具调用。
2. 训练多个“领域专家”,后训练的第一阶段叫 Specialist Training。论文说,对数学、代码、Agent、指令跟随等目标领域,分别训练独立专家模型
3. hard-to-verify 任务用 Generative Reward Model,传统 RLHF 往往需要训练一个 scalar reward model。DeepSeek-V4 论文说,他们在后训练中不再依赖传统 scalar reward model,而是针对 hard-to-verify 任务构造 rubric-guided RL data,并使用 Generative Reward Model,GRM 来评估 policy trajectory
4. 工具调用协议重新设计为 DSML/XML,V4 引入了新的 tool-call schema,自己设计的DSL格式,减少 escaping failure 和 tool-call errors
5. Interleaved Thinking,保留工具场景下的完整思考轨迹。在 tool-calling 场景中,整个对话过程的 reasoning content 都完整保留,包括跨 user message 边界。
6. Reasoning Effort 分模式训练,Agent 任务不是都需要最大推理。简单工具选择用 Non-think 更快;软件工程、搜索、长文档任务则可以用 High/Max,在成本和成功率之间权衡。
7. Quick Instruction 降低 Agent 前置决策成本
8. 最终用 OPD (multi-teacher On-Policy Distillation)把多个专家合并成统一模型
9. DSec:production-grade 沙箱支撑,V4为 Agentic AI post-training 和 evaluation 建的生产级沙盒平台,它运行在 3FS 分布式文件系统上,可以管理数十万并发 sandbox instances
10. RL/OPD rollout 也专门为长 Agent 轨迹优化
11. 构造自己的 Agent benchmark 集,构造了一个内部 R&D coding benchmark:从 50+ 内部工程师收集约 200 个真实任务,涵盖 feature development、bug fixing、refactoring、diagnostics,技术栈包括 PyTorch、CUDA、Rust、C++ 等。经过过滤后保留 30 个任务作为评测集


中文
0 retweetledi




English
0 retweetledi


0 retweetledi


0 retweetledi

0 retweetledi
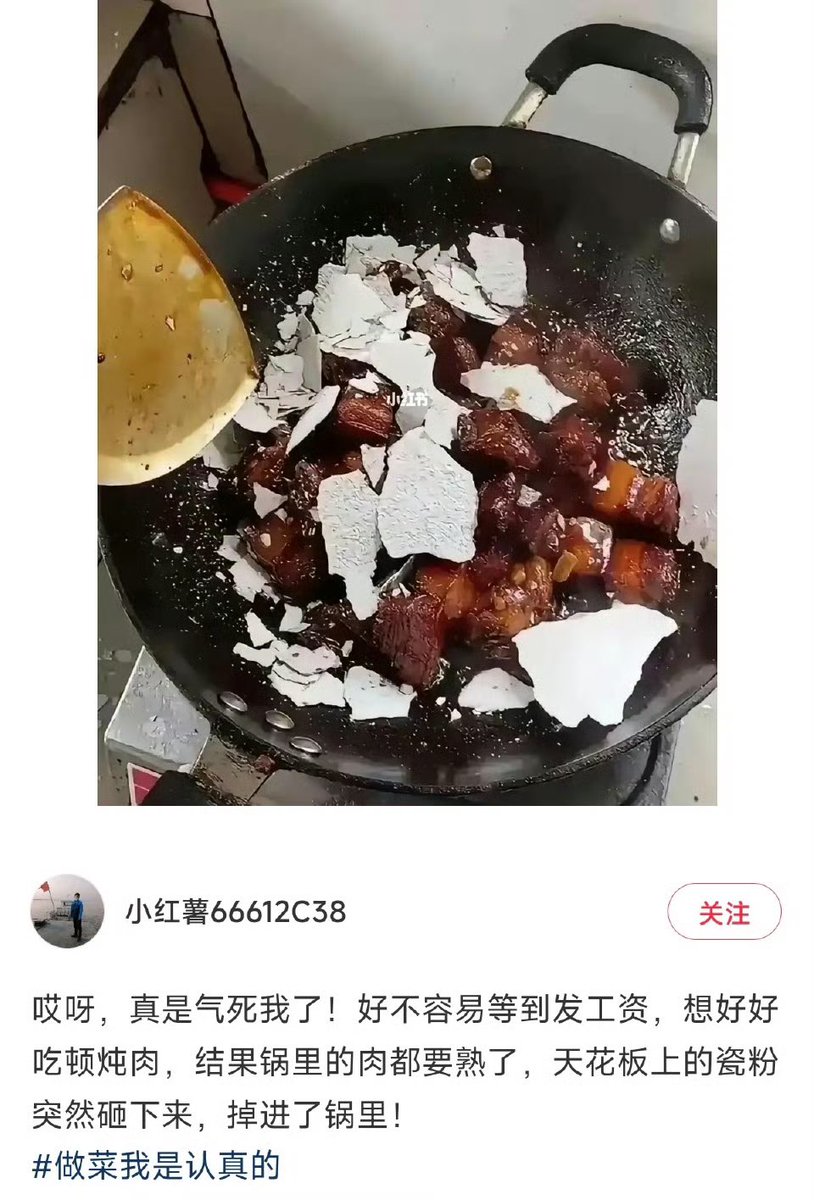
0 retweetledi









0 retweetledi

